 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
The four-fifths rule is not disparate impact: a woeful tale of epistemic trespassing in algorithmic fairness
Feb 19, 2022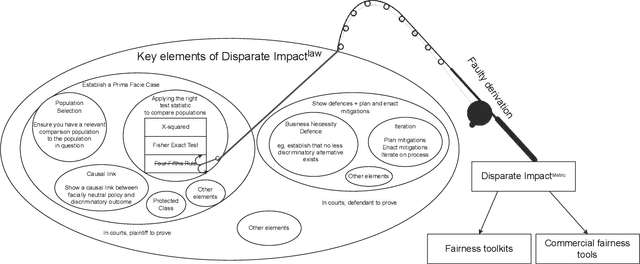
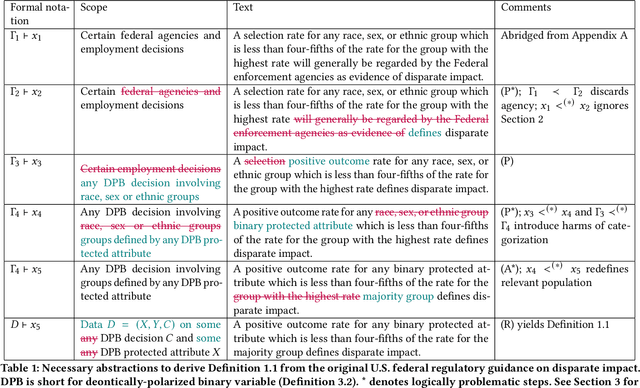
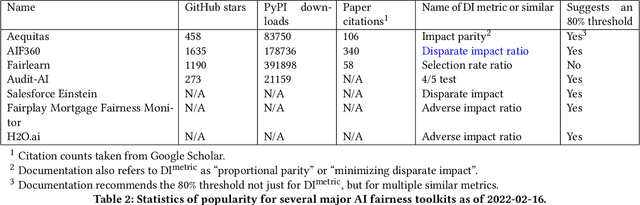
Computer scientists are trained to create abstractions that simplify and generalize. However, a premature abstraction that omits crucial contextual details creates the risk of epistemic trespassing, by falsely asserting its relevance into other contexts. We study how the field of responsible AI has created an imperfect synecdoche by abstracting the four-fifths rule (a.k.a. the 4/5 rule or 80% rule), a single part of disparate impact discrimination law, into the disparate impact metric. This metric incorrectly introduces a new deontic nuance and new potentials for ethical harms that were absent in the original 4/5 rule. We also survey how the field has amplified the potential for harm in codifying the 4/5 rule into popular AI fairness software toolkits. The harmful erasure of legal nuances is a wake-up call for computer scientists to self-critically re-evaluate the abstractions they create and use, particularly in the interdisciplinary field of AI ethics.