 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 Challenge on Real-World All-in-One Image Restoration: Methods and Results
Apr 21, 2026This paper presents a review for the LoViF Challenge on Real-World All-in-One Image Restoration. The challenge aimed to advance research on real-world all-in-one image restoration under diverse real-world degradation conditions, including blur, low-light, haze, rain, and snow. It provided a unified benchmark to evaluate the robustness and generalization ability of restoration models across multiple degradation categories within a common framework. The competition attracted 124 registered participants and received 9 valid final submissions with corresponding fact sheets, significantly contributing to the progress of real-world all-in-one image restoration. This report provides a detailed analysis of the submitted methods and corresponding results, emphasizing recent progress in unified real-world image restoration. The analysis highlights effective approaches and establishes a benchmark for future research in real-world low-level vision.
Evolving Jailbreaks: Automated Multi-Objective Long-Tail Attacks on Large Language Models
Mar 20, 2026Large Language Models (LLMs) have been widely deployed, especially through free Web-based applications that expose them to diverse user-generated inputs, including those from long-tail distributions such as low-resource languages and encrypted private data. This open-ended exposure increases the risk of jailbreak attacks that undermine model safety alignment. While recent studies have shown that leveraging long-tail distributions can facilitate such jailbreaks, existing approaches largely rely on handcrafted rules, limiting the systematic evaluation of these security and privacy vulnerabilities. In this work, we present EvoJail, an automated framework for discovering long-tail distribution attacks via multi-objective evolutionary search. EvoJail formulates long-tail attack prompt generation as a multi-objective optimization problem that jointly maximizes attack effectiveness and minimizes output perplexity, and introduces a semantic-algorithmic solution representation to capture both high-level semantic intent and low-level structural transformations of encryption-decryption logic. Building upon this representation, EvoJail integrates LLM-assisted operators into a multi-objective evolutionary framework, enabling adaptive and semantically informed mutation and crossover for efficiently exploring a highly structured and open-ended search space. Extensive experiments demonstrate that EvoJail consistently discovers diverse and effective long-tail jailbreak strategies, achieving competitive performance with existing methods in both individual and ensemble level.
PRiSM: Benchmarking Phone Realization in Speech Models
Jan 20, 2026Phone recognition (PR) serves as the atomic interface for language-agnostic modeling for cross-lingual speech processing and phonetic analysis. Despite prolonged efforts in developing PR systems, current evaluations only measure surface-level transcription accuracy. We introduce PRiSM, the first open-source benchmark designed to expose blind spots in phonetic perception through intrinsic and extrinsic evaluation of PR systems. PRiSM standardizes transcription-based evaluation and assesses downstream utility in clinical, educational, and multilingual settings with transcription and representation probes. We find that diverse language exposure during training is key to PR performance, encoder-CTC models are the most stable, and specialized PR models still outperform Large Audio Language Models. PRiSM releases code, recipes, and datasets to move the field toward multilingual speech models with robust phonetic ability: https://github.com/changelinglab/prism.
Towards High-Consistency Embodied World Model with Multi-View Trajectory Videos
Nov 19, 2025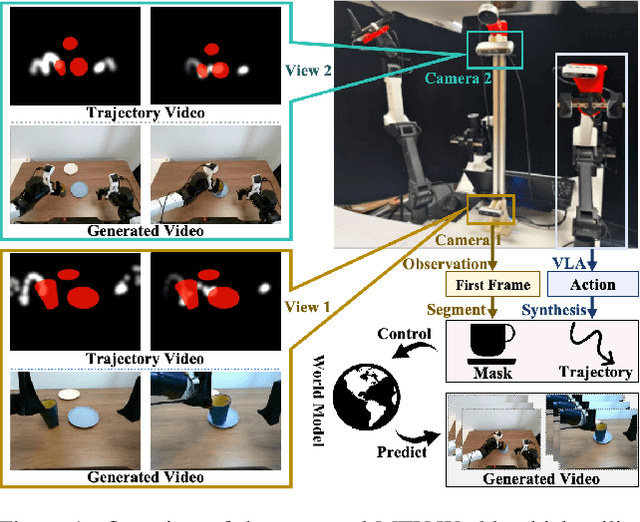

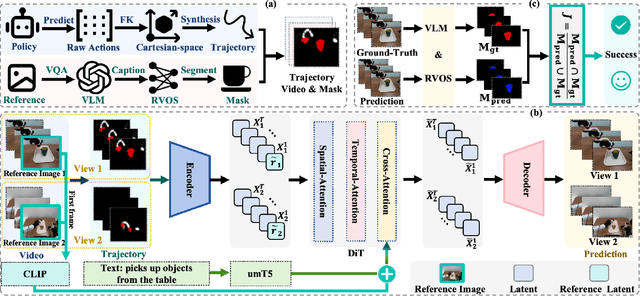
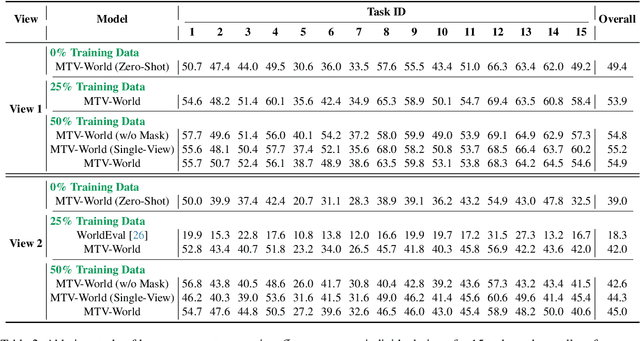
Embodied world models aim to predict and interact with the physical world through visual observations and actions. However, existing models struggle to accurately translate low-level actions (e.g., joint positions) into precise robotic movements in predicted frames, leading to inconsistencies with real-world physical interactions. To address these limitations, we propose MTV-World, an embodied world model that introduces Multi-view Trajectory-Video control for precise visuomotor prediction. Specifically, instead of directly using low-level actions for control, we employ trajectory videos obtained through camera intrinsic and extrinsic parameters and Cartesian-space transformation as control signals. However, projecting 3D raw actions onto 2D images inevitably causes a loss of spatial information, making a single view insufficient for accurate interaction modeling. To overcome this, we introduce a multi-view framework that compensates for spatial information loss and ensures high-consistency with physical world. MTV-World forecasts future frames based on multi-view trajectory videos as input and conditioning on an initial frame per view. Furthermore, to systematically evaluate both robotic motion precision and object interaction accuracy, we develop an auto-evaluation pipeline leveraging multimodal large models and referring video object segmentation models. To measure spatial consistency, we formulate it as an object location matching problem and adopt the Jaccard Index as the evaluation metric. Extensive experiments demonstrate that MTV-World achieves precise control execution and accurate physical interaction modeling in complex dual-arm scenarios.
Boomda: Balanced Multi-objective Optimization for Multimodal Domain Adaptation
Nov 11, 2025Multimodal learning, while contributing to numerous success stories across various fields, faces the challenge of prohibitively expensive manual annotation. To address the scarcity of annotated data, a popular solution is unsupervised domain adaptation, which has been extensively studied in unimodal settings yet remains less explored in multimodal settings. In this paper, we investigate heterogeneous multimodal domain adaptation, where the primary challenge is the varying domain shifts of different modalities from the source to the target domain. We first introduce the information bottleneck method to learn representations for each modality independently, and then match the source and target domains in the representation space with correlation alignment. To balance the domain alignment of all modalities, we formulate the problem as a multi-objective task, aiming for a Pareto optimal solution. By exploiting the properties specific to our model, the problem can be simplified to a quadratic programming problem. Further approximation yields a closed-form solution, leading to an efficient modality-balanced multimodal domain adaptation algorithm. The proposed method features \textbf{B}alanced multi-\textbf{o}bjective \textbf{o}ptimization for \textbf{m}ultimodal \textbf{d}omain \textbf{a}daptation, termed \textbf{Boomda}. Extensive empirical results showcase the effectiveness of the proposed approach and demonstrate that Boomda outperforms the competing schemes. The code is is available at: https://github.com/sunjunaimer/Boomda.git.
MoEGCL: Mixture of Ego-Graphs Contrastive Representation Learning for Multi-View Clustering
Nov 08, 2025



In recent years, the advancement of Graph Neural Networks (GNNs) has significantly propelled progress in Multi-View Clustering (MVC). However, existing methods face the problem of coarse-grained graph fusion. Specifically, current approaches typically generate a separate graph structure for each view and then perform weighted fusion of graph structures at the view level, which is a relatively rough strategy. To address this limitation, we present a novel Mixture of Ego-Graphs Contrastive Representation Learning (MoEGCL). It mainly consists of two modules. In particular, we propose an innovative Mixture of Ego-Graphs Fusion (MoEGF), which constructs ego graphs and utilizes a Mixture-of-Experts network to implement fine-grained fusion of ego graphs at the sample level, rather than the conventional view-level fusion. Additionally, we present the Ego Graph Contrastive Learning (EGCL) module to align the fused representation with the view-specific representation. The EGCL module enhances the representation similarity of samples from the same cluster, not merely from the same sample, further boosting fine-grained graph representation. Extensive experiments demonstrate that MoEGCL achieves state-of-the-art results in deep multi-view clustering tasks. The source code is publicly available at https://github.com/HackerHyper/MoEGCL.
Understanding In-Context Learning Beyond Transformers: An Investigation of State Space and Hybrid Architectures
Oct 27, 2025We perform in-depth evaluations of in-context learning (ICL) on state-of-the-art transformer, state-space, and hybrid large language models over two categories of knowledge-based ICL tasks. Using a combination of behavioral probing and intervention-based methods, we have discovered that, while LLMs of different architectures can behave similarly in task performance, their internals could remain different. We discover that function vectors (FVs) responsible for ICL are primarily located in the self-attention and Mamba layers, and speculate that Mamba2 uses a different mechanism from FVs to perform ICL. FVs are more important for ICL involving parametric knowledge retrieval, but not for contextual knowledge understanding. Our work contributes to a more nuanced understanding across architectures and task types. Methodologically, our approach also highlights the importance of combining both behavioural and mechanistic analyses to investigate LLM capabilities.
ACPO: Adaptive Curriculum Policy Optimization for Aligning Vision-Language Models in Complex Reasoning
Oct 01, 2025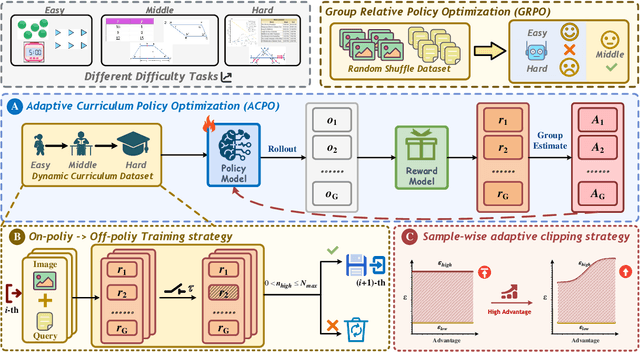


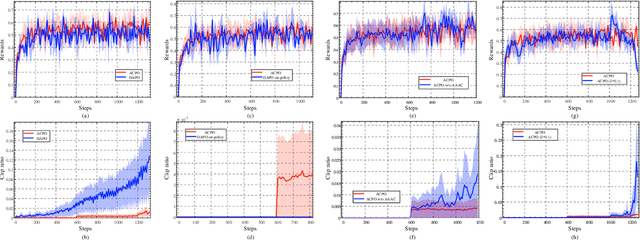
Aligning large-scale vision-language models (VLMs) for complex reasoning via reinforcement learning is often hampered by the limitations of existing policy optimization algorithms, such as static training schedules and the rigid, uniform clipping mechanism in Proximal Policy Optimization (PPO). In this work, we introduce Adaptive Curriculum Policy Optimization (ACPO), a novel framework that addresses these challenges through a dual-component adaptive learning strategy. First, ACPO employs a dynamic curriculum that orchestrates a principled transition from a stable, near on-policy exploration phase to an efficient, off-policy exploitation phase by progressively increasing sample reuse. Second, we propose an Advantage-Aware Adaptive Clipping (AAAC) mechanism that replaces the fixed clipping hyperparameter with dynamic, sample-wise bounds modulated by the normalized advantage of each token. This allows for more granular and robust policy updates, enabling larger gradients for high-potential samples while safeguarding against destructive ones. We conduct extensive experiments on a suite of challenging multimodal reasoning benchmarks, including MathVista, LogicVista, and MMMU-Pro. Results demonstrate that ACPO consistently outperforms strong baselines such as DAPO and PAPO, achieving state-of-the-art performance, accelerated convergence, and superior training stability.
Generative Diffusion Contrastive Network for Multi-View Clustering
Sep 11, 2025In recent years, Multi-View Clustering (MVC) has been significantly advanced under the influence of deep learning. By integrating heterogeneous data from multiple views, MVC enhances clustering analysis, making multi-view fusion critical to clustering performance. However, there is a problem of low-quality data in multi-view fusion. This problem primarily arises from two reasons: 1) Certain views are contaminated by noisy data. 2) Some views suffer from missing data. This paper proposes a novel Stochastic Generative Diffusion Fusion (SGDF) method to address this problem. SGDF leverages a multiple generative mechanism for the multi-view feature of each sample. It is robust to low-quality data. Building on SGDF, we further present the Generative Diffusion Contrastive Network (GDCN). Extensive experiments show that GDCN achieves the state-of-the-art results in deep MVC tasks. The source code is publicly available at https://github.com/HackerHyper/GDCN.
CTA-Flux: Integrating Chinese Cultural Semantics into High-Quality English Text-to-Image Communities
Aug 20, 2025We proposed the Chinese Text Adapter-Flux (CTA-Flux). An adaptation method fits the Chinese text inputs to Flux, a powerful text-to-image (TTI) generative model initially trained on the English corpus. Despite the notable image generation ability conditioned on English text inputs, Flux performs poorly when processing non-English prompts, particularly due to linguistic and cultural biases inherent in predominantly English-centric training datasets. Existing approaches, such as translating non-English prompts into English or finetuning models for bilingual mappings, inadequately address culturally specific semantics, compromising image authenticity and quality. To address this issue, we introduce a novel method to bridge Chinese semantic understanding with compatibility in English-centric TTI model communities. Existing approaches relying on ControlNet-like architectures typically require a massive parameter scale and lack direct control over Chinese semantics. In comparison, CTA-flux leverages MultiModal Diffusion Transformer (MMDiT) to control the Flux backbone directly, significantly reducing the number of parameters while enhancing the model's understanding of Chinese semantics. This integration significantly improves the generation quality and cultural authenticity without extensive retraining of the entire model, thus maintaining compatibility with existing text-to-image plugins such as LoRA, IP-Adapter, and ControlNet. Empirical evaluations demonstrate that CTA-flux supports Chinese and English prompts and achieves superior image generation quality, visual realism, and faithful depiction of Chinese semantics.