 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecover, Discover, Plan: Learning Skills and Concepts from Robot Failures
Jun 16, 2026Intelligent robots should not only recover from failures, but also acquire the abstract knowledge needed to avoid them in the future. While reinforcement learning (RL) can learn reactive recovery behaviors, training a separate policy for every distinct failure mode is highly inefficient. We introduce Recovery-Driven Synthesis of Relational Concepts (ReSYNC), the first approach that progressively discovers and refines state abstractions (relational predicates) from failure-recovery experience to support abstract planning. Unlike purely reactive methods, ReSYNC jointly learns skills and concepts through an incremental dual-learning process. In the skill-learning phase, the robot uses RL to learn to recover from failures seen in training tasks. In the concept-learning phase, the robot discovers new relational predicates and refines its abstract planning model to explain and generalize the learned recovery behaviors. This interaction enables ReSYNC to convert local recoveries seen during training into global failure avoidance at test time. Across four simulated domains, we show that ReSYNC's ability to continually expand and refine its abstraction library allows it to solve long-horizon, previously unseen problems, outperforming strong baselines by over 50%. Additionally, we demonstrate sim-to-real transfer of ReSYNC, where it performs real-world non-prehensile manipulation skills and generalizes to unseen scenarios through abstract planning. Overall, ReSYNC represents a significant step toward robots that autonomously acquire abstractions for scalable, failure-aware planning in the physical world.
Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
Jun 15, 2026Hybrid linear attention models offer an appealing path to faster long-context inference: they reduce the quadratic cost and KV-cache burden of full softmax attention while retaining much of the quality of Transformer models. A practical way to obtain such models is to convert a pretrained Transformer instead of pretraining a new architecture from scratch, but this conversion is still brittle. Simply copying the teacher attention projections into a Gated DeltaNet (GDN) student does not specify the new recurrent decay, write, and output-gating dynamics. As a result, the converted model often starts in a poor dynamical regime and must spend many distillation tokens repairing initialization rather than learning the remaining teacher behavior. We propose Taylor-Calibrate, a lightweight initialization method for hybrid GDN students. The method uses Taylor-guided teacher attention statistics to set the value projection, memory timescale, write gates, and output gate, then applies a short per-layer alignment step to match each converted layer to the teacher output. Across four teacher settings and three retained-layer policies, Taylor-Calibrate gives substantially stronger zero-shot students, with up to an 88x improvement in a representative ablation, and reaches matched recovery targets with 4.9x--9.2x fewer training tokens than naive conversion.
Description and Discussion on DCASE 2026 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Apr 01, 2026This paper presents an overview of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2026 Challenge Task 4, Spatial Semantic Segmentation of Sound Scenes (S5). The S5 task focuses on the joint detection and separation of sound events in complex spatial audio mixtures, contributing to the foundation of immersive communication. First introduced in DCASE 2025, the S5 task continues in DCASE 2026 Task 4 with key changes to better reflect real-world conditions, including allowing mixtures to contain multiple sources of the same class and to contain no target sources. In this paper, we describe task setting, along with the corresponding updates to the evaluation metrics and dataset. The experimental results of the submitted systems are also reported and analyzed. The official access point for data and code is https://github.com/nttcslab/dcase2026_task4_baseline.
M$^2$RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
Mar 15, 2026Transformers are highly parallel but are limited to computations in the TC$^0$ complexity class, excluding tasks such as entity tracking and code execution that provably require greater expressive power. Motivated by this limitation, we revisit non-linear Recurrent Neural Networks (RNNs) for language modeling and introduce Matrix-to-Matrix RNN (M$^2$RNN): an architecture with matrix-valued hidden states and expressive non-linear state transitions. We demonstrate that the language modeling performance of non-linear RNNs is limited by their state size. We also demonstrate how the state size expansion mechanism enables efficient use of tensor cores. Empirically, M$^2$RNN achieves perfect state tracking generalization at sequence lengths not seen during training. These benefits also translate to large-scale language modeling. In hybrid settings that interleave recurrent layers with attention, Hybrid M$^2$RNN outperforms equivalent Gated DeltaNet hybrids by $0.4$-$0.5$ perplexity points on a 7B MoE model, while using $3\times$ smaller state sizes for the recurrent layers. Notably, replacing even a single recurrent layer with M$^2$RNN in an existing hybrid architecture yields accuracy gains comparable to Hybrid M$^2$RNN with minimal impact on training throughput. Further, the Hybrid Gated DeltaNet models with a single M$^2$RNN layer also achieve superior long-context generalization, outperforming state-of-the-art hybrid linear attention architectures by up to $8$ points on LongBench. Together, these results establish non-linear RNN layers as a compelling building block for efficient and scalable language models.
Distilling to Hybrid Attention Models via KL-Guided Layer Selection
Dec 23, 2025Distilling pretrained softmax attention Transformers into more efficient hybrid architectures that interleave softmax and linear attention layers is a promising approach for improving the inference efficiency of LLMs without requiring expensive pretraining from scratch. A critical factor in the conversion process is layer selection, i.e., deciding on which layers to convert to linear attention variants. This paper describes a simple and efficient recipe for layer selection that uses layer importance scores derived from a small amount of training on generic text data. Once the layers have been selected we use a recent pipeline for the distillation process itself \citep[RADLADS;][]{goldstein2025radlads}, which consists of attention weight transfer, hidden state alignment, KL-based distribution matching, followed by a small amount of finetuning. We find that this approach is more effective than existing approaches for layer selection, including heuristics that uniformly interleave linear attentions based on a fixed ratio, as well as more involved approaches that rely on specialized diagnostic datasets.
SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
Dec 16, 2025



Mixture of Experts (MoE) models have emerged as the de facto architecture for scaling up language models without significantly increasing the computational cost. Recent MoE models demonstrate a clear trend towards high expert granularity (smaller expert intermediate dimension) and higher sparsity (constant number of activated experts with higher number of total experts), which improve model quality per FLOP. However, fine-grained MoEs suffer from increased activation memory footprint and reduced hardware efficiency due to higher IO costs, while sparser MoEs suffer from wasted computations due to padding in Grouped GEMM kernels. In response, we propose a memory-efficient algorithm to compute the forward and backward passes of MoEs with minimal activation caching for the backward pass. We also design GPU kernels that overlap memory IO with computation benefiting all MoE architectures. Finally, we propose a novel "token rounding" method that minimizes the wasted compute due to padding in Grouped GEMM kernels. As a result, our method SonicMoE reduces activation memory by 45% and achieves a 1.86x compute throughput improvement on Hopper GPUs compared to ScatterMoE's BF16 MoE kernel for a fine-grained 7B MoE. Concretely, SonicMoE on 64 H100s achieves a training throughput of 213 billion tokens per day comparable to ScatterMoE's 225 billion tokens per day on 96 H100s for a 7B MoE model training with FSDP-2 using the lm-engine codebase. Under high MoE sparsity settings, our tile-aware token rounding algorithm yields an additional 1.16x speedup on kernel execution time compared to vanilla top-$K$ routing while maintaining similar downstream performance. We open-source all our kernels to enable faster MoE model training.
Description and Discussion on DCASE 2025 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Jun 12, 2025

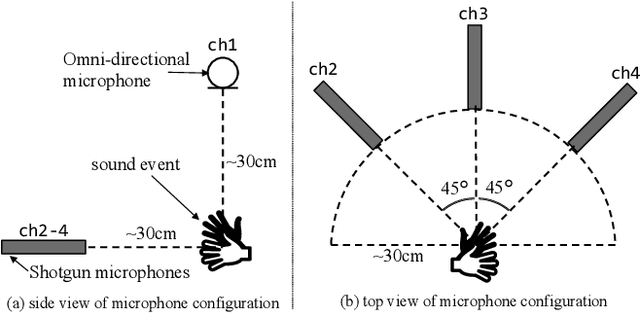
Spatial Semantic Segmentation of Sound Scenes (S5) aims to enhance technologies for sound event detection and separation from multi-channel input signals that mix multiple sound events with spatial information. This is a fundamental basis of immersive communication. The ultimate goal is to separate sound event signals with 6 Degrees of Freedom (6DoF) information into dry sound object signals and metadata about the object type (sound event class) and representing spatial information, including direction. However, because several existing challenge tasks already provide some of the subset functions, this task for this year focuses on detecting and separating sound events from multi-channel spatial input signals. This paper outlines the S5 task setting of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge Task 4 and the DCASE2025 Task 4 Dataset, newly recorded and curated for this task. We also report experimental results for an S5 system trained and evaluated on this dataset. The full version of this paper will be published after the challenge results are made public.
FlashFormer: Whole-Model Kernels for Efficient Low-Batch Inference
May 28, 2025The size and compute characteristics of modern large language models have led to an increased interest in developing specialized kernels tailored for training and inference. Existing kernels primarily optimize for compute utilization, targeting the large-batch training and inference settings. However, low-batch inference, where memory bandwidth and kernel launch overheads contribute are significant factors, remains important for many applications of interest such as in edge deployment and latency-sensitive applications. This paper describes FlashFormer, a proof-of-concept kernel for accelerating single-batch inference for transformer-based large language models. Across various model sizes and quantizations settings, we observe nontrivial speedups compared to existing state-of-the-art inference kernels.
PaTH Attention: Position Encoding via Accumulating Householder Transformations
May 22, 2025The attention mechanism is a core primitive in modern large language models (LLMs) and AI more broadly. Since attention by itself is permutation-invariant, position encoding is essential for modeling structured domains such as language. Rotary position encoding (RoPE) has emerged as the de facto standard approach for position encoding and is part of many modern LLMs. However, in RoPE the key/query transformation between two elements in a sequence is only a function of their relative position and otherwise independent of the actual input. This limits the expressivity of RoPE-based transformers. This paper describes PaTH, a flexible data-dependent position encoding scheme based on accumulated products of Householder(like) transformations, where each transformation is data-dependent, i.e., a function of the input. We derive an efficient parallel algorithm for training through exploiting a compact representation of products of Householder matrices, and implement a FlashAttention-style blockwise algorithm that minimizes I/O cost. Across both targeted synthetic benchmarks and moderate-scale real-world language modeling experiments, we find that PaTH demonstrates superior performance compared to RoPE and other recent baselines.
Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
Jan 11, 2025



Large language model inference is both memory-intensive and time-consuming, often requiring distributed algorithms to efficiently scale. Various model parallelism strategies are used in multi-gpu training and inference to partition computation across multiple devices, reducing memory load and computation time. However, using model parallelism necessitates communication of information between GPUs, which has been a major bottleneck and limits the gains obtained by scaling up the number of devices. We introduce Ladder Residual, a simple architectural modification applicable to all residual-based models that enables straightforward overlapping that effectively hides the latency of communication. Our insight is that in addition to systems optimization, one can also redesign the model architecture to decouple communication from computation. While Ladder Residual can allow communication-computation decoupling in conventional parallelism patterns, we focus on Tensor Parallelism in this paper, which is particularly bottlenecked by its heavy communication. For a Transformer model with 70B parameters, applying Ladder Residual to all its layers can achieve 30% end-to-end wall clock speed up at inference time with TP sharding over 8 devices. We refer the resulting Transformer model as the Ladder Transformer. We train a 1B and 3B Ladder Transformer from scratch and observe comparable performance to a standard dense transformer baseline. We also show that it is possible to convert parts of the Llama-3.1 8B model to our Ladder Residual architecture with minimal accuracy degradation by only retraining for 3B tokens.