 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
Surveying the Effects of Quality, Diversity, and Complexity in Synthetic Data From Large Language Models
Dec 04, 2024



Synthetic data generation with Large Language Models is a promising paradigm for augmenting natural data over a nearly infinite range of tasks. Given this variety, direct comparisons among synthetic data generation algorithms are scarce, making it difficult to understand where improvement comes from and what bottlenecks exist. We propose to evaluate algorithms via the makeup of synthetic data generated by each algorithm in terms of data quality, diversity, and complexity. We choose these three characteristics for their significance in open-ended processes and the impact each has on the capabilities of downstream models. We find quality to be essential for in-distribution model generalization, diversity to be essential for out-of-distribution generalization, and complexity to be beneficial for both. Further, we emphasize the existence of Quality-Diversity trade-offs in training data and the downstream effects on model performance. We then examine the effect of various components in the synthetic data pipeline on each data characteristic. This examination allows us to taxonomize and compare synthetic data generation algorithms through the components they utilize and the resulting effects on data QDC composition. This analysis extends into a discussion on the importance of balancing QDC in synthetic data for efficient reinforcement learning and self-improvement algorithms. Analogous to the QD trade-offs in training data, often there exist trade-offs between model output quality and output diversity which impact the composition of synthetic data. We observe that many models are currently evaluated and optimized only for output quality, thereby limiting output diversity and the potential for self-improvement. We argue that balancing these trade-offs is essential to the development of future self-improvement algorithms and highlight a number of works making progress in this direction.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024



Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Stay on topic with Classifier-Free Guidance
Jun 30, 2023



Classifier-Free Guidance (CFG) has recently emerged in text-to-image generation as a lightweight technique to encourage prompt-adherence in generations. In this work, we demonstrate that CFG can be used broadly as an inference-time technique in pure language modeling. We show that CFG (1) improves the performance of Pythia, GPT-2 and LLaMA-family models across an array of tasks: Q\&A, reasoning, code generation, and machine translation, achieving SOTA on LAMBADA with LLaMA-7B over PaLM-540B; (2) brings improvements equivalent to a model with twice the parameter-count; (3) can stack alongside other inference-time methods like Chain-of-Thought and Self-Consistency, yielding further improvements in difficult tasks; (4) can be used to increase the faithfulness and coherence of assistants in challenging form-driven and content-driven prompts: in a human evaluation we show a 75\% preference for GPT4All using CFG over baseline.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022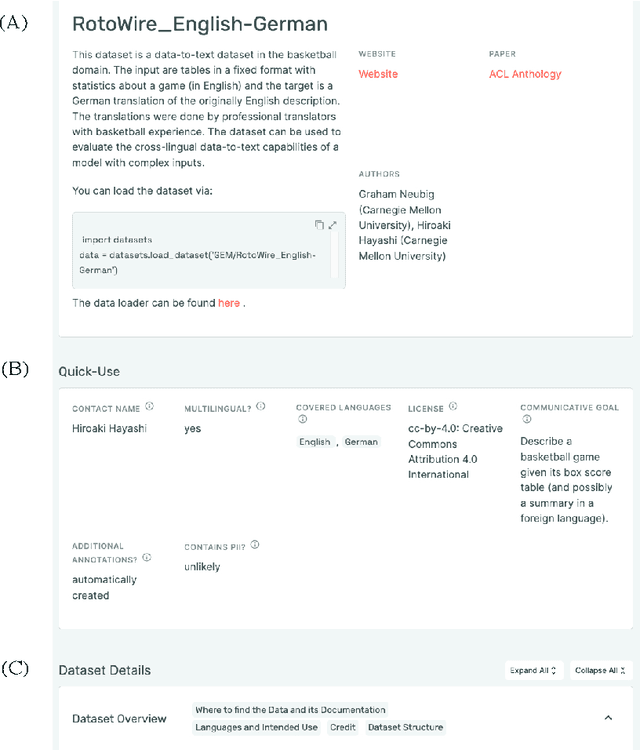

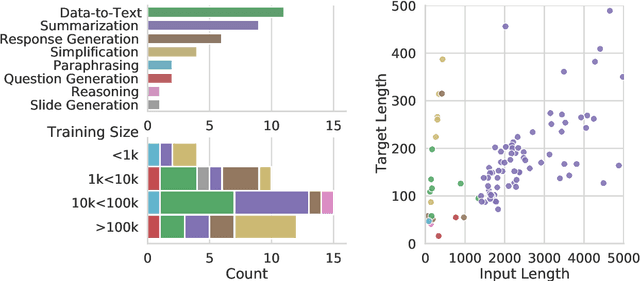

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Reusable Templates and Guides For Documenting Datasets and Models for Natural Language Processing and Generation: A Case Study of the HuggingFace and GEM Data and Model Cards
Aug 16, 2021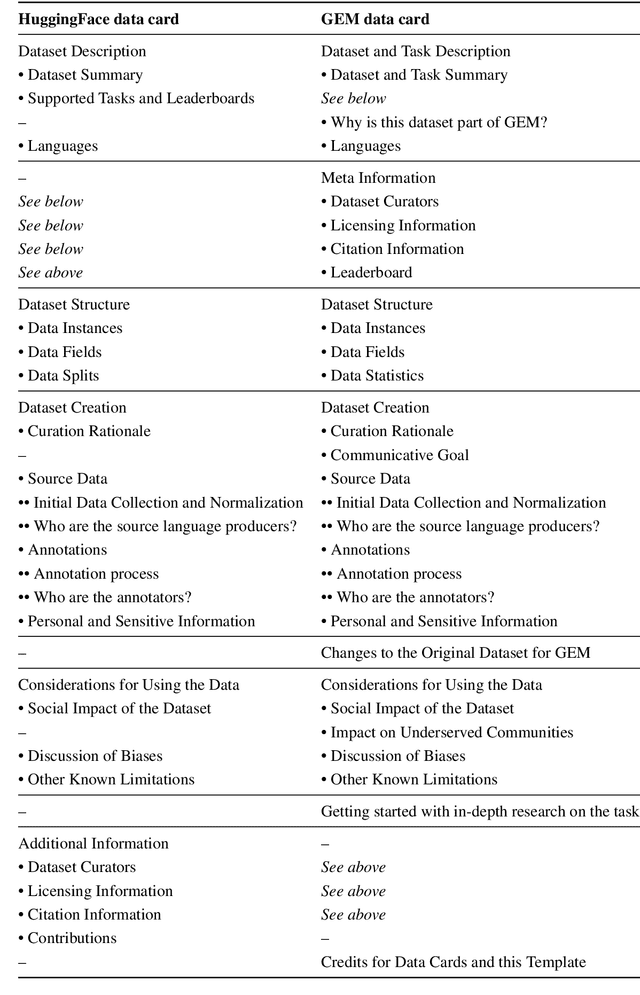

Developing documentation guidelines and easy-to-use templates for datasets and models is a challenging task, especially given the variety of backgrounds, skills, and incentives of the people involved in the building of natural language processing (NLP) tools. Nevertheless, the adoption of standard documentation practices across the field of NLP promotes more accessible and detailed descriptions of NLP datasets and models, while supporting researchers and developers in reflecting on their work. To help with the standardization of documentation, we present two case studies of efforts that aim to develop reusable documentation templates -- the HuggingFace data card, a general purpose card for datasets in NLP, and the GEM benchmark data and model cards with a focus on natural language generation. We describe our process for developing these templates, including the identification of relevant stakeholder groups, the definition of a set of guiding principles, the use of existing templates as our foundation, and iterative revisions based on feedback.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.