 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReevaluation of Inductive Link Prediction
Sep 30, 2024Within this paper, we show that the evaluation protocol currently used for inductive link prediction is heavily flawed as it relies on ranking the true entity in a small set of randomly sampled negative entities. Due to the limited size of the set of negatives, a simple rule-based baseline can achieve state-of-the-art results, which simply ranks entities higher based on the validity of their type. As a consequence of these insights, we reevaluate current approaches for inductive link prediction on several benchmarks using the link prediction protocol usually applied to the transductive setting. As some inductive methods suffer from scalability issues when evaluated in this setting, we propose and apply additionally an improved sampling protocol, which does not suffer from the problem mentioned above. The results of our evaluation differ drastically from the results reported in so far.
* Published in RuleML+RR 2024
Learning Rules from KGs Guided by Language Models
Sep 12, 2024

Advances in information extraction have enabled the automatic construction of large knowledge graphs (e.g., Yago, Wikidata or Google KG), which are widely used in many applications like semantic search or data analytics. However, due to their semi-automatic construction, KGs are often incomplete. Rule learning methods, concerned with the extraction of frequent patterns from KGs and casting them into rules, can be applied to predict potentially missing facts. A crucial step in this process is rule ranking. Ranking of rules is especially challenging over highly incomplete or biased KGs (e.g., KGs predominantly storing facts about famous people), as in this case biased rules might fit the data best and be ranked at the top based on standard statistical metrics like rule confidence. To address this issue, prior works proposed to rank rules not only relying on the original KG but also facts predicted by a KG embedding model. At the same time, with the recent rise of Language Models (LMs), several works have claimed that LMs can be used as alternative means for KG completion. In this work, our goal is to verify to which extent the exploitation of LMs is helpful for improving the quality of rule learning systems.
ThoughtSource: A central hub for large language model reasoning data
Jan 27, 2023Large language models (LLMs) such as GPT-3 and ChatGPT have recently demonstrated impressive results across a wide range of tasks. LLMs are still limited, however, in that they frequently fail at complex reasoning, their reasoning processes are opaque, they are prone to 'hallucinate' facts, and there are concerns about their underlying biases. Letting models verbalize reasoning steps as natural language, a technique known as chain-of-thought prompting, has recently been proposed as a way to address some of these issues. Here we present the first release of ThoughtSource, a meta-dataset and software library for chain-of-thought (CoT) reasoning. The goal of ThoughtSource is to improve future artificial intelligence systems by facilitating qualitative understanding of CoTs, enabling empirical evaluations, and providing training data. This first release of ThoughtSource integrates six scientific/medical, three general-domain and five math word question answering datasets.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
BigBIO: A Framework for Data-Centric Biomedical Natural Language Processing
Jun 30, 2022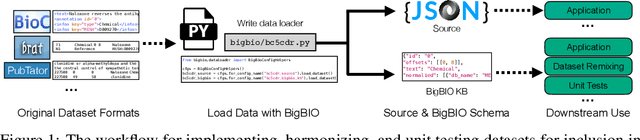
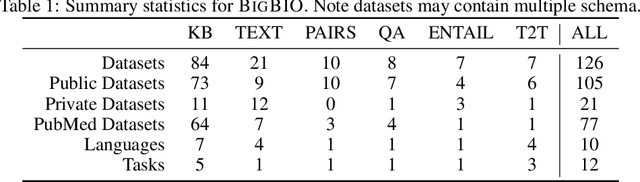

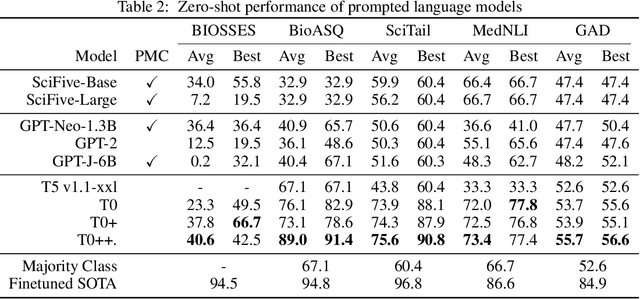
Training and evaluating language models increasingly requires the construction of meta-datasets --diverse collections of curated data with clear provenance. Natural language prompting has recently lead to improved zero-shot generalization by transforming existing, supervised datasets into a diversity of novel pretraining tasks, highlighting the benefits of meta-dataset curation. While successful in general-domain text, translating these data-centric approaches to biomedical language modeling remains challenging, as labeled biomedical datasets are significantly underrepresented in popular data hubs. To address this challenge, we introduce BigBIO a community library of 126+ biomedical NLP datasets, currently covering 12 task categories and 10+ languages. BigBIO facilitates reproducible meta-dataset curation via programmatic access to datasets and their metadata, and is compatible with current platforms for prompt engineering and end-to-end few/zero shot language model evaluation. We discuss our process for task schema harmonization, data auditing, contribution guidelines, and outline two illustrative use cases: zero-shot evaluation of biomedical prompts and large-scale, multi-task learning. BigBIO is an ongoing community effort and is available at https://github.com/bigscience-workshop/biomedical
A global analysis of metrics used for measuring performance in natural language processing
Apr 25, 2022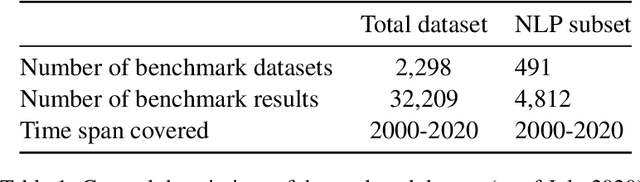
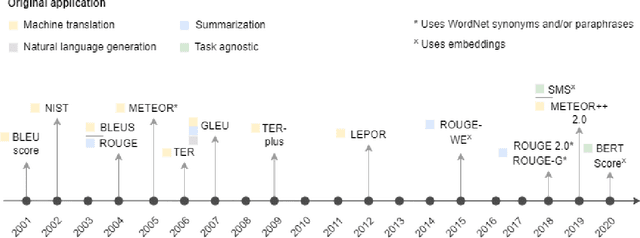
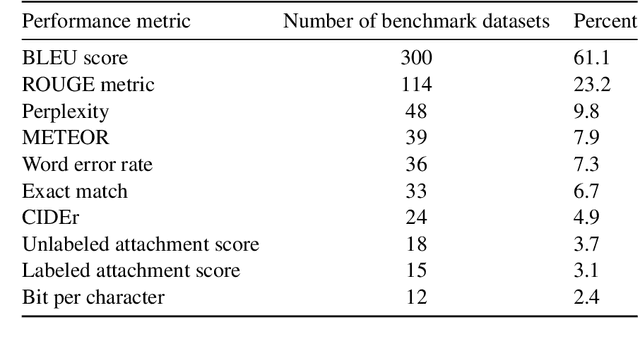
Measuring the performance of natural language processing models is challenging. Traditionally used metrics, such as BLEU and ROUGE, originally devised for machine translation and summarization, have been shown to suffer from low correlation with human judgment and a lack of transferability to other tasks and languages. In the past 15 years, a wide range of alternative metrics have been proposed. However, it is unclear to what extent this has had an impact on NLP benchmarking efforts. Here we provide the first large-scale cross-sectional analysis of metrics used for measuring performance in natural language processing. We curated, mapped and systematized more than 3500 machine learning model performance results from the open repository 'Papers with Code' to enable a global and comprehensive analysis. Our results suggest that the large majority of natural language processing metrics currently used have properties that may result in an inadequate reflection of a models' performance. Furthermore, we found that ambiguities and inconsistencies in the reporting of metrics may lead to difficulties in interpreting and comparing model performances, impairing transparency and reproducibility in NLP research.
Mapping global dynamics of benchmark creation and saturation in artificial intelligence
Mar 09, 2022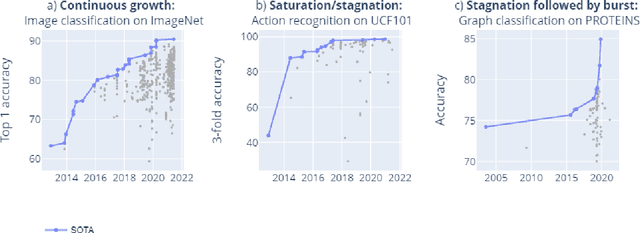
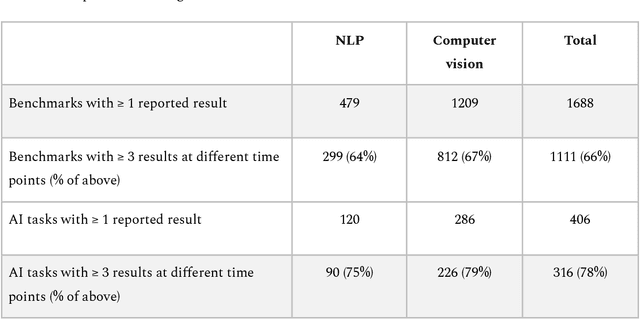
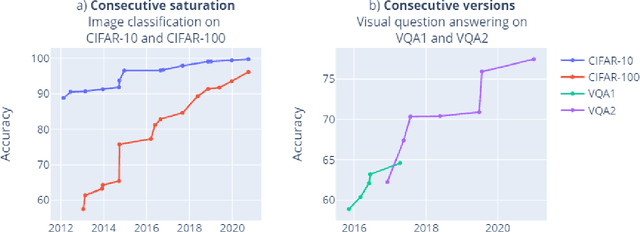
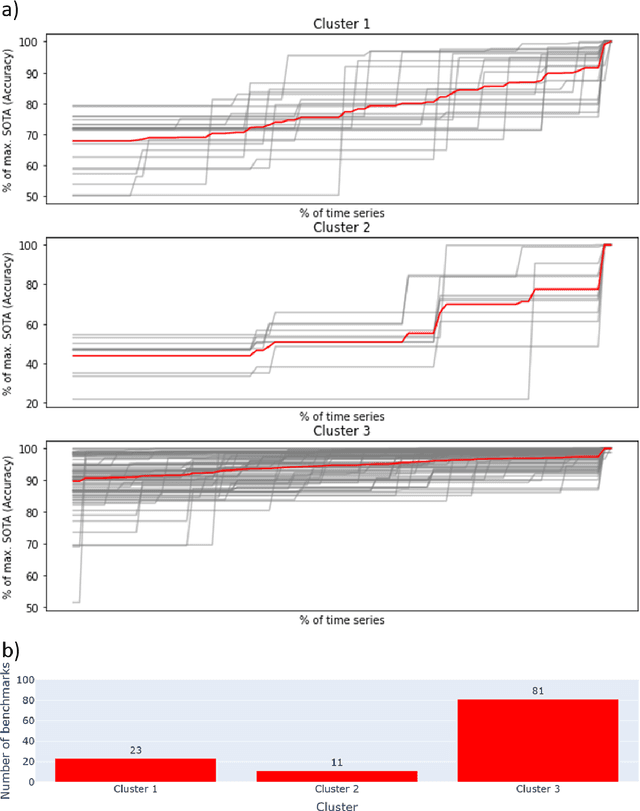
Benchmarks are crucial to measuring and steering progress in artificial intelligence (AI). However, recent studies raised concerns over the state of AI benchmarking, reporting issues such as benchmark overfitting, benchmark saturation and increasing centralization of benchmark dataset creation. To facilitate monitoring of the health of the AI benchmarking ecosystem, we introduce methodologies for creating condensed maps of the global dynamics of benchmark creation and saturation. We curated data for 1688 benchmarks covering the entire domains of computer vision and natural language processing, and show that a large fraction of benchmarks quickly trended towards near-saturation, that many benchmarks fail to find widespread utilization, and that benchmark performance gains for different AI tasks were prone to unforeseen bursts. We conclude that future work should focus on large-scale community collaboration and on mapping benchmark performance gains to real-world utility and impact of AI.
A curated, ontology-based, large-scale knowledge graph of artificial intelligence tasks and benchmarks
Oct 06, 2021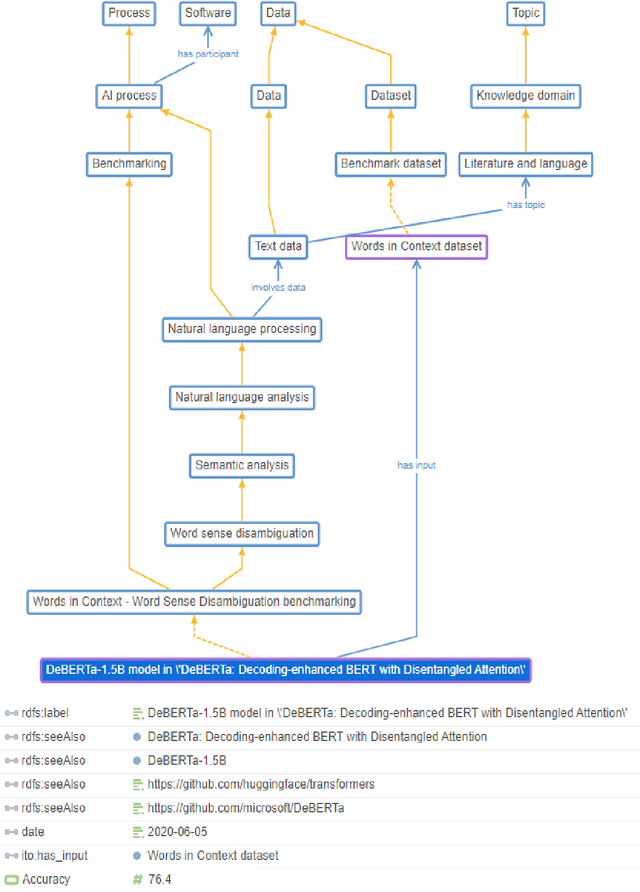
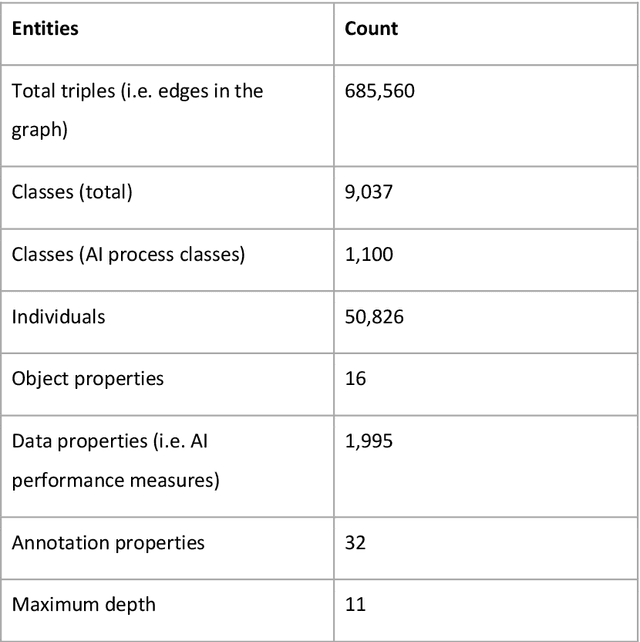
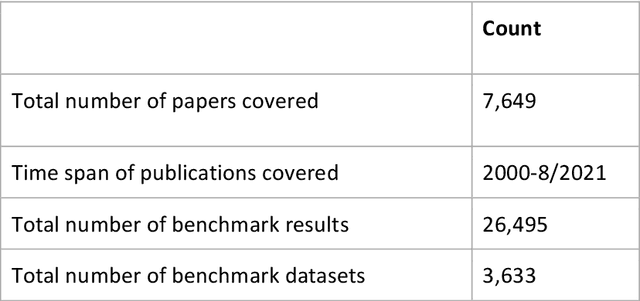
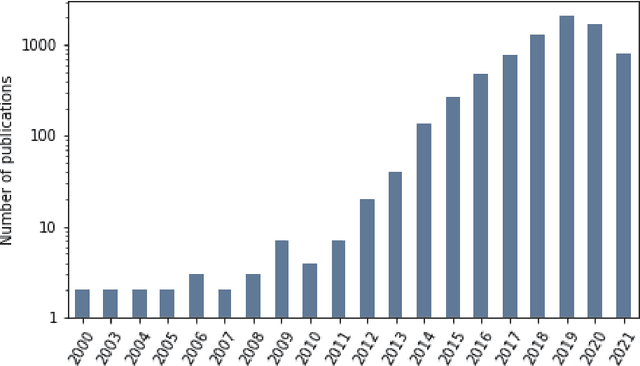
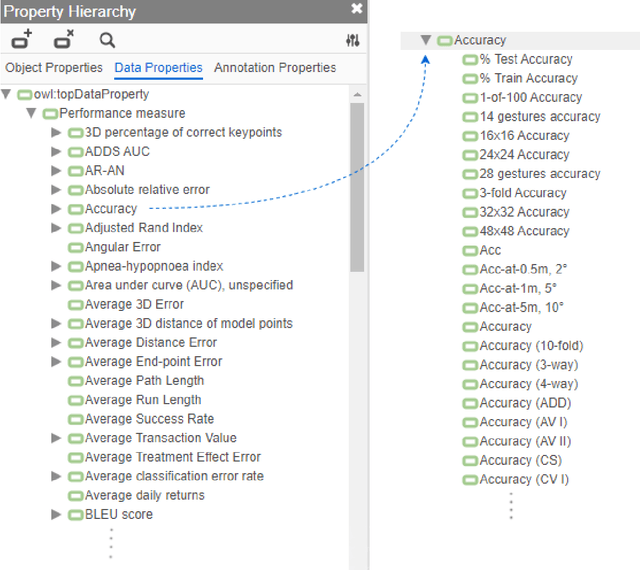
Research in artificial intelligence (AI) is addressing a growing number of tasks through a rapidly growing number of models and methodologies. This makes it difficult to keep track of where novel AI methods are successfully -- or still unsuccessfully -- applied, how progress is measured, how different advances might synergize with each other, and how future research should be prioritized. To help address these issues, we created the Intelligence Task Ontology and Knowledge Graph (ITO), a comprehensive, richly structured and manually curated resource on artificial intelligence tasks, benchmark results and performance metrics. The current version of ITO contain 685,560 edges, 1,100 classes representing AI processes and 1,995 properties representing performance metrics. The goal of ITO is to enable precise and network-based analyses of the global landscape of AI tasks and capabilities. ITO is based on technologies that allow for easy integration and enrichment with external data, automated inference and continuous, collaborative expert curation of underlying ontological models. We make the ITO dataset and a collection of Jupyter notebooks utilising ITO openly available.
SAFRAN: An interpretable, rule-based link prediction method outperforming embedding models
Sep 16, 2021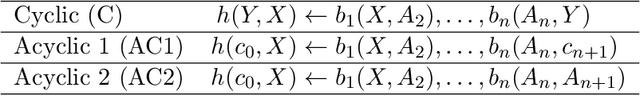

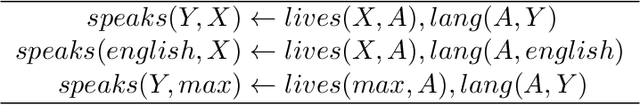
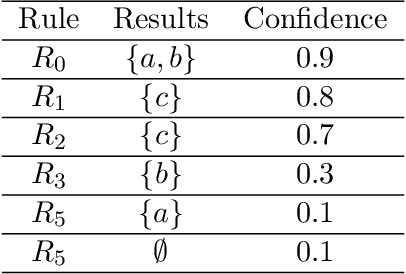
Neural embedding-based machine learning models have shown promise for predicting novel links in knowledge graphs. Unfortunately, their practical utility is diminished by their lack of interpretability. Recently, the fully interpretable, rule-based algorithm AnyBURL yielded highly competitive results on many general-purpose link prediction benchmarks. However, current approaches for aggregating predictions made by multiple rules are affected by redundancies. We improve upon AnyBURL by introducing the SAFRAN rule application framework, which uses a novel aggregation approach called Non-redundant Noisy-OR that detects and clusters redundant rules prior to aggregation. SAFRAN yields new state-of-the-art results for fully interpretable link prediction on the established general-purpose benchmarks FB15K-237, WN18RR and YAGO3-10. Furthermore, it exceeds the results of multiple established embedding-based algorithms on FB15K-237 and WN18RR and narrows the gap between rule-based and embedding-based algorithms on YAGO3-10.
Scalable and interpretable rule-based link prediction for large heterogeneous knowledge graphs
Dec 10, 2020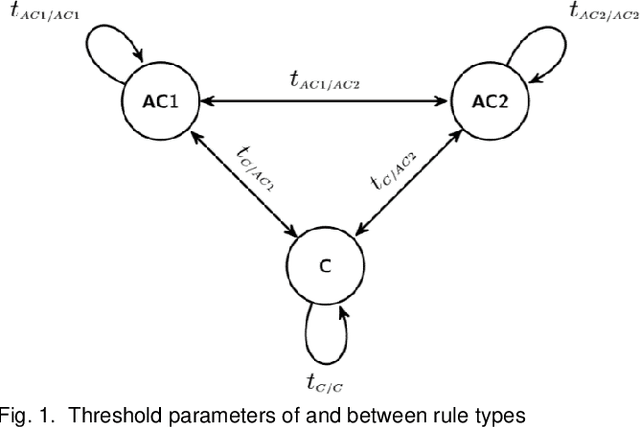


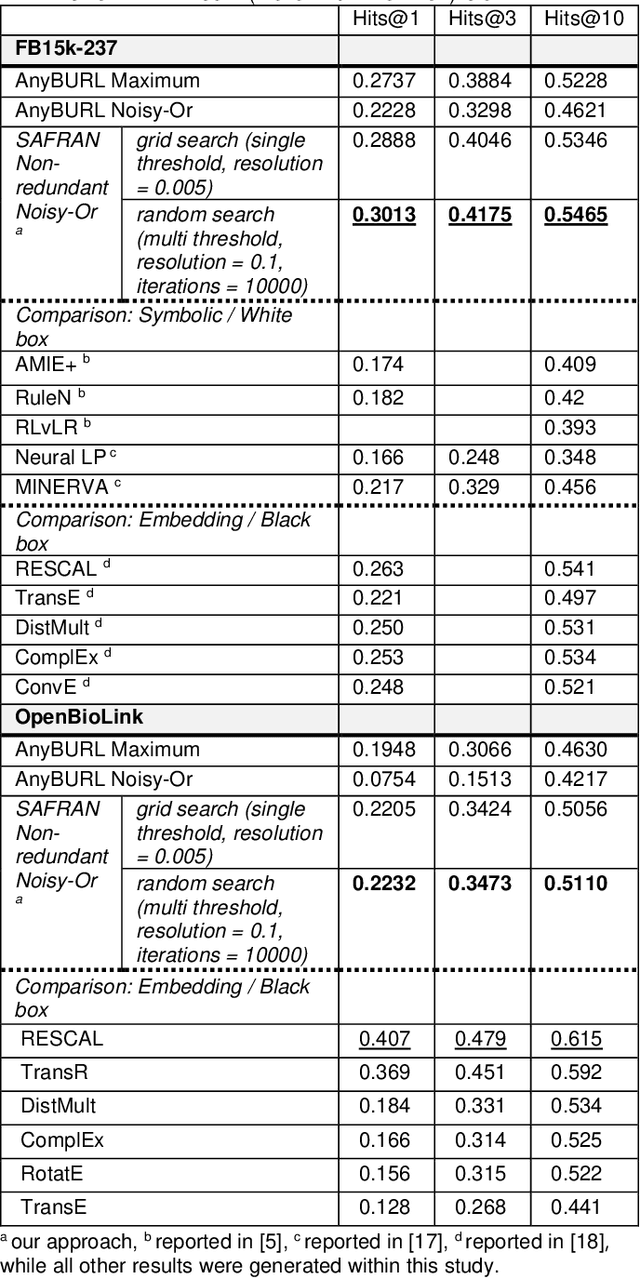
Neural embedding-based machine learning models have shown promise for predicting novel links in biomedical knowledge graphs. Unfortunately, their practical utility is diminished by their lack of interpretability. Recently, the fully interpretable, rule-based algorithm AnyBURL yielded highly competitive results on many general-purpose link prediction benchmarks. However, its applicability to large-scale prediction tasks on complex biomedical knowledge bases is limited by long inference times and difficulties with aggregating predictions made by multiple rules. We improve upon AnyBURL by introducing the SAFRAN rule application framework which aggregates rules through a scalable clustering algorithm. SAFRAN yields new state-of-the-art results for fully interpretable link prediction on the established general-purpose benchmark FB15K-237 and the large-scale biomedical benchmark OpenBioLink. Furthermore, it exceeds the results of multiple established embedding-based algorithms on FB15K-237 and narrows the gap between rule-based and embedding-based algorithms on OpenBioLink. We also show that SAFRAN increases inference speeds by up to two orders of magnitude.