 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBolmo: Byteifying the Next Generation of Language Models
Dec 17, 2025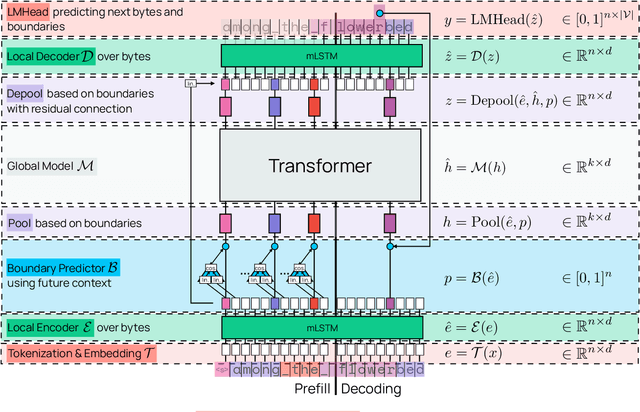
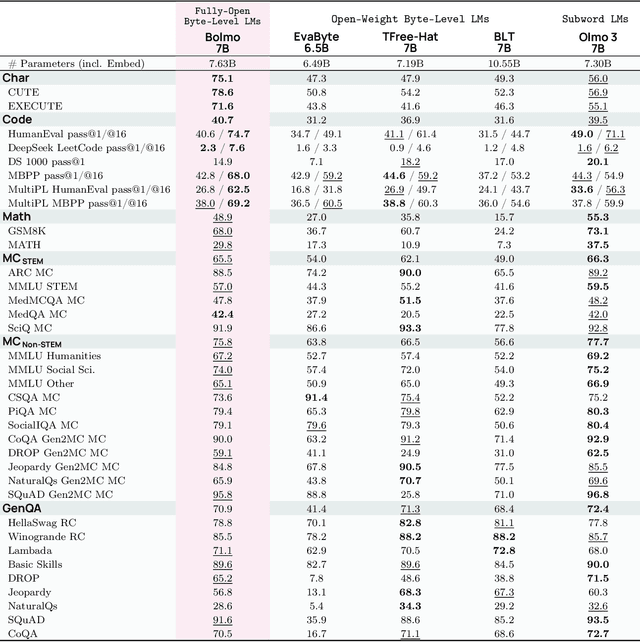
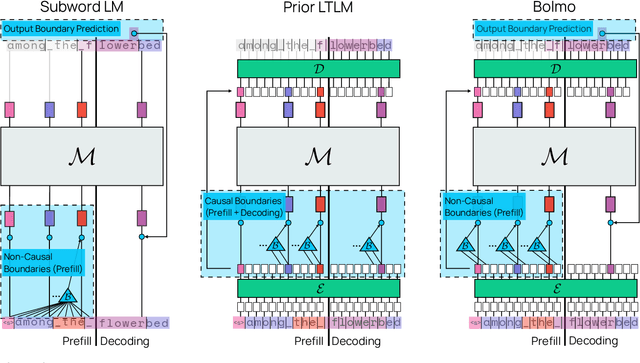
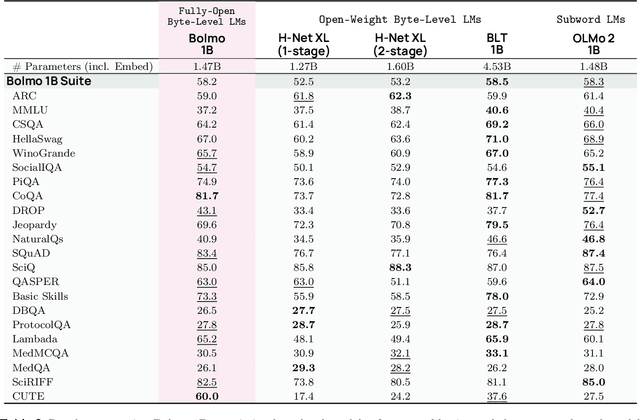
We introduce Bolmo, the first family of competitive fully open byte-level language models (LMs) at the 1B and 7B parameter scales. In contrast to prior research on byte-level LMs, which focuses predominantly on training from scratch, we train Bolmo by byteifying existing subword-level LMs. Byteification enables overcoming the limitations of subword tokenization - such as insufficient character understanding and efficiency constraints due to the fixed subword vocabulary - while performing at the level of leading subword-level LMs. Bolmo is specifically designed for byteification: our architecture resolves a mismatch between the expressivity of prior byte-level architectures and subword-level LMs, which makes it possible to employ an effective exact distillation objective between Bolmo and the source subword model. This allows for converting a subword-level LM to a byte-level LM by investing less than 1\% of a typical pretraining token budget. Bolmo substantially outperforms all prior byte-level LMs of comparable size, and outperforms the source subword-level LMs on character understanding and, in some cases, coding, while coming close to matching the original LMs' performance on other tasks. Furthermore, we show that Bolmo can achieve inference speeds competitive with subword-level LMs by training with higher token compression ratios, and can be cheaply and effectively post-trained by leveraging the existing ecosystem around the source subword-level LM. Our results finally make byte-level LMs a practical choice competitive with subword-level LMs across a wide set of use cases.
Beyond Literal Token Overlap: Token Alignability for Multilinguality
Feb 10, 2025



Previous work has considered token overlap, or even similarity of token distributions, as predictors for multilinguality and cross-lingual knowledge transfer in language models. However, these very literal metrics assign large distances to language pairs with different scripts, which can nevertheless show good cross-linguality. This limits the explanatory strength of token overlap for knowledge transfer between language pairs that use distinct scripts or follow different orthographic conventions. In this paper, we propose subword token alignability as a new way to understand the impact and quality of multilingual tokenisation. In particular, this metric predicts multilinguality much better when scripts are disparate and the overlap of literal tokens is low. We analyse this metric in the context of both encoder and decoder models, look at data size as a potential distractor, and discuss how this insight may be applied to multilingual tokenisation in future work. We recommend our subword token alignability metric for identifying optimal language pairs for cross-lingual transfer, as well as to guide the construction of better multilingual tokenisers in the future. We publish our code and reproducibility details.
Dual Debiasing: Remove Stereotypes and Keep Factual Gender for Fair Language Modeling and Translation
Jan 17, 2025Mitigation of biases, such as language models' reliance on gender stereotypes, is a crucial endeavor required for the creation of reliable and useful language technology. The crucial aspect of debiasing is to ensure that the models preserve their versatile capabilities, including their ability to solve language tasks and equitably represent various genders. To address this issue, we introduce a streamlined Dual Dabiasing Algorithm through Model Adaptation (2DAMA). Novel Dual Debiasing enables robust reduction of stereotypical bias while preserving desired factual gender information encoded by language models. We show that 2DAMA effectively reduces gender bias in English and is one of the first approaches facilitating the mitigation of stereotypical tendencies in translation. The proposed method's key advantage is the preservation of factual gender cues, which are useful in a wide range of natural language processing tasks.
Teaching LLMs at Charles University: Assignments and Activities
Jul 29, 2024This paper presents teaching materials, particularly assignments and ideas for classroom activities, from a new course on large language models (LLMs) taught at Charles University. The assignments include experiments with LLM inference for weather report generation and machine translation. The classroom activities include class quizzes, focused research on downstream tasks and datasets, and an interactive "best paper" session aimed at reading and comprehension of research papers.
MAGNET: Improving the Multilingual Fairness of Language Models with Adaptive Gradient-Based Tokenization
Jul 11, 2024



In multilingual settings, non-Latin scripts and low-resource languages are usually disadvantaged in terms of language models' utility, efficiency, and cost. Specifically, previous studies have reported multiple modeling biases that the current tokenization algorithms introduce to non-Latin script languages, the main one being over-segmentation. In this work, we propose MAGNET; multilingual adaptive gradient-based tokenization to reduce over-segmentation via adaptive gradient-based subword tokenization. MAGNET learns to predict segment boundaries between byte tokens in a sequence via sub-modules within the model, which act as internal boundary predictors (tokenizers). Previous gradient-based tokenization methods aimed for uniform compression across sequences by integrating a single boundary predictor during training and optimizing it end-to-end through stochastic reparameterization alongside the next token prediction objective. However, this approach still results in over-segmentation for non-Latin script languages in multilingual settings. In contrast, MAGNET offers a customizable architecture where byte-level sequences are routed through language-script-specific predictors, each optimized for its respective language script. This modularity enforces equitable segmentation granularity across different language scripts compared to previous methods. Through extensive experiments, we demonstrate that in addition to reducing segmentation disparities, MAGNET also enables faster language modelling and improves downstream utility.
MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling
Mar 15, 2024A major consideration in multilingual language modeling is how to best represent languages with diverse vocabularies and scripts. Although contemporary text encoding methods cover most of the world's writing systems, they exhibit bias towards the high-resource languages of the Global West. As a result, texts of underrepresented languages tend to be segmented into long sequences of linguistically meaningless units. To address the disparities, we introduce a new paradigm that encodes the same information with segments of consistent size across diverse languages. Our encoding convention (MYTE) is based on morphemes, as their inventories are more balanced across languages than characters, which are used in previous methods. We show that MYTE produces shorter encodings for all 99 analyzed languages, with the most notable improvements for non-European languages and non-Latin scripts. This, in turn, improves multilingual LM performance and diminishes the perplexity gap throughout diverse languages.
Breaking the Curse of Multilinguality with Cross-lingual Expert Language Models
Jan 19, 2024



Despite their popularity in non-English NLP, multilingual language models often underperform monolingual ones due to inter-language competition for model parameters. We propose Cross-lingual Expert Language Models (X-ELM), which mitigate this competition by independently training language models on subsets of the multilingual corpus. This process specializes X-ELMs to different languages while remaining effective as a multilingual ensemble. Our experiments show that when given the same compute budget, X-ELM outperforms jointly trained multilingual models across all considered languages and that these gains transfer to downstream tasks. X-ELM provides additional benefits over performance improvements: new experts can be iteratively added, adapting X-ELM to new languages without catastrophic forgetting. Furthermore, training is asynchronous, reducing the hardware requirements for multilingual training and democratizing multilingual modeling.
Debiasing Algorithm through Model Adaptation
Oct 29, 2023



Large language models are becoming the go-to solution for various language tasks. However, with growing capacity, models are prone to rely on spurious correlations stemming from biases and stereotypes present in the training data. This work proposes a novel method for detecting and mitigating gender bias in language models. We perform causal analysis to identify problematic model components and discover that mid-upper feed-forward layers are most prone to convey biases. Based on the analysis results, we adapt the model by multiplying these layers by a linear projection. Our titular method, DAMA, significantly decreases bias as measured by diverse metrics while maintaining the model's performance on downstream tasks. We release code for our method and models, which retrain LLaMA's state-of-the-art performance while being significantly less biased.
Exploring the Impact of Training Data Distribution and Subword Tokenization on Gender Bias in Machine Translation
Sep 30, 2023We study the effect of tokenization on gender bias in machine translation, an aspect that has been largely overlooked in previous works. Specifically, we focus on the interactions between the frequency of gendered profession names in training data, their representation in the subword tokenizer's vocabulary, and gender bias. We observe that female and non-stereotypical gender inflections of profession names (e.g., Spanish "doctora" for "female doctor") tend to be split into multiple subword tokens. Our results indicate that the imbalance of gender forms in the model's training corpus is a major factor contributing to gender bias and has a greater impact than subword splitting. We show that analyzing subword splits provides good estimates of gender-form imbalance in the training data and can be used even when the corpus is not publicly available. We also demonstrate that fine-tuning just the token embedding layer can decrease the gap in gender prediction accuracy between female and male forms without impairing the translation quality.
Tokenization Impacts Multilingual Language Modeling: Assessing Vocabulary Allocation and Overlap Across Languages
May 26, 2023



Multilingual language models have recently gained attention as a promising solution for representing multiple languages in a single model. In this paper, we propose new criteria to evaluate the quality of lexical representation and vocabulary overlap observed in sub-word tokenizers. Our findings show that the overlap of vocabulary across languages can be actually detrimental to certain downstream tasks (POS, dependency tree labeling). In contrast, NER and sentence-level tasks (cross-lingual retrieval, NLI) benefit from sharing vocabulary. We also observe that the coverage of the language-specific tokens in the multilingual vocabulary significantly impacts the word-level tasks. Our study offers a deeper understanding of the role of tokenizers in multilingual language models and guidelines for future model developers to choose the most suitable tokenizer for their specific application before undertaking costly model pre-training