 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Contextual Attention Mechanism, SRGAN Based Inpainting System for Eliminating Interruptions from Images
Apr 06, 2022
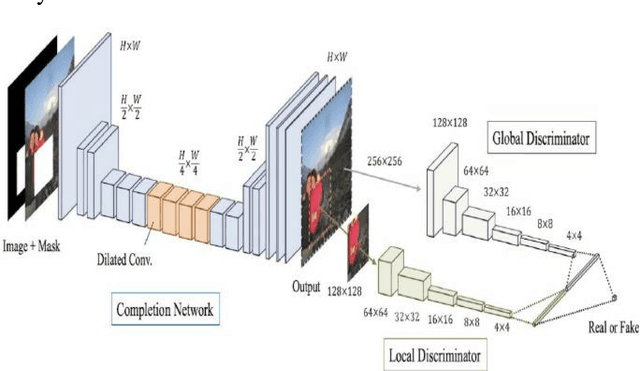
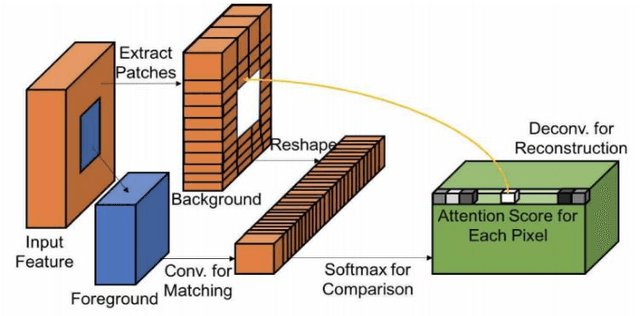
The new alternative is to use deep learning to inpaint any image by utilizing image classification and computer vision techniques. In general, image inpainting is a task of recreating or reconstructing any broken image which could be a photograph or oil/acrylic painting. With the advancement in the field of Artificial Intelligence, this topic has become popular among AI enthusiasts. With our approach, we propose an initial end-to-end pipeline for inpainting images using a complete Machine Learning approach instead of a conventional application-based approach. We first use the YOLO model to automatically identify and localize the object we wish to remove from the image. Using the result obtained from the model we can generate a mask for the same. After this, we provide the masked image and original image to the GAN model which uses the Contextual Attention method to fill in the region. It consists of two generator networks and two discriminator networks and is also called a coarse-to-fine network structure. The two generators use fully convolutional networks while the global discriminator gets hold of the entire image as input while the local discriminator gets the grip of the filled region as input. The contextual Attention mechanism is proposed to effectively borrow the neighbor information from distant spatial locations for reconstructing the missing pixels. The third part of our implementation uses SRGAN to resolve the inpainted image back to its original size. Our work is inspired by the paper Free-Form Image Inpainting with Gated Convolution and Generative Image Inpainting with Contextual Attention.