 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSycophancy as a Multilingual Alignment Failure: How Safety Degrades Across Languages, Topics, and Models
Jun 07, 2026Safety-aligned large language models often exhibit sycophancy, which is the tendency to affirm users' opinions regardless of factual accuracy. Although well-studied in English, its manifestation in other languages remains largely unexamined, leaving billions of non-English speakers potentially vulnerable to model-validated misinformation. We present the first large-scale, multi-model evaluation of cross-lingual sycophancy, benchmarking \textbf{six instruction-tuned models} across \textbf{1.1 million instances} spanning \textbf{38 languages} and \textbf{33 topic categories}. We identify a consistent resource-tier effect: sycophancy rates spike sharply in low-resource and zero-shot language settings. Critically, this degradation is topic-agnostic, as models fail uniformly across both benign and safety-critical prompts, offering no additional protection where it is most needed. We further identify tokenizer fertility as a structural driver of this alignment collapse. Collectively, our results demonstrate that prevailing alignment methodologies generalize poorly beyond high-resource languages, underscoring the urgent need for equitable multilingual safety techniques.
Lingo_Research_Group at SemEval-2026 Task 9: Evaluating Prompt Variants for Polarization Detection
Jun 02, 2026Our submission presented in this paper is for SemEval-2026 Task 9: Multilingual Text Classification Challenge - Polarization Detection and it covers all three subtasks: (1) binary polarization detection, (2) polarization type classification and (3) polarization manifestation identification. We adopt a systematic approach of research on short designed prompts by considering twelve designed prompts that are different in terminology clarity, detail of the definition, guidance of reasoning and in-context examples use. The experiments are conducted using aya-101 and Gemma3-27B, with the latter chosen for the submission at the end of the development through performance considerations. Our system has an average macro level F1-score of 0.762 on Subtask 1, 0.587 on Subtask 2 and 0.444 on Subtask 3 with the average accuracy of 0.819, 0.678 and 0.498, respectively, on the official test set averaged among 22 languages, respectively. With cross-task and cross-lingual analysis, we demonstrate that prompt-based approaches can be used effectively to detect coarse grained polarization but encounter more and more difficulties as far as fine-grained and multi-label sociolinguistic classification is concerned.
Where Does Toxicity Live? Mechanistic Localization and Targeted Suppression in Language Models
May 27, 2026Large language models frequently generate toxic, hateful, or harmful content, yet existing mitigation methods rely on costly retraining or output-level filtering with no mechanistic insight into where toxicity originates internally. We introduce Meow2X and TRNE, two complementary retraining-free frameworks that localize toxicity to specific layers and neurons by analyzing activation differentials between toxic and neutral prompts, then suppress them via inference-time scaling or minimal rank-one weight edits -- without any gradient descent. Evaluations across five LMs, two benchmarks, and 90 configurations using dual safety evaluators demonstrate consistent toxicity reduction while preserving language modeling quality. Our analysis reveals that toxicity is disproportionately encoded in early MLP layers, varies across architectures, and is systematically underestimated by single-evaluator setups -- underscoring the need for multi-evaluator safety assessment. By bridging mechanistic interpretability with practical detoxification, our framework offers a principled path toward safer, more transparent language models.
Gaslight, Gatekeep, V1-V3: Early Visual Cortex Alignment Shields Vision-Language Models from Sycophantic Manipulation
Apr 15, 2026Vision-language models are increasingly deployed in high-stakes settings, yet their susceptibility to sycophantic manipulation remains poorly understood, particularly in relation to how these models represent visual information internally. Whether models whose visual representations more closely mirror human neural processing are also more resistant to adversarial pressure is an open question with implications for both neuroscience and AI safety. We investigate this question by evaluating 12 open-weight vision-language models spanning 6 architecture families and a 40$\times$ parameter range (256M--10B) along two axes: brain alignment, measured by predicting fMRI responses from the Natural Scenes Dataset across 8 human subjects and 6 visual cortex regions of interest, and sycophancy, measured through 76,800 two-turn gaslighting prompts spanning 5 categories and 10 difficulty levels. Region-of-interest analysis reveals that alignment specifically in early visual cortex (V1--V3) is a reliable negative predictor of sycophancy ($r = -0.441$, BCa 95\% CI $[-0.740, -0.031]$), with all 12 leave-one-out correlations negative and the strongest effect for existence denial attacks ($r = -0.597$, $p = 0.040$). This anatomically specific relationship is absent in higher-order category-selective regions, suggesting that faithful low-level visual encoding provides a measurable anchor against adversarial linguistic override in vision-language models. We release our code on \href{https://github.com/aryashah2k/Gaslight-Gatekeep-Sycophantic-Manipulation}{GitHub} and dataset on \href{https://huggingface.co/datasets/aryashah00/Gaslight-Gatekeep-V1-V3}{Hugging Face}
Task--Specificity Score: Measuring How Much Instructions Really Matter for Supervision
Feb 03, 2026Instruction tuning is now the default way to train and adapt large language models, but many instruction--input--output pairs are only weakly specified: for a given input, the same output can remain plausible under several alternative instructions. This raises a simple question: \emph{does the instruction uniquely determine the target output?} We propose the \textbf{Task--Specificity Score (TSS)} to quantify how much an instruction matters for predicting its output, by contrasting the true instruction against plausible alternatives for the same input. We further introduce \textbf{TSS++}, which uses hard alternatives and a small quality term to mitigate easy-negative effects. Across three instruction datasets (\textsc{Alpaca}, \textsc{Dolly-15k}, \textsc{NI-20}) and three open LLMs (Gemma, Llama, Qwen), we show that selecting task-specific examples improves downstream performance under tight token budgets and complements quality-based filters such as perplexity and IFD.
Error Taxonomy-Guided Prompt Optimization
Feb 01, 2026Automatic Prompt Optimization (APO) is a powerful approach for extracting performance from large language models without modifying their weights. Many existing methods rely on trial-and-error, testing different prompts or in-context examples until a good configuration emerges, often consuming substantial compute. Recently, natural language feedback derived from execution logs has shown promise as a way to identify how prompts can be improved. However, most prior approaches operate in a bottom-up manner, iteratively adjusting the prompt based on feedback from individual problems, which can cause them to lose the global perspective. In this work, we propose Error Taxonomy-Guided Prompt Optimization (ETGPO), a prompt optimization algorithm that adopts a top-down approach. ETGPO focuses on the global failure landscape by collecting model errors, categorizing them into a taxonomy, and augmenting the prompt with guidance targeting the most frequent failure modes. Across multiple benchmarks spanning mathematics, question answering, and logical reasoning, ETGPO achieves accuracy that is comparable to or better than state-of-the-art methods, while requiring roughly one third of the optimization-phase token usage and evaluation budget.
One Instruction Does Not Fit All: How Well Do Embeddings Align Personas and Instructions in Low-Resource Indian Languages?
Jan 15, 2026Aligning multilingual assistants with culturally grounded user preferences is essential for serving India's linguistically diverse population of over one billion speakers across multiple scripts. However, existing benchmarks either focus on a single language or conflate retrieval with generation, leaving open the question of whether current embedding models can encode persona-instruction compatibility without relying on response synthesis. We present a unified benchmark spanning 12 Indian languages and four evaluation tasks: monolingual and cross-lingual persona-to-instruction retrieval, reverse retrieval from instruction to persona, and binary compatibility classification. Eight multilingual embedding models are evaluated in a frozen-encoder setting with a thin logistic regression head for classification. E5-Large-Instruct achieves the highest Recall@1 of 27.4\% on monolingual retrieval and 20.7\% on cross-lingual transfer, while BGE-M3 leads reverse retrieval at 32.1\% Recall@1. For classification, LaBSE attains 75.3\% AUROC with strong calibration. These findings offer practical guidance for model selection in Indic multilingual retrieval and establish reproducible baselines for future work\footnote{Code, datasets, and models are publicly available at https://github.com/aryashah2k/PI-Indic-Align.
Grammar Search for Multi-Agent Systems
Dec 16, 2025


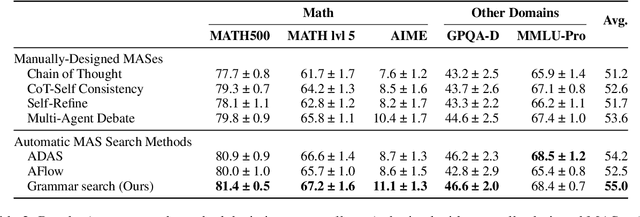
Automatic search for Multi-Agent Systems has recently emerged as a key focus in agentic AI research. Several prior approaches have relied on LLM-based free-form search over the code space. In this work, we propose a more structured framework that explores the same space through a fixed set of simple, composable components. We show that, despite lacking the generative flexibility of LLMs during the candidate generation stage, our method outperforms prior approaches on four out of five benchmarks across two domains: mathematics and question answering. Furthermore, our method offers additional advantages, including a more cost-efficient search process and the generation of modular, interpretable multi-agent systems with simpler logic.
Beyond Monolingual Assumptions: A Survey of Code-Switched NLP in the Era of Large Language Models
Oct 08, 2025



Code-switching (CSW), the alternation of languages and scripts within a single utterance, remains a fundamental challenge for multiling ual NLP, even amidst the rapid advances of large language models (LLMs). Most LLMs still struggle with mixed-language inputs, limited CSW datasets, and evaluation biases, hindering deployment in multilingual societies. This survey provides the first comprehensive analysis of CSW-aware LLM research, reviewing \total{unique_references} studies spanning five research areas, 12 NLP tasks, 30+ datasets, and 80+ languages. We classify recent advances by architecture, training strategy, and evaluation methodology, outlining how LLMs have reshaped CSW modeling and what challenges persist. The paper concludes with a roadmap emphasizing the need for inclusive datasets, fair evaluation, and linguistically grounded models to achieve truly multilingual intelligence. A curated collection of all resources is maintained at https://github.com/lingo-iitgn/awesome-code-mixing/.
Eka-Eval : A Comprehensive Evaluation Framework for Large Language Models in Indian Languages
Jul 02, 2025The rapid advancement of Large Language Models (LLMs) has intensified the need for evaluation frameworks that go beyond English centric benchmarks and address the requirements of linguistically diverse regions such as India. We present EKA-EVAL, a unified and production-ready evaluation framework that integrates over 35 benchmarks, including 10 Indic-specific datasets, spanning categories like reasoning, mathematics, tool use, long-context understanding, and reading comprehension. Compared to existing Indian language evaluation tools, EKA-EVAL offers broader benchmark coverage, with built-in support for distributed inference, quantization, and multi-GPU usage. Our systematic comparison positions EKA-EVAL as the first end-to-end, extensible evaluation suite tailored for both global and Indic LLMs, significantly lowering the barrier to multilingual benchmarking. The framework is open-source and publicly available at https://github.com/lingo-iitgn/ eka-eval and a part of ongoing EKA initiative (https://eka.soket.ai), which aims to scale up to over 100 benchmarks and establish a robust, multilingual evaluation ecosystem for LLMs.