 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Zero-Shot App Review Classification with ChatGPT: Challenges and Potential
May 07, 2025App reviews are a critical source of user feedback, offering valuable insights into an app's performance, features, usability, and overall user experience. Effectively analyzing these reviews is essential for guiding app development, prioritizing feature updates, and enhancing user satisfaction. Classifying reviews into functional and non-functional requirements play a pivotal role in distinguishing feedback related to specific app features (functional requirements) from feedback concerning broader quality attributes, such as performance, usability, and reliability (non-functional requirements). Both categories are integral to informed development decisions. Traditional approaches to classifying app reviews are hindered by the need for large, domain-specific datasets, which are often costly and time-consuming to curate. This study explores the potential of zero-shot learning with ChatGPT for classifying app reviews into four categories: functional requirement, non-functional requirement, both, or neither. We evaluate ChatGPT's performance on a benchmark dataset of 1,880 manually annotated reviews from ten diverse apps spanning multiple domains. Our findings demonstrate that ChatGPT achieves a robust F1 score of 0.842 in review classification, despite certain challenges and limitations. Additionally, we examine how factors such as review readability and length impact classification accuracy and conduct a manual analysis to identify review categories more prone to misclassification.
Generating Clarification Questions for Disambiguating Contracts
Mar 12, 2024



Enterprises frequently enter into commercial contracts that can serve as vital sources of project-specific requirements. Contractual clauses are obligatory, and the requirements derived from contracts can detail the downstream implementation activities that non-legal stakeholders, including requirement analysts, engineers, and delivery personnel, need to conduct. However, comprehending contracts is cognitively demanding and error-prone for such stakeholders due to the extensive use of Legalese and the inherent complexity of contract language. Furthermore, contracts often contain ambiguously worded clauses to ensure comprehensive coverage. In contrast, non-legal stakeholders require a detailed and unambiguous comprehension of contractual clauses to craft actionable requirements. In this work, we introduce a novel legal NLP task that involves generating clarification questions for contracts. These questions aim to identify contract ambiguities on a document level, thereby assisting non-legal stakeholders in obtaining the necessary details for eliciting requirements. This task is challenged by three core issues: (1) data availability, (2) the length and unstructured nature of contracts, and (3) the complexity of legal text. To address these issues, we propose ConRAP, a retrieval-augmented prompting framework for generating clarification questions to disambiguate contractual text. Experiments conducted on contracts sourced from the publicly available CUAD dataset show that ConRAP with ChatGPT can detect ambiguities with an F2 score of 0.87. 70% of the generated clarification questions are deemed useful by human evaluators.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
HINT3: Raising the bar for Intent Detection in the Wild
Oct 10, 2020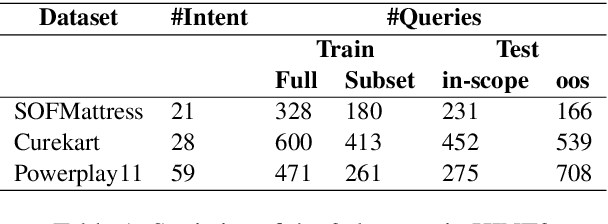
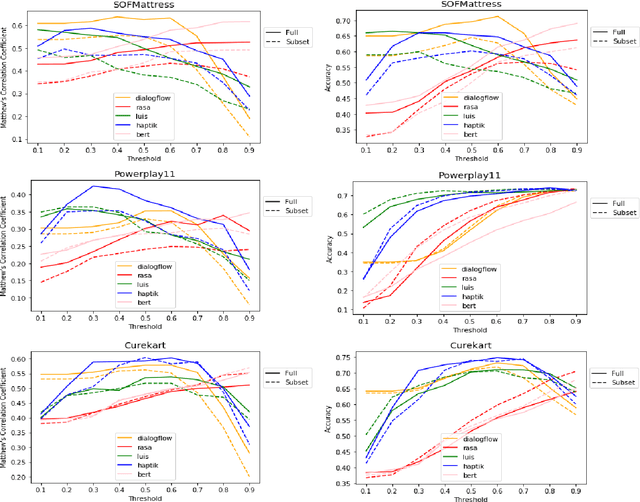
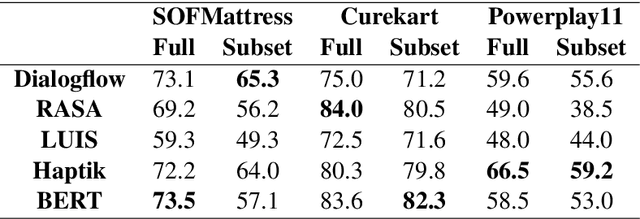
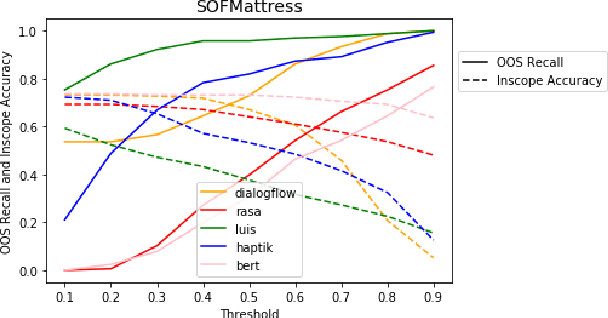
Intent Detection systems in the real world are exposed to complexities of imbalanced datasets containing varying perception of intent, unintended correlations and domain-specific aberrations. To facilitate benchmarking which can reflect near real-world scenarios, we introduce 3 new datasets created from live chatbots in diverse domains. Unlike most existing datasets that are crowdsourced, our datasets contain real user queries received by the chatbots and facilitates penalising unwanted correlations grasped during the training process. We evaluate 4 NLU platforms and a BERT based classifier and find that performance saturates at inadequate levels on test sets because all systems latch on to unintended patterns in training data.
A Machine Learning Application for Raising WASH Awareness in the Times of COVID-19 Pandemic
Apr 18, 2020
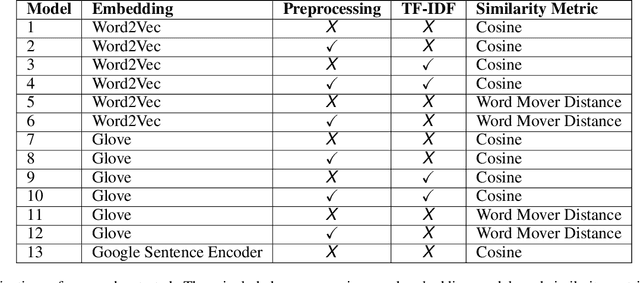
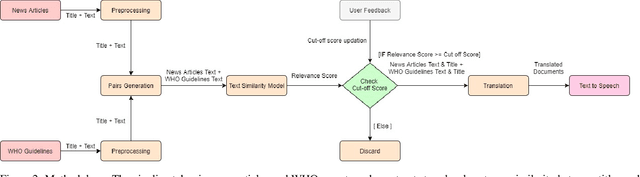
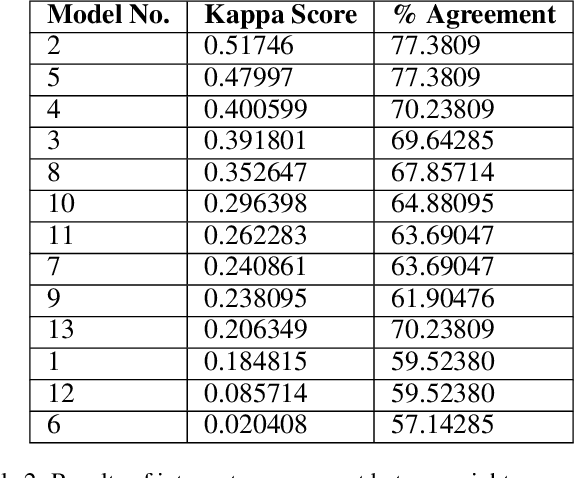
Proactive management of an Infodemic that grows faster than the underlying epidemic is a modern-day challenge. This requires raising awareness and sensitization with the correct information in order to prevent and contain outbreaks such as the ongoing COVID-19 pandemic. Therefore, there is a fine balance between continuous awareness-raising by providing new information and the risk of misinformation. In this work, we address this gap by creating a life-long learning application that delivers authentic information to users in Hindi and English, the most widely used languages in India. It does this by matching sources of verified and authentic information such as the WHO reports against daily news by using machine learning and natural language processing. It delivers the narrated content in Hindi by using state-of-the-art text to speech engines. Finally, the approach allows user input for continuous improvement of news feed relevance daily. We demonstrate this approach for Water, Sanitation, Hygiene information for containment of the COVID-19 pandemic. Thirteen combinations of pre-processing strategies, word-embeddings, and similarity metrics were evaluated by eight human users via calculation of agreement statistics. The best performing combination achieved a Cohen's Kappa of 0.54 and was deployed as On AIr, WashKaro's AI-powered back-end. We introduced a novel way of contact tracing, deploying the Bluetooth sensors of an individual's smartphone and automatic recording of physical interactions with other users. Additionally, the application also features a symptom self-assessment tool based on WHO-approved guidelines, human-curated and vetted information to reach out to the community as audio-visual content in local languages. WashKaro - http://tiny.cc/WashKaro
Exploring the importance of context and embeddings in neural NER models for task-oriented dialogue systems
Dec 06, 2018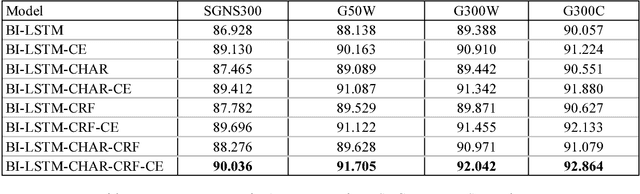
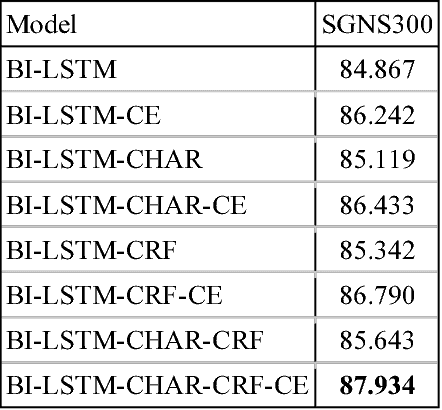
Named Entity Recognition (NER), a classic sequence labelling task, is an essential component of natural language understanding (NLU) systems in task-oriented dialog systems for slot filling. For well over a decade, different methods from lookup using gazetteers and domain ontology, classifiers over handcrafted features to end-to-end systems involving neural network architectures have been evaluated mostly in language-independent non-conversational settings. In this paper, we evaluate a modified version of the recent state of the art neural architecture in a conversational setting where messages are often short and noisy. We perform an array of experiments with different combinations of including the previous utterance in the dialogue as a source of additional features and using word and character level embeddings trained on a larger external corpus. All methods are evaluated on a combined dataset formed from two public English task-oriented conversational datasets belonging to travel and restaurant domains respectively. For additional evaluation, we also repeat some of our experiments after adding automatically translated and transliterated (from translated) versions to the English only dataset.
Production Ready Chatbots: Generate if not Retrieve
Nov 27, 2017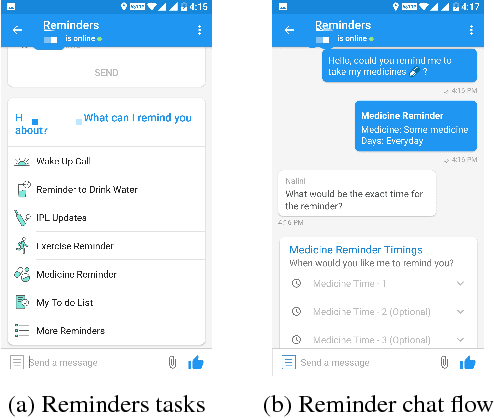
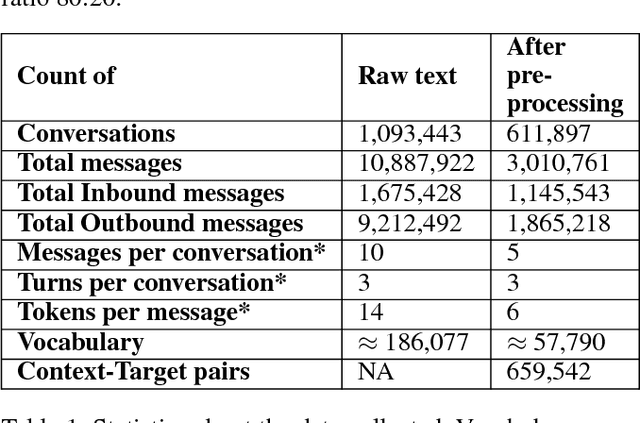


In this paper, we present a hybrid model that combines a neural conversational model and a rule-based graph dialogue system that assists users in scheduling reminders through a chat conversation. The graph based system has high precision and provides a grammatically accurate response but has a low recall. The neural conversation model can cater to a variety of requests, as it generates the responses word by word as opposed to using canned responses. The hybrid system shows significant improvements over the existing baseline system of rule based approach and caters to complex queries with a domain-restricted neural model. Restricting the conversation topic and combination of graph based retrieval system with a neural generative model makes the final system robust enough for a real world application.