 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
Feb 18, 2025



As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, including on tasks like machine translation (MT). In this work, we extend the WMT24 dataset to cover 55 languages by collecting new human-written references and post-edits for 46 new languages and dialects in addition to post-edits of the references in 8 out of 9 languages in the original WMT24 dataset. The dataset covers four domains: literary, news, social, and speech. We benchmark a variety of MT providers and LLMs on the collected dataset using automatic metrics and find that LLMs are the best-performing MT systems in all 55 languages. These results should be confirmed using a human-based evaluation, which we leave for future work.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Jun 06, 2024



Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
* LREC-COLING2024 publication (with corrections for Table 3)
Text Rendering Strategies for Pixel Language Models
Nov 01, 2023



Pixel-based language models process text rendered as images, which allows them to handle any script, making them a promising approach to open vocabulary language modelling. However, recent approaches use text renderers that produce a large set of almost-equivalent input patches, which may prove sub-optimal for downstream tasks, due to redundancy in the input representations. In this paper, we investigate four approaches to rendering text in the PIXEL model (Rust et al., 2023), and find that simple character bigram rendering brings improved performance on sentence-level tasks without compromising performance on token-level or multilingual tasks. This new rendering strategy also makes it possible to train a more compact model with only 22M parameters that performs on par with the original 86M parameter model. Our analyses show that character bigram rendering leads to a consistently better model but with an anisotropic patch embedding space, driven by a patch frequency bias, highlighting the connections between image patch- and tokenization-based language models.
Pixel Representations for Multilingual Translation and Data-efficient Cross-lingual Transfer
May 23, 2023We introduce and demonstrate how to effectively train multilingual machine translation models with pixel representations. We experiment with two different data settings with a variety of language and script coverage, and show performance competitive with subword embeddings. We analyze various properties of pixel representations to better understand where they provide potential benefits and the impact of different scripts and data representations. We observe that these properties not only enable seamless cross-lingual transfer to unseen scripts, but make pixel representations more data-efficient than alternatives such as vocabulary expansion. We hope this work contributes to more extensible multilingual models for all languages and scripts.
A Holistic Cascade System, benchmark, and Human Evaluation Protocol for Expressive Speech-to-Speech Translation
Jan 25, 2023



Expressive speech-to-speech translation (S2ST) aims to transfer prosodic attributes of source speech to target speech while maintaining translation accuracy. Existing research in expressive S2ST is limited, typically focusing on a single expressivity aspect at a time. Likewise, this research area lacks standard evaluation protocols and well-curated benchmark datasets. In this work, we propose a holistic cascade system for expressive S2ST, combining multiple prosody transfer techniques previously considered only in isolation. We curate a benchmark expressivity test set in the TV series domain and explored a second dataset in the audiobook domain. Finally, we present a human evaluation protocol to assess multiple expressive dimensions across speech pairs. Experimental results indicate that bi-lingual annotators can assess the quality of expressive preservation in S2ST systems, and the holistic modeling approach outperforms single-aspect systems. Audio samples can be accessed through our demo webpage: https://facebookresearch.github.io/speech_translation/cascade_expressive_s2st.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Language Modelling with Pixels
Jul 14, 2022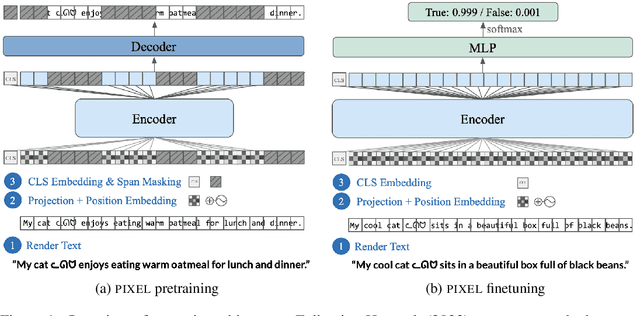
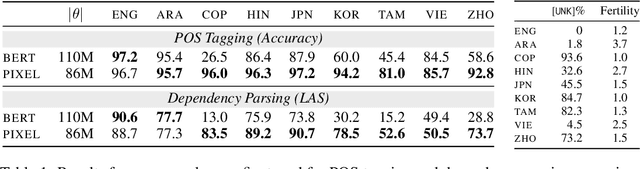


Language models are defined over a finite set of inputs, which creates a vocabulary bottleneck when we attempt to scale the number of supported languages. Tackling this bottleneck results in a trade-off between what can be represented in the embedding matrix and computational issues in the output layer. This paper introduces PIXEL, the Pixel-based Encoder of Language, which suffers from neither of these issues. PIXEL is a pretrained language model that renders text as images, making it possible to transfer representations across languages based on orthographic similarity or the co-activation of pixels. PIXEL is trained to reconstruct the pixels of masked patches, instead of predicting a distribution over tokens. We pretrain the 86M parameter PIXEL model on the same English data as BERT and evaluate on syntactic and semantic tasks in typologically diverse languages, including various non-Latin scripts. We find that PIXEL substantially outperforms BERT on syntactic and semantic processing tasks on scripts that are not found in the pretraining data, but PIXEL is slightly weaker than BERT when working with Latin scripts. Furthermore, we find that PIXEL is more robust to noisy text inputs than BERT, further confirming the benefits of modelling language with pixels.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022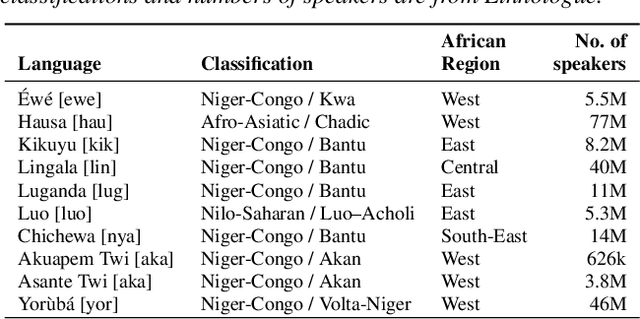
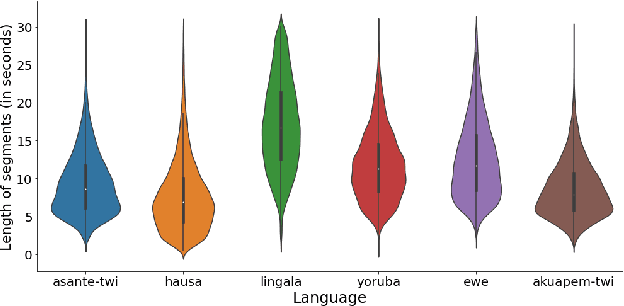
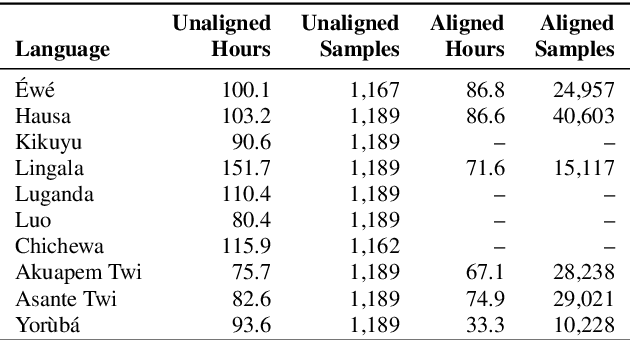
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.