 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023



As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Masader Plus: A New Interface for Exploring +500 Arabic NLP Datasets
Aug 01, 2022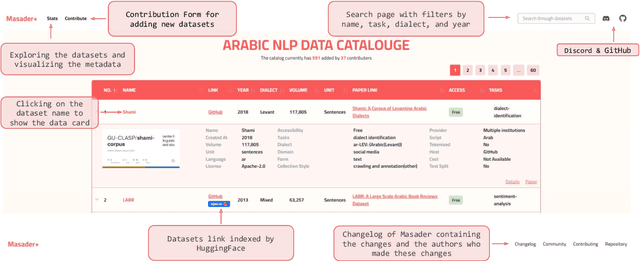
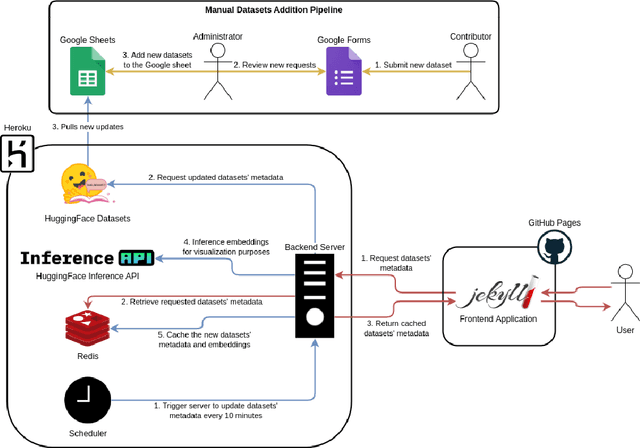
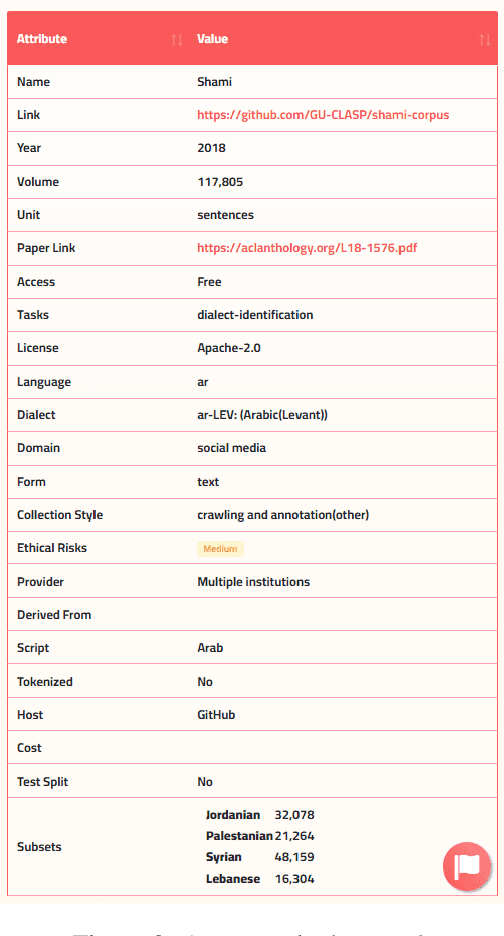
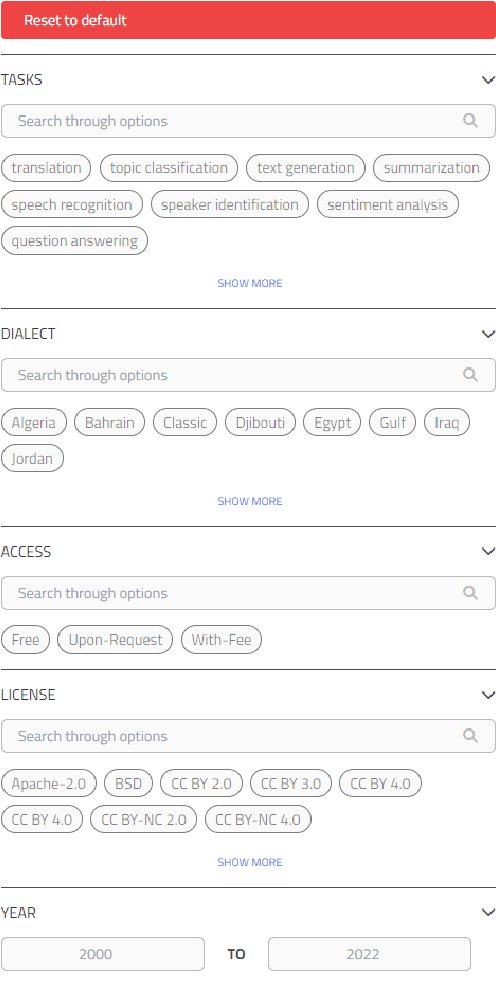
Masader (Alyafeai et al., 2021) created a metadata structure to be used for cataloguing Arabic NLP datasets. However, developing an easy way to explore such a catalogue is a challenging task. In order to give the optimal experience for users and researchers exploring the catalogue, several design and user experience challenges must be resolved. Furthermore, user interactions with the website may provide an easy approach to improve the catalogue. In this paper, we introduce Masader Plus, a web interface for users to browse Masader. We demonstrate data exploration, filtration, and a simple API that allows users to examine datasets from the backend. Masader Plus can be explored using this link https://arbml.github.io/masader. A video recording explaining the interface can be found here https://www.youtube.com/watch?v=SEtdlSeqchk.
Documenting Geographically and Contextually Diverse Data Sources: The BigScience Catalogue of Language Data and Resources
Jan 25, 2022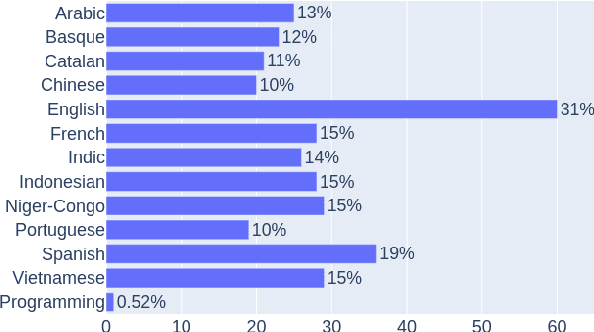
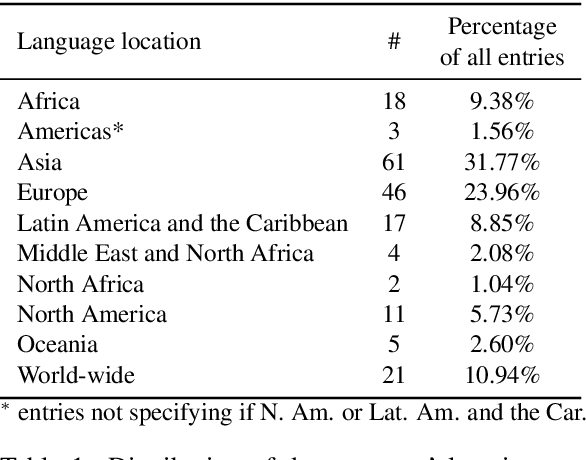
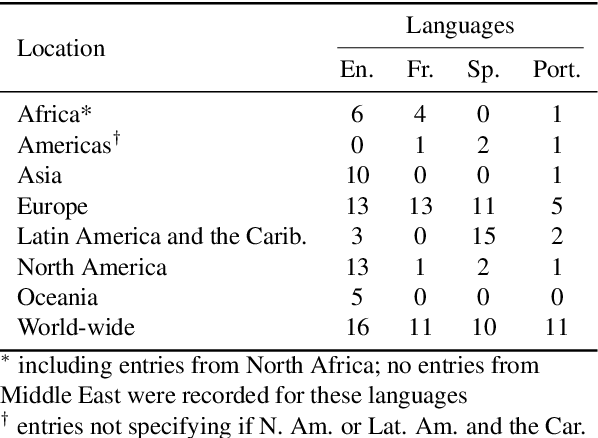
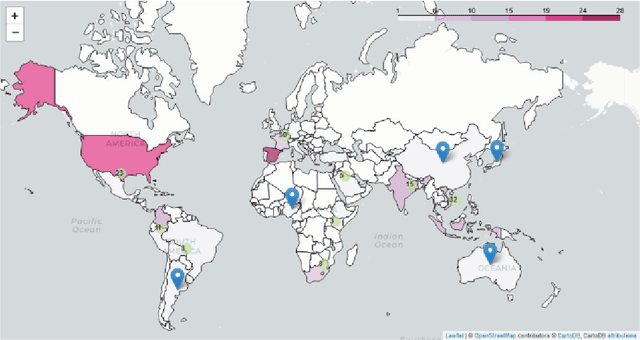
In recent years, large-scale data collection efforts have prioritized the amount of data collected in order to improve the modeling capabilities of large language models. This prioritization, however, has resulted in concerns with respect to the rights of data subjects represented in data collections, particularly when considering the difficulty in interrogating these collections due to insufficient documentation and tools for analysis. Mindful of these pitfalls, we present our methodology for a documentation-first, human-centered data collection project as part of the BigScience initiative. We identified a geographically diverse set of target language groups (Arabic, Basque, Chinese, Catalan, English, French, Indic languages, Indonesian, Niger-Congo languages, Portuguese, Spanish, and Vietnamese, as well as programming languages) for which to collect metadata on potential data sources. To structure this effort, we developed our online catalogue as a supporting tool for gathering metadata through organized public hackathons. We present our development process; analyses of the resulting resource metadata, including distributions over languages, regions, and resource types; and our lessons learned in this endeavor.
Masader: Metadata Sourcing for Arabic Text and Speech Data Resources
Oct 13, 2021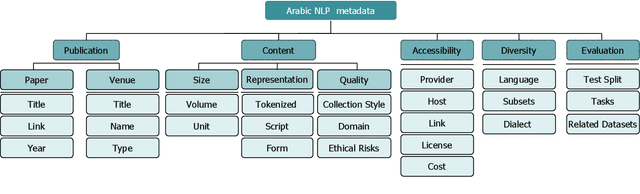
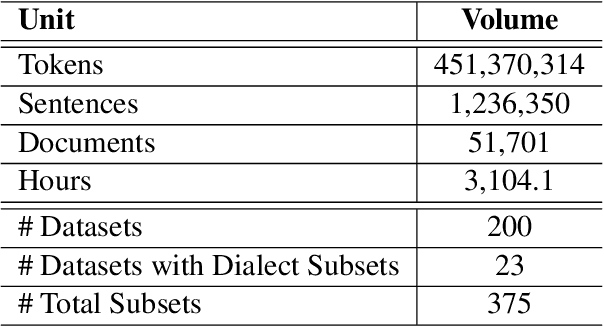
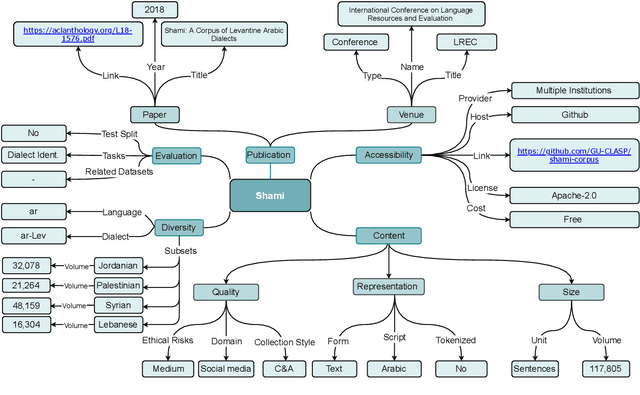
The NLP pipeline has evolved dramatically in the last few years. The first step in the pipeline is to find suitable annotated datasets to evaluate the tasks we are trying to solve. Unfortunately, most of the published datasets lack metadata annotations that describe their attributes. Not to mention, the absence of a public catalogue that indexes all the publicly available datasets related to specific regions or languages. When we consider low-resource dialectical languages, for example, this issue becomes more prominent. In this paper we create \textit{Masader}, the largest public catalogue for Arabic NLP datasets, which consists of 200 datasets annotated with 25 attributes. Furthermore, We develop a metadata annotation strategy that could be extended to other languages. We also make remarks and highlight some issues about the current status of Arabic NLP datasets and suggest recommendations to address them.
Aspects of Terminological and Named Entity Knowledge within Rule-Based Machine Translation Models for Under-Resourced Neural Machine Translation Scenarios
Sep 28, 2020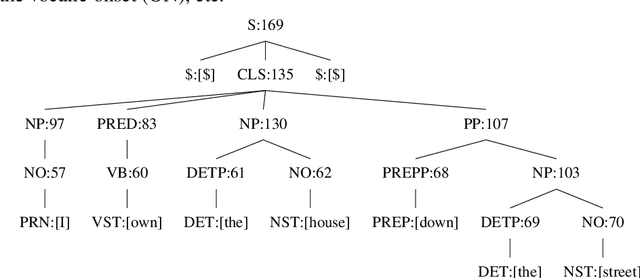
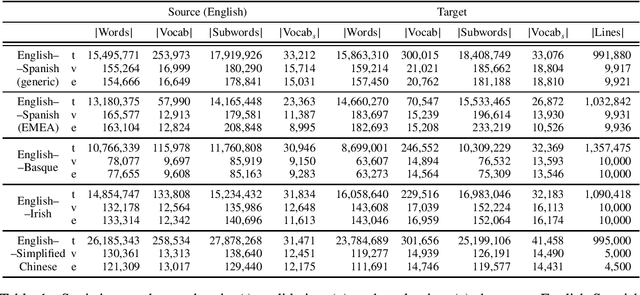
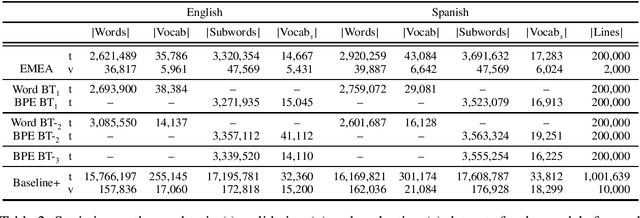

Rule-based machine translation is a machine translation paradigm where linguistic knowledge is encoded by an expert in the form of rules that translate text from source to target language. While this approach grants extensive control over the output of the system, the cost of formalising the needed linguistic knowledge is much higher than training a corpus-based system, where a machine learning approach is used to automatically learn to translate from examples. In this paper, we describe different approaches to leverage the information contained in rule-based machine translation systems to improve a corpus-based one, namely, a neural machine translation model, with a focus on a low-resource scenario. Three different kinds of information were used: morphological information, named entities and terminology. In addition to evaluating the general performance of the system, we systematically analysed the performance of the proposed approaches when dealing with the targeted phenomena. Our results suggest that the proposed models have limited ability to learn from external information, and most approaches do not significantly alter the results of the automatic evaluation, but our preliminary qualitative evaluation shows that in certain cases the hypothesis generated by our system exhibit favourable behaviour such as keeping the use of passive voice.