 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
Reassessing Graph Linearization for Sequence-to-sequence AMR Parsing: On the Advantages and Limitations of Triple-Based Encoding
May 13, 2025Sequence-to-sequence models are widely used to train Abstract Meaning Representation (Banarescu et al., 2013, AMR) parsers. To train such models, AMR graphs have to be linearized into a one-line text format. While Penman encoding is typically used for this purpose, we argue that it has limitations: (1) for deep graphs, some closely related nodes are located far apart in the linearized text (2) Penman's tree-based encoding necessitates inverse roles to handle node re-entrancy, doubling the number of relation types to predict. To address these issues, we propose a triple-based linearization method and compare its efficiency with Penman linearization. Although triples are well suited to represent a graph, our results suggest room for improvement in triple encoding to better compete with Penman's concise and explicit representation of a nested graph structure.
Should Cross-Lingual AMR Parsing go Meta? An Empirical Assessment of Meta-Learning and Joint Learning AMR Parsing
Oct 04, 2024Cross-lingual AMR parsing is the task of predicting AMR graphs in a target language when training data is available only in a source language. Due to the small size of AMR training data and evaluation data, cross-lingual AMR parsing has only been explored in a small set of languages such as English, Spanish, German, Chinese, and Italian. Taking inspiration from Langedijk et al. (2022), who apply meta-learning to tackle cross-lingual syntactic parsing, we investigate the use of meta-learning for cross-lingual AMR parsing. We evaluate our models in $k$-shot scenarios (including 0-shot) and assess their effectiveness in Croatian, Farsi, Korean, Chinese, and French. Notably, Korean and Croatian test sets are developed as part of our work, based on the existing The Little Prince English AMR corpus, and made publicly available. We empirically study our method by comparing it to classical joint learning. Our findings suggest that while the meta-learning model performs slightly better in 0-shot evaluation for certain languages, the performance gain is minimal or absent when $k$ is higher than 0.
Growing Trees on Sounds: Assessing Strategies for End-to-End Dependency Parsing of Speech
Jun 18, 2024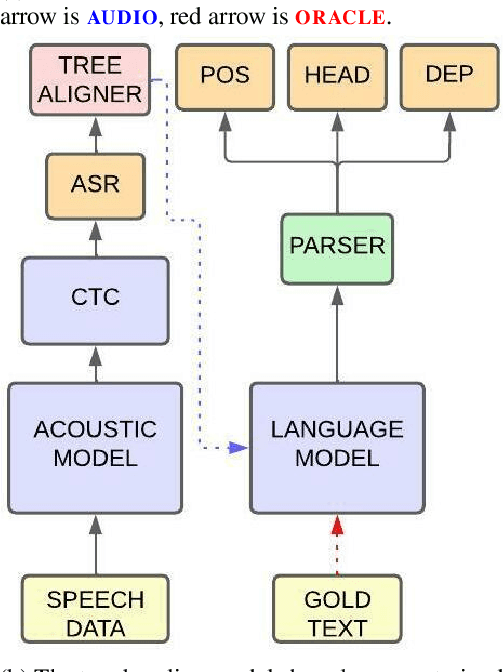
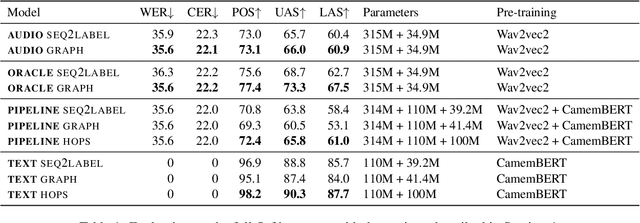
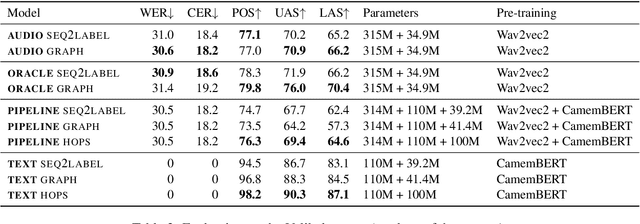
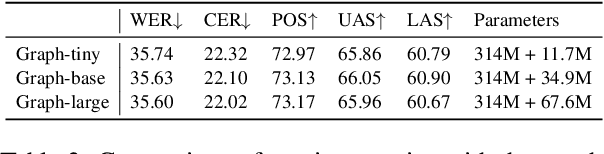
Direct dependency parsing of the speech signal -- as opposed to parsing speech transcriptions -- has recently been proposed as a task (Pupier et al. 2022), as a way of incorporating prosodic information in the parsing system and bypassing the limitations of a pipeline approach that would consist of using first an Automatic Speech Recognition (ASR) system and then a syntactic parser. In this article, we report on a set of experiments aiming at assessing the performance of two parsing paradigms (graph-based parsing and sequence labeling based parsing) on speech parsing. We perform this evaluation on a large treebank of spoken French, featuring realistic spontaneous conversations. Our findings show that (i) the graph based approach obtain better results across the board (ii) parsing directly from speech outperforms a pipeline approach, despite having 30% fewer parameters.
What has LeBenchmark Learnt about French Syntax?
Mar 04, 2024



The paper reports on a series of experiments aiming at probing LeBenchmark, a pretrained acoustic model trained on 7k hours of spoken French, for syntactic information. Pretrained acoustic models are increasingly used for downstream speech tasks such as automatic speech recognition, speech translation, spoken language understanding or speech parsing. They are trained on very low level information (the raw speech signal), and do not have explicit lexical knowledge. Despite that, they obtained reasonable results on tasks that requires higher level linguistic knowledge. As a result, an emerging question is whether these models encode syntactic information. We probe each representation layer of LeBenchmark for syntax, using the Orf\'eo treebank, and observe that it has learnt some syntactic information. Our results show that syntactic information is more easily extractable from the middle layers of the network, after which a very sharp decrease is observed.
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
BERT is not The Count: Learning to Match Mathematical Statements with Proofs
Feb 18, 2023We introduce a task consisting in matching a proof to a given mathematical statement. The task fits well within current research on Mathematical Information Retrieval and, more generally, mathematical article analysis (Mathematical Sciences, 2014). We present a dataset for the task (the MATcH dataset) consisting of over 180k statement-proof pairs extracted from modern mathematical research articles. We find this dataset highly representative of our task, as it consists of relatively new findings useful to mathematicians. We propose a bilinear similarity model and two decoding methods to match statements to proofs effectively. While the first decoding method matches a proof to a statement without being aware of other statements or proofs, the second method treats the task as a global matching problem. Through a symbol replacement procedure, we analyze the "insights" that pre-trained language models have in such mathematical article analysis and show that while these models perform well on this task with the best performing mean reciprocal rank of 73.7, they follow a relatively shallow symbolic analysis and matching to achieve that performance.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Learning to Match Mathematical Statements with Proofs
Feb 03, 2021
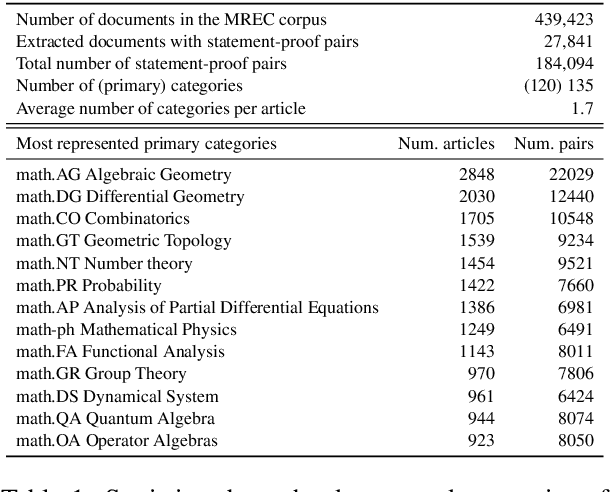
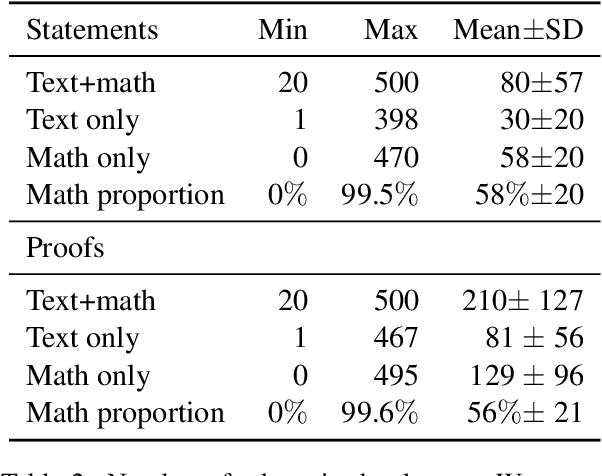
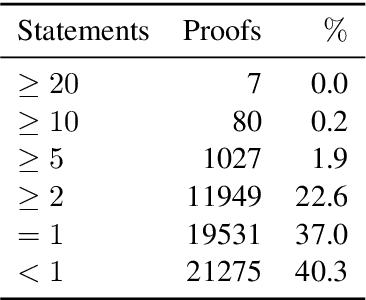
We introduce a novel task consisting in assigning a proof to a given mathematical statement. The task is designed to improve the processing of research-level mathematical texts. Applying Natural Language Processing (NLP) tools to research level mathematical articles is both challenging, since it is a highly specialized domain which mixes natural language and mathematical formulae. It is also an important requirement for developing tools for mathematical information retrieval and computer-assisted theorem proving. We release a dataset for the task, consisting of over 180k statement-proof pairs extracted from mathematical research articles. We carry out preliminary experiments to assess the difficulty of the task. We first experiment with two bag-of-words baselines. We show that considering the assignment problem globally and using weighted bipartite matching algorithms helps a lot in tackling the task. Finally, we introduce a self-attention-based model that can be trained either locally or globally and outperforms baselines by a wide margin.
Self-Supervised and Controlled Multi-Document Opinion Summarization
May 01, 2020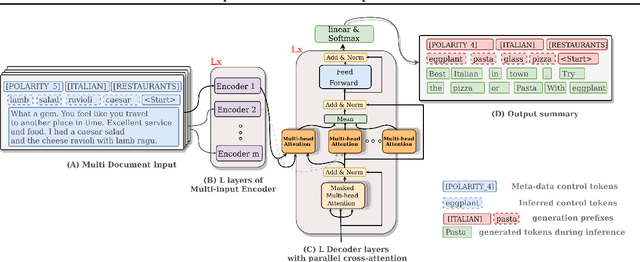
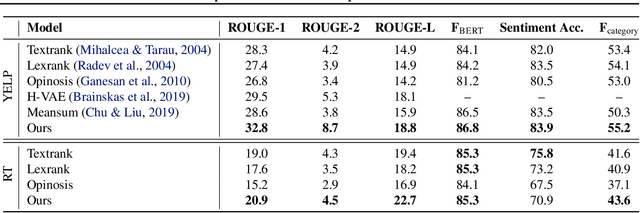
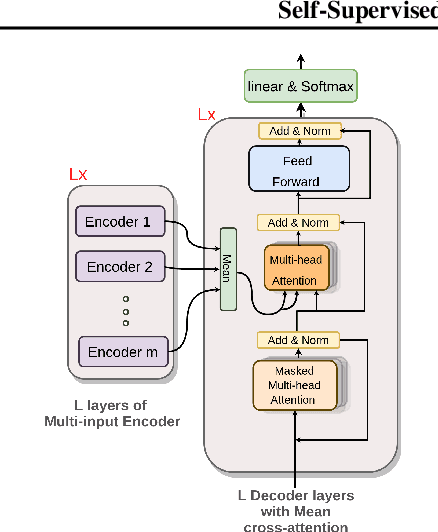
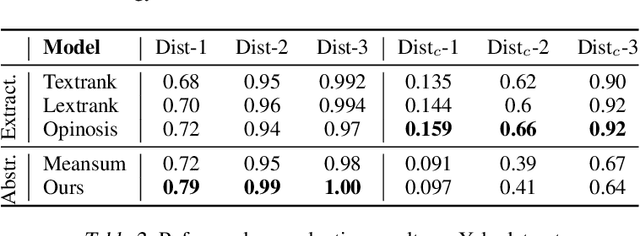
We address the problem of unsupervised abstractive summarization of collections of user generated reviews with self-supervision and control. We propose a self-supervised setup that considers an individual document as a target summary for a set of similar documents. This setting makes training simpler than previous approaches by relying only on standard log-likelihood loss. We address the problem of hallucinations through the use of control codes, to steer the generation towards more coherent and relevant summaries.Finally, we extend the Transformer architecture to allow for multiple reviews as input. Our benchmarks on two datasets against graph-based and recent neural abstractive unsupervised models show that our proposed method generates summaries with a superior quality and relevance.This is confirmed in our human evaluation which focuses explicitly on the faithfulness of generated summaries We also provide an ablation study, which shows the importance of the control setup in controlling hallucinations and achieve high sentiment and topic alignment of the summaries with the input reviews.