 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Falcon Series of Open Language Models
Nov 29, 2023



We introduce the Falcon series: 7B, 40B, and 180B parameters causal decoder-only models trained on a diverse high-quality corpora predominantly assembled from web data. The largest model, Falcon-180B, has been trained on over 3.5 trillion tokens of text--the largest openly documented pretraining run. Falcon-180B significantly outperforms models such as PaLM or Chinchilla, and improves upon concurrently developed models such as LLaMA 2 or Inflection-1. It nears the performance of PaLM-2-Large at a reduced pretraining and inference cost, making it, to our knowledge, one of the three best language models in the world along with GPT-4 and PaLM-2-Large. We report detailed evaluations, as well as a deep dive into the methods and custom tooling employed to pretrain Falcon. Notably, we report on our custom distributed training codebase, allowing us to efficiently pretrain these models on up to 4,096 A100s on cloud AWS infrastructure with limited interconnect. We release a 600B tokens extract of our web dataset, as well as the Falcon-7/40/180B models under a permissive license to foster open-science and accelerate the development of an open ecosystem of large language models.
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
Jun 01, 2023



Large language models are commonly trained on a mixture of filtered web data and curated high-quality corpora, such as social media conversations, books, or technical papers. This curation process is believed to be necessary to produce performant models with broad zero-shot generalization abilities. However, as larger models requiring pretraining on trillions of tokens are considered, it is unclear how scalable is curation and whether we will run out of unique high-quality data soon. At variance with previous beliefs, we show that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models from the state-of-the-art trained on The Pile. Despite extensive filtering, the high-quality data we extract from the web is still plentiful, and we are able to obtain five trillion tokens from CommonCrawl. We publicly release an extract of 600 billion tokens from our RefinedWeb dataset, and 1.3/7.5B parameters language models trained on it.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
What Language Model to Train if You Have One Million GPU Hours?
Nov 08, 2022



The crystallization of modeling methods around the Transformer architecture has been a boon for practitioners. Simple, well-motivated architectural variations can transfer across tasks and scale, increasing the impact of modeling research. However, with the emergence of state-of-the-art 100B+ parameters models, large language models are increasingly expensive to accurately design and train. Notably, it can be difficult to evaluate how modeling decisions may impact emergent capabilities, given that these capabilities arise mainly from sheer scale alone. In the process of building BLOOM--the Big Science Large Open-science Open-access Multilingual language model--our goal is to identify an architecture and training setup that makes the best use of our 1,000,000 A100-GPU-hours budget. Specifically, we perform an ablation study at the billion-parameter scale comparing different modeling practices and their impact on zero-shot generalization. In addition, we study the impact of various popular pre-training corpora on zero-shot generalization. We also study the performance of a multilingual model and how it compares to the English-only one. Finally, we consider the scaling behaviour of Transformers to choose the target model size, shape, and training setup. All our models and code are open-sourced at https://huggingface.co/bigscience .
Scaling Laws Beyond Backpropagation
Oct 26, 2022



Alternatives to backpropagation have long been studied to better understand how biological brains may learn. Recently, they have also garnered interest as a way to train neural networks more efficiently. By relaxing constraints inherent to backpropagation (e.g., symmetric feedforward and feedback weights, sequential updates), these methods enable promising prospects, such as local learning. However, the tradeoffs between different methods in terms of final task performance, convergence speed, and ultimately compute and data requirements are rarely outlined. In this work, we use scaling laws to study the ability of Direct Feedback Alignment~(DFA) to train causal decoder-only Transformers efficiently. Scaling laws provide an overview of the tradeoffs implied by a modeling decision, up to extrapolating how it might transfer to increasingly large models. We find that DFA fails to offer more efficient scaling than backpropagation: there is never a regime for which the degradation in loss incurred by using DFA is worth the potential reduction in compute budget. Our finding comes at variance with previous beliefs in the alternative training methods community, and highlights the need for holistic empirical approaches to better understand modeling decisions.
RITA: a Study on Scaling Up Generative Protein Sequence Models
May 11, 2022
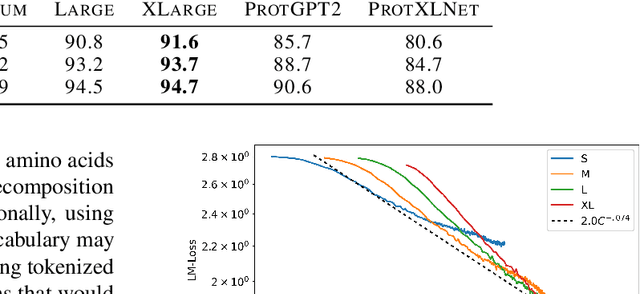


In this work we introduce RITA: a suite of autoregressive generative models for protein sequences, with up to 1.2 billion parameters, trained on over 280 million protein sequences belonging to the UniRef-100 database. Such generative models hold the promise of greatly accelerating protein design. We conduct the first systematic study of how capabilities evolve with model size for autoregressive transformers in the protein domain: we evaluate RITA models in next amino acid prediction, zero-shot fitness, and enzyme function prediction, showing benefits from increased scale. We release the RITA models openly, to the benefit of the research community.
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
Apr 12, 2022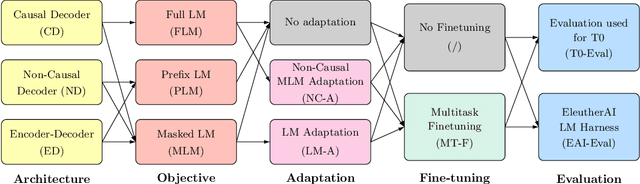
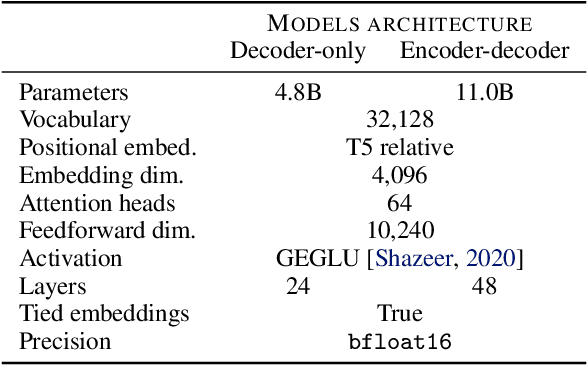
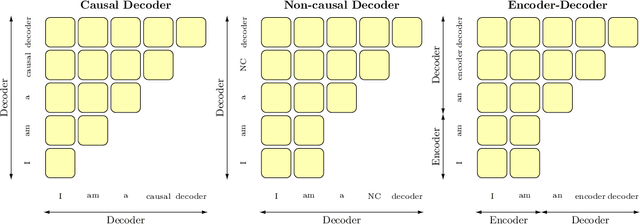

Large pretrained Transformer language models have been shown to exhibit zero-shot generalization, i.e. they can perform a wide variety of tasks that they were not explicitly trained on. However, the architectures and pretraining objectives used across state-of-the-art models differ significantly, and there has been limited systematic comparison of these factors. In this work, we present a large-scale evaluation of modeling choices and their impact on zero-shot generalization. In particular, we focus on text-to-text models and experiment with three model architectures (causal/non-causal decoder-only and encoder-decoder), trained with two different pretraining objectives (autoregressive and masked language modeling), and evaluated with and without multitask prompted finetuning. We train models with over 5 billion parameters for more than 170 billion tokens, thereby increasing the likelihood that our conclusions will transfer to even larger scales. Our experiments show that causal decoder-only models trained on an autoregressive language modeling objective exhibit the strongest zero-shot generalization after purely unsupervised pretraining. However, models with non-causal visibility on their input trained with a masked language modeling objective followed by multitask finetuning perform the best among our experiments. We therefore consider the adaptation of pretrained models across architectures and objectives. We find that pretrained non-causal decoder models can be adapted into performant generative causal decoder models, using autoregressive language modeling as a downstream task. Furthermore, we find that pretrained causal decoder models can be efficiently adapted into non-causal decoder models, ultimately achieving competitive performance after multitask finetuning. Code and checkpoints are available at https://github.com/bigscience-workshop/architecture-objective.
Is the Number of Trainable Parameters All That Actually Matters?
Sep 24, 2021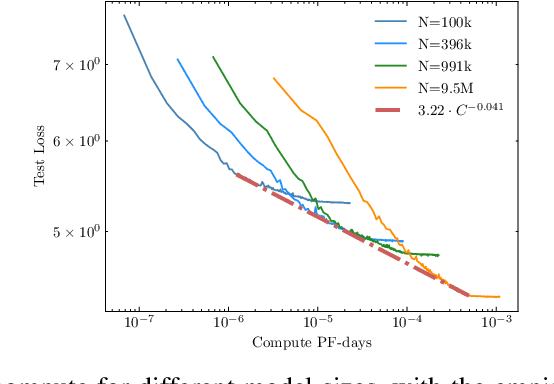
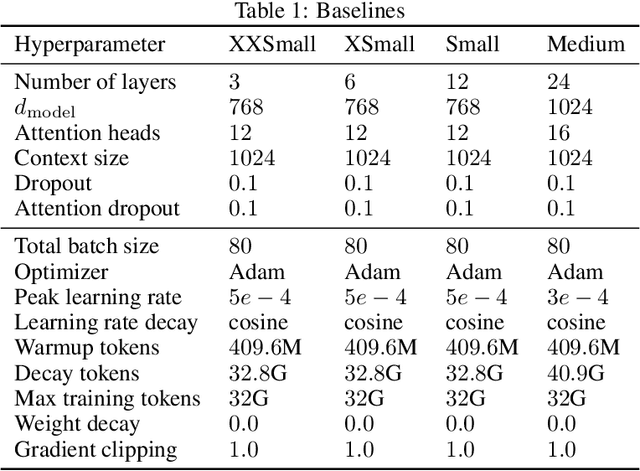
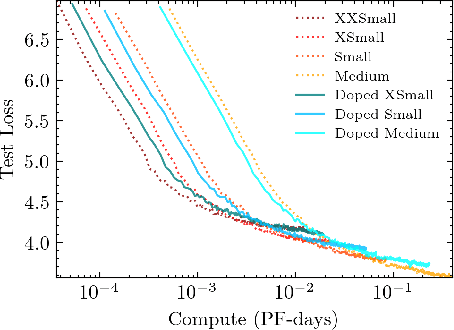
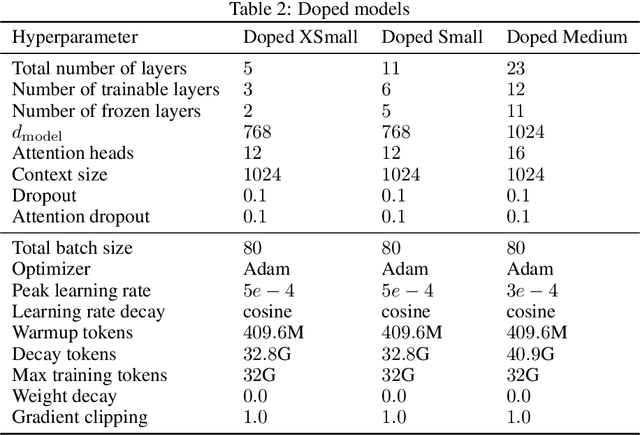
Recent work has identified simple empirical scaling laws for language models, linking compute budget, dataset size, model size, and autoregressive modeling loss. The validity of these simple power laws across orders of magnitude in model scale provides compelling evidence that larger models are also more capable models. However, scaling up models under the constraints of hardware and infrastructure is no easy feat, and rapidly becomes a hard and expensive engineering problem. We investigate ways to tentatively cheat scaling laws, and train larger models for cheaper. We emulate an increase in effective parameters, using efficient approximations: either by doping the models with frozen random parameters, or by using fast structured transforms in place of dense linear layers. We find that the scaling relationship between test loss and compute depends only on the actual number of trainable parameters; scaling laws cannot be deceived by spurious parameters.
Photonic co-processors in HPC: using LightOn OPUs for Randomized Numerical Linear Algebra
May 07, 2021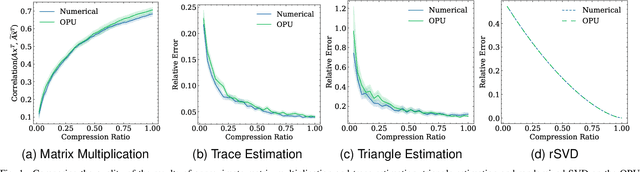
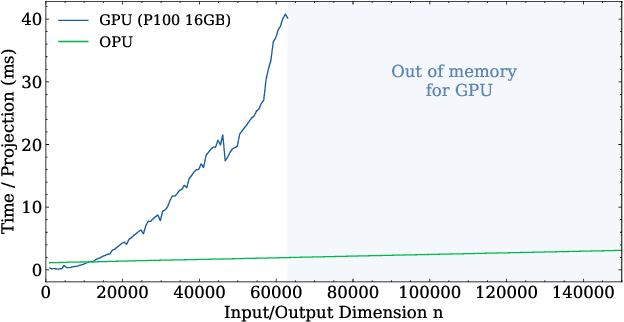
Randomized Numerical Linear Algebra (RandNLA) is a powerful class of methods, widely used in High Performance Computing (HPC). RandNLA provides approximate solutions to linear algebra functions applied to large signals, at reduced computational costs. However, the randomization step for dimensionality reduction may itself become the computational bottleneck on traditional hardware. Leveraging near constant-time linear random projections delivered by LightOn Optical Processing Units we show that randomization can be significantly accelerated, at negligible precision loss, in a wide range of important RandNLA algorithms, such as RandSVD or trace estimators.
Contrastive Embeddings for Neural Architectures
Feb 08, 2021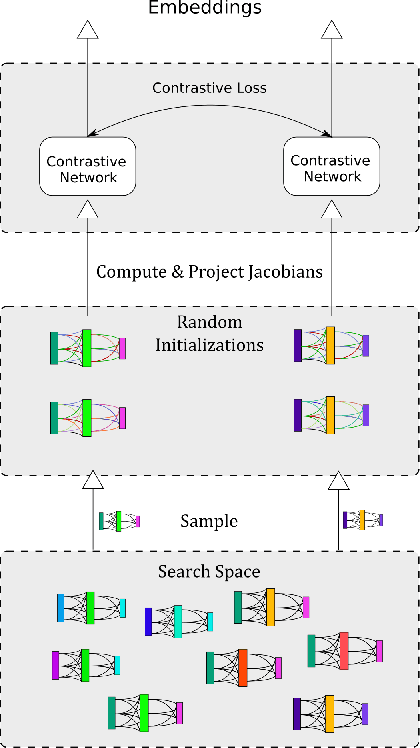

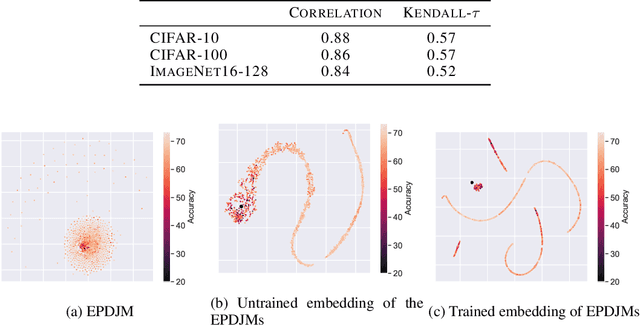
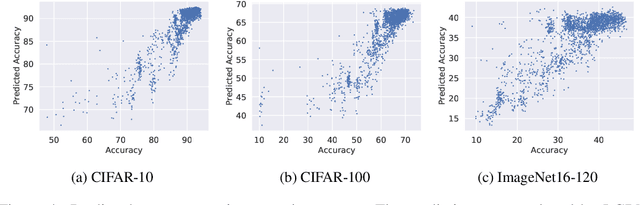
The performance of algorithms for neural architecture search strongly depends on the parametrization of the search space. We use contrastive learning to identify networks across different initializations based on their data Jacobians, and automatically produce the first architecture embeddings independent from the parametrization of the search space. Using our contrastive embeddings, we show that traditional black-box optimization algorithms, without modification, can reach state-of-the-art performance in Neural Architecture Search. As our method provides a unified embedding space, we perform for the first time transfer learning between search spaces. Finally, we show the evolution of embeddings during training, motivating future studies into using embeddings at different training stages to gain a deeper understanding of the networks in a search space.