 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Translationese in Low-resource Languages: The Storyboard Approach
Jul 14, 2024Low-resource languages often face challenges in acquiring high-quality language data due to the reliance on translation-based methods, which can introduce the translationese effect. This phenomenon results in translated sentences that lack fluency and naturalness in the target language. In this paper, we propose a novel approach for data collection by leveraging storyboards to elicit more fluent and natural sentences. Our method involves presenting native speakers with visual stimuli in the form of storyboards and collecting their descriptions without direct exposure to the source text. We conducted a comprehensive evaluation comparing our storyboard-based approach with traditional text translation-based methods in terms of accuracy and fluency. Human annotators and quantitative metrics were used to assess translation quality. The results indicate a preference for text translation in terms of accuracy, while our method demonstrates worse accuracy but better fluency in the language focused.
* published at LREC-COLING 2024
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Ìtàkúròso: Exploiting Cross-Lingual Transferability for Natural Language Generation of Dialogues in Low-Resource, African Languages
Apr 17, 2022
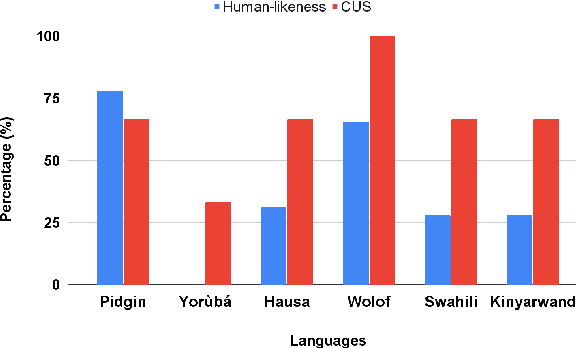
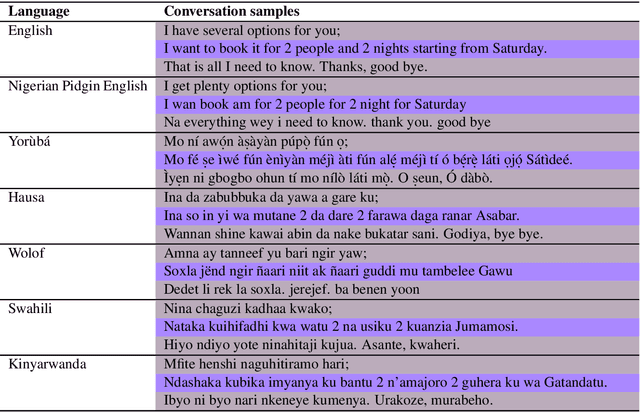
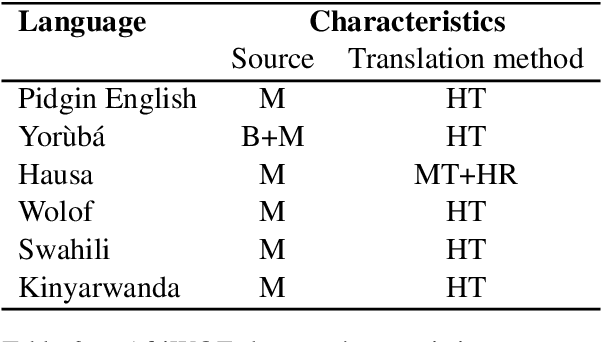
We investigate the possibility of cross-lingual transfer from a state-of-the-art (SoTA) deep monolingual model (DialoGPT) to 6 African languages and compare with 2 baselines (BlenderBot 90M, another SoTA, and a simple Seq2Seq). The languages are Swahili, Wolof, Hausa, Nigerian Pidgin English, Kinyarwanda & Yor\`ub\'a. Generation of dialogues is known to be a challenging task for many reasons. It becomes more challenging for African languages which are low-resource in terms of data. Therefore, we translate a small portion of the English multi-domain MultiWOZ dataset for each target language. Besides intrinsic evaluation (i.e. perplexity), we conduct human evaluation of single-turn conversations by using majority votes and measure inter-annotator agreement (IAA). The results show that the hypothesis that deep monolingual models learn some abstractions that generalise across languages holds. We observe human-like conversations in 5 out of the 6 languages. It, however, applies to different degrees in different languages, which is expected. The language with the most transferable properties is the Nigerian Pidgin English, with a human-likeness score of 78.1%, of which 34.4% are unanimous. The main contributions of this paper include the representation (through the provision of high-quality dialogue data) of under-represented African languages and demonstrating the cross-lingual transferability hypothesis for dialogue systems. We also provide the datasets and host the model checkpoints/demos on the HuggingFace hub for public access.
Design and Implementation of English To Yoruba Verb Phrase Machine Translation System
Apr 09, 2021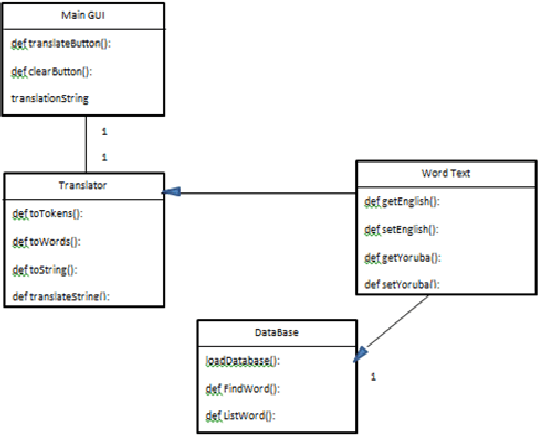
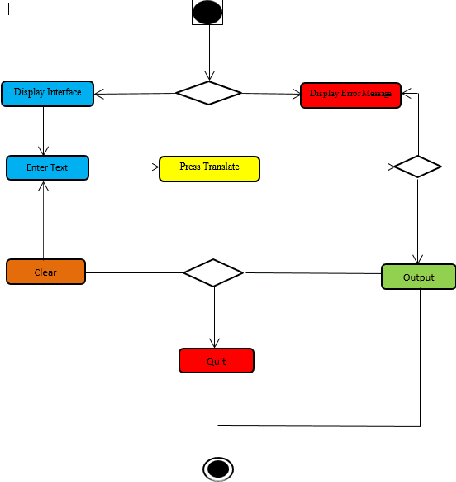

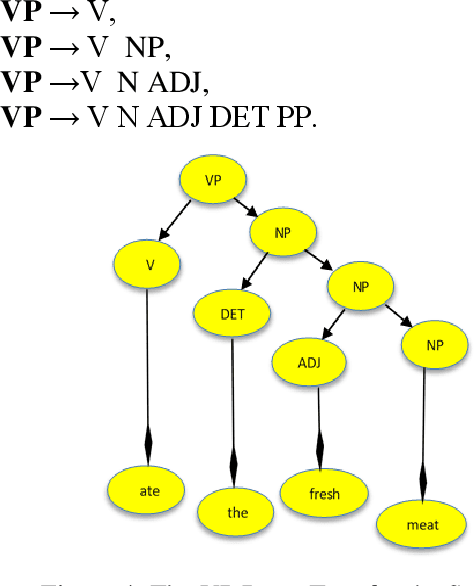
We aim to develop an English to Yoruba machine translation system which can translate English verb phrase text to its Yoruba equivalent.Words from both languages Source Language and Target Language were collected for the verb phrase group in the home domain.The lexical translation is done by assigning values of the matching word in the dictionary.The syntax of the two languages was realized using Context-Free Grammar,we validated the rewrite rules with finite state automata.The human evaluation method was used and expert fluency scored.The evaluation shows the system performed better than that of sampled Google translation with over 70 percent of the response matching that of the system's output.