 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigor in AI: Doing Rigorous AI Work Requires a Broader, Responsible AI-Informed Conception of Rigor
Jun 17, 2025In AI research and practice, rigor remains largely understood in terms of methodological rigor -- such as whether mathematical, statistical, or computational methods are correctly applied. We argue that this narrow conception of rigor has contributed to the concerns raised by the responsible AI community, including overblown claims about AI capabilities. Our position is that a broader conception of what rigorous AI research and practice should entail is needed. We believe such a conception -- in addition to a more expansive understanding of (1) methodological rigor -- should include aspects related to (2) what background knowledge informs what to work on (epistemic rigor); (3) how disciplinary, community, or personal norms, standards, or beliefs influence the work (normative rigor); (4) how clearly articulated the theoretical constructs under use are (conceptual rigor); (5) what is reported and how (reporting rigor); and (6) how well-supported the inferences from existing evidence are (interpretative rigor). In doing so, we also aim to provide useful language and a framework for much-needed dialogue about the AI community's work by researchers, policymakers, journalists, and other stakeholders.
Toward an Evaluation Science for Generative AI Systems
Mar 07, 2025There is an increasing imperative to anticipate and understand the performance and safety of generative AI systems in real-world deployment contexts. However, the current evaluation ecosystem is insufficient: Commonly used static benchmarks face validity challenges, and ad hoc case-by-case audits rarely scale. In this piece, we advocate for maturing an evaluation science for generative AI systems. While generative AI creates unique challenges for system safety engineering and measurement science, the field can draw valuable insights from the development of safety evaluation practices in other fields, including transportation, aerospace, and pharmaceutical engineering. In particular, we present three key lessons: Evaluation metrics must be applicable to real-world performance, metrics must be iteratively refined, and evaluation institutions and norms must be established. Applying these insights, we outline a concrete path toward a more rigorous approach for evaluating generative AI systems.
Fully Autonomous AI Agents Should Not be Developed
Feb 06, 2025This paper argues that fully autonomous AI agents should not be developed. In support of this position, we build from prior scientific literature and current product marketing to delineate different AI agent levels and detail the ethical values at play in each, documenting trade-offs in potential benefits and risks. Our analysis reveals that risks to people increase with the autonomy of a system: The more control a user cedes to an AI agent, the more risks to people arise. Particularly concerning are safety risks, which affect human life and impact further values.
Constructing the CORD-19 Vaccine Dataset
Jul 26, 2024



We introduce new dataset 'CORD-19-Vaccination' to cater to scientists specifically looking into COVID-19 vaccine-related research. This dataset is extracted from CORD-19 dataset [Wang et al., 2020] and augmented with new columns for language detail, author demography, keywords, and topic per paper. Facebook's fastText model is used to identify languages [Joulin et al., 2016]. To establish author demography (author affiliation, lab/institution location, and lab/institution country columns) we processed the JSON file for each paper and then further enhanced using Google's search API to determine country values. 'Yake' was used to extract keywords from the title, abstract, and body of each paper and the LDA (Latent Dirichlet Allocation) algorithm was used to add topic information [Campos et al., 2020, 2018a,b]. To evaluate the dataset, we demonstrate a question-answering task like the one used in the CORD-19 Kaggle challenge [Goldbloom et al., 2022]. For further evaluation, sequential sentence classification was performed on each paper's abstract using the model from Dernoncourt et al. [2016]. We partially hand annotated the training dataset and used a pre-trained BERT-PubMed layer. 'CORD- 19-Vaccination' contains 30k research papers and can be immensely valuable for NLP research such as text mining, information extraction, and question answering, specific to the domain of COVID-19 vaccine research.
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Jun 25, 2024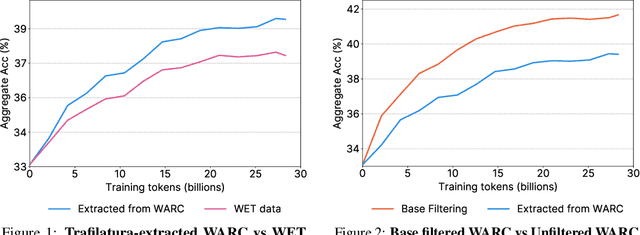
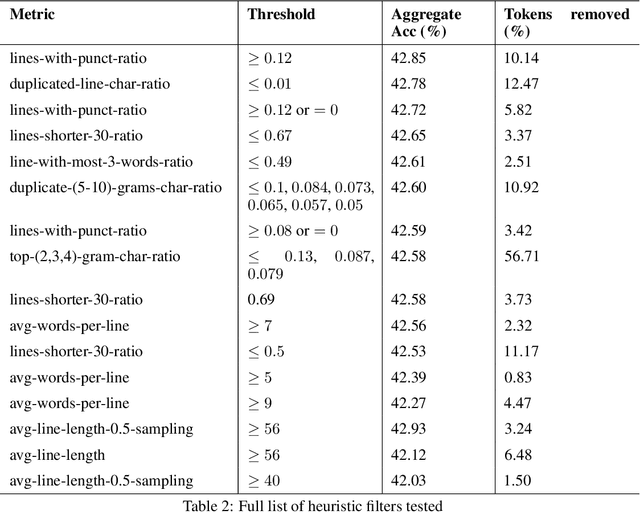
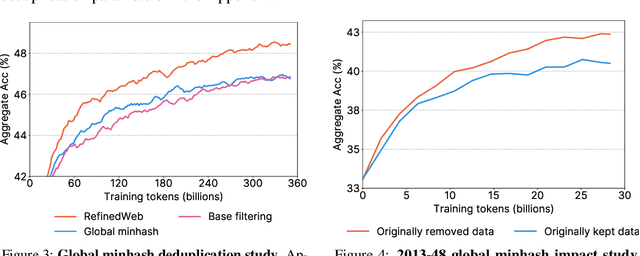
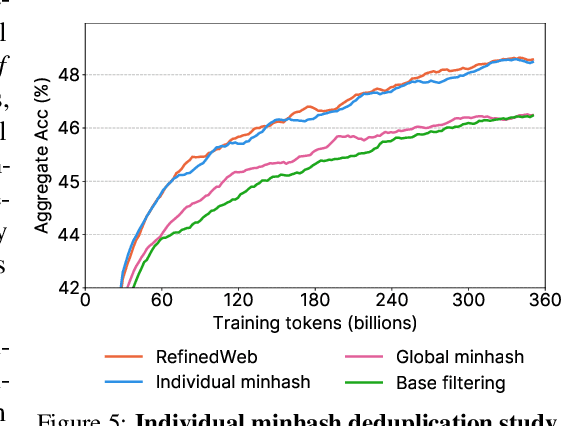
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
CIVICS: Building a Dataset for Examining Culturally-Informed Values in Large Language Models
May 22, 2024



This paper introduces the "CIVICS: Culturally-Informed & Values-Inclusive Corpus for Societal impacts" dataset, designed to evaluate the social and cultural variation of Large Language Models (LLMs) across multiple languages and value-sensitive topics. We create a hand-crafted, multilingual dataset of value-laden prompts which address specific socially sensitive topics, including LGBTQI rights, social welfare, immigration, disability rights, and surrogacy. CIVICS is designed to generate responses showing LLMs' encoded and implicit values. Through our dynamic annotation processes, tailored prompt design, and experiments, we investigate how open-weight LLMs respond to value-sensitive issues, exploring their behavior across diverse linguistic and cultural contexts. Using two experimental set-ups based on log-probabilities and long-form responses, we show social and cultural variability across different LLMs. Specifically, experiments involving long-form responses demonstrate that refusals are triggered disparately across models, but consistently and more frequently in English or translated statements. Moreover, specific topics and sources lead to more pronounced differences across model answers, particularly on immigration, LGBTQI rights, and social welfare. As shown by our experiments, the CIVICS dataset aims to serve as a tool for future research, promoting reproducibility and transparency across broader linguistic settings, and furthering the development of AI technologies that respect and reflect global cultural diversities and value pluralism. The CIVICS dataset and tools will be made available upon publication under open licenses; an anonymized version is currently available at https://huggingface.co/CIVICS-dataset.
Evaluating the Social Impact of Generative AI Systems in Systems and Society
Jun 12, 2023Generative AI systems across modalities, ranging from text, image, audio, and video, have broad social impacts, but there exists no official standard for means of evaluating those impacts and which impacts should be evaluated. We move toward a standard approach in evaluating a generative AI system for any modality, in two overarching categories: what is able to be evaluated in a base system that has no predetermined application and what is able to be evaluated in society. We describe specific social impact categories and how to approach and conduct evaluations in the base technical system, then in people and society. Our framework for a base system defines seven categories of social impact: bias, stereotypes, and representational harms; cultural values and sensitive content; disparate performance; privacy and data protection; financial costs; environmental costs; and data and content moderation labor costs. Suggested methods for evaluation apply to all modalities and analyses of the limitations of existing evaluations serve as a starting point for necessary investment in future evaluations. We offer five overarching categories for what is able to be evaluated in society, each with their own subcategories: trustworthiness and autonomy; inequality, marginalization, and violence; concentration of authority; labor and creativity; and ecosystem and environment. Each subcategory includes recommendations for mitigating harm. We are concurrently crafting an evaluation repository for the AI research community to contribute existing evaluations along the given categories. This version will be updated following a CRAFT session at ACM FAccT 2023.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023



As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
Measuring Data
Dec 09, 2022


We identify the task of measuring data to quantitatively characterize the composition of machine learning data and datasets. Similar to an object's height, width, and volume, data measurements quantify different attributes of data along common dimensions that support comparison. Several lines of research have proposed what we refer to as measurements, with differing terminology; we bring some of this work together, particularly in fields of computer vision and language, and build from it to motivate measuring data as a critical component of responsible AI development. Measuring data aids in systematically building and analyzing machine learning (ML) data towards specific goals and gaining better control of what modern ML systems will learn. We conclude with a discussion of the many avenues of future work, the limitations of data measurements, and how to leverage these measurement approaches in research and practice.
The Stack: 3 TB of permissively licensed source code
Nov 20, 2022



Large Language Models (LLMs) play an ever-increasing role in the field of Artificial Intelligence (AI)--not only for natural language processing but also for code understanding and generation. To stimulate open and responsible research on LLMs for code, we introduce The Stack, a 3.1 TB dataset consisting of permissively licensed source code in 30 programming languages. We describe how we collect the full dataset, construct a permissively licensed subset, present a data governance plan, discuss limitations, and show promising results on text2code benchmarks by training 350M-parameter decoders on different Python subsets. We find that (1) near-deduplicating the data significantly boosts performance across all experiments, and (2) it is possible to match previously reported HumanEval and MBPP performance using only permissively licensed data. We make the dataset available at https://hf.co/BigCode, provide a tool called "Am I in The Stack" (https://hf.co/spaces/bigcode/in-the-stack) for developers to search The Stack for copies of their code, and provide a process for code to be removed from the dataset by following the instructions at https://www.bigcode-project.org/docs/about/the-stack/.