 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Checkpointing: Efficient and Flexible Checkpointing for Large Scale Distributed Training
Jun 27, 2024



Existing checkpointing approaches seem ill-suited for distributed training even though hardware limitations make model parallelism, i.e., sharding model state across multiple accelerators, a requirement for model scaling. Consolidating distributed model state into a single checkpoint unacceptably slows down training, and is impractical at extreme scales. Distributed checkpoints, in contrast, are tightly coupled to the model parallelism and hardware configurations of the training run, and thus unusable on different configurations. To address this problem, we propose Universal Checkpointing, a technique that enables efficient checkpoint creation while providing the flexibility of resuming on arbitrary parallelism strategy and hardware configurations. Universal Checkpointing unlocks unprecedented capabilities for large-scale training such as improved resilience to hardware failures through continued training on remaining healthy hardware, and reduced training time through opportunistic exploitation of elastic capacity. The key insight of Universal Checkpointing is the selection of the optimal representation in each phase of the checkpointing life cycle: distributed representation for saving, and consolidated representation for loading. This is achieved using two key mechanisms. First, the universal checkpoint format, which consists of a consolidated representation of each model parameter and metadata for mapping parameter fragments into training ranks of arbitrary model-parallelism configuration. Second, the universal checkpoint language, a simple but powerful specification language for converting distributed checkpoints into the universal checkpoint format. Our evaluation demonstrates the effectiveness and generality of Universal Checkpointing on state-of-the-art model architectures and a wide range of parallelism techniques.
The Case for Co-Designing Model Architectures with Hardware
Jan 30, 2024



While GPUs are responsible for training the vast majority of state-of-the-art deep learning models, the implications of their architecture are often overlooked when designing new deep learning (DL) models. As a consequence, modifying a DL model to be more amenable to the target hardware can significantly improve the runtime performance of DL training and inference. In this paper, we provide a set of guidelines for users to maximize the runtime performance of their transformer models. These guidelines have been created by carefully considering the impact of various model hyperparameters controlling model shape on the efficiency of the underlying computation kernels executed on the GPU. We find the throughput of models with efficient model shapes is up to 39\% higher while preserving accuracy compared to models with a similar number of parameters but with unoptimized shapes.
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
Jun 21, 2023



Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks that require reasoning over one or multiple images to generate a text. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELISC dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELISC, we train an 80 billion parameters vision and language model on the dataset and obtain competitive performance on various multimodal benchmarks. We release the code to reproduce the dataset along with the dataset itself.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
What Language Model to Train if You Have One Million GPU Hours?
Nov 08, 2022



The crystallization of modeling methods around the Transformer architecture has been a boon for practitioners. Simple, well-motivated architectural variations can transfer across tasks and scale, increasing the impact of modeling research. However, with the emergence of state-of-the-art 100B+ parameters models, large language models are increasingly expensive to accurately design and train. Notably, it can be difficult to evaluate how modeling decisions may impact emergent capabilities, given that these capabilities arise mainly from sheer scale alone. In the process of building BLOOM--the Big Science Large Open-science Open-access Multilingual language model--our goal is to identify an architecture and training setup that makes the best use of our 1,000,000 A100-GPU-hours budget. Specifically, we perform an ablation study at the billion-parameter scale comparing different modeling practices and their impact on zero-shot generalization. In addition, we study the impact of various popular pre-training corpora on zero-shot generalization. We also study the performance of a multilingual model and how it compares to the English-only one. Finally, we consider the scaling behaviour of Transformers to choose the target model size, shape, and training setup. All our models and code are open-sourced at https://huggingface.co/bigscience .
Datasets: A Community Library for Natural Language Processing
Sep 07, 2021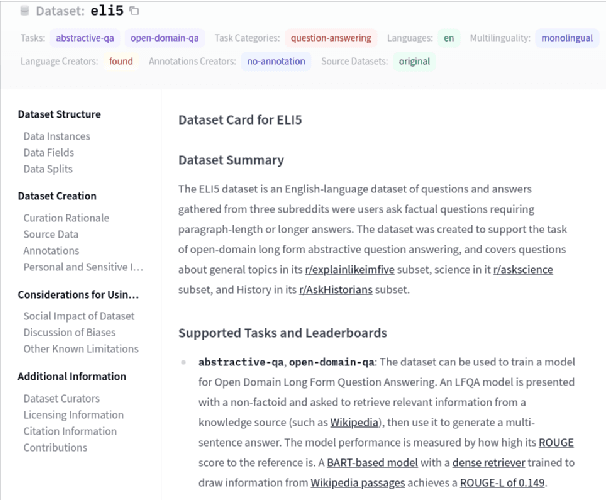
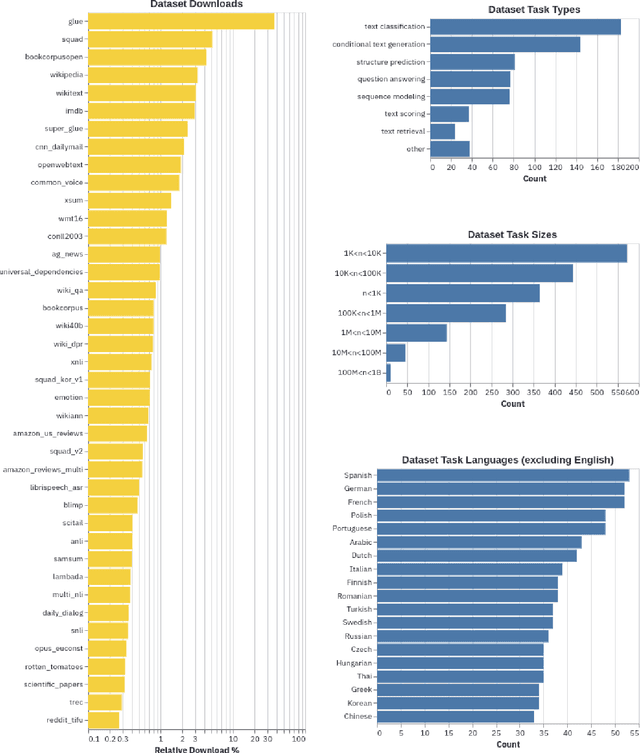
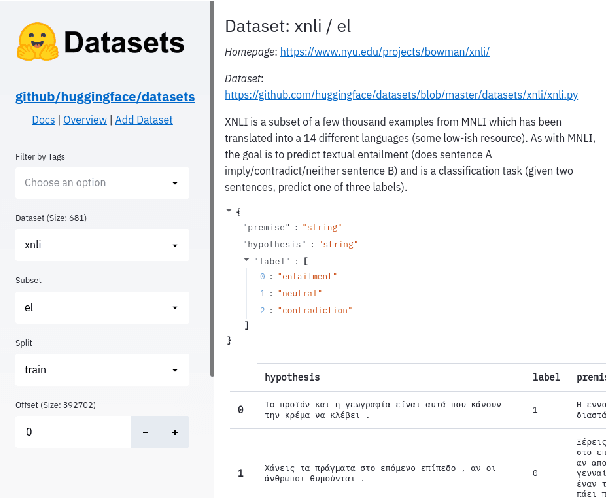
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.