 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaguna M.1/XS.2 Technical Report
May 26, 2026We present Laguna M.1 and Laguna XS.2, two Mixture-of-Experts foundation models built for long-horizon, agentic coding: M.1 has $225.8$B total parameters ($23.4$B activated per token) and XS.2 has $33.4$B total ($3$B activated). Both models were trained from scratch end-to-end inside the same internal system that we refer to as our Model Factory: a tightly-integrated stack of versioned data, training, evaluation, and inference components that turn model development into an industrial process. We describe the principles and design choices of the Model Factory and also detail the end-to-end training process of our models, throughout pre-training data and architecture, post-training stages, evaluation, and quantization. On agentic software engineering and terminal benchmarks (SWE-bench Verified, SWE-bench Multilingual, SWE-Bench Pro, and Terminal-Bench 2.0) M.1 and XS.2 are competitive with state-of-the-art open models in their respective weight classes. Laguna XS.2 weights are released under Apache~2.0 at https://huggingface.co/collections/poolside/laguna-xs2.
LLMs Can Learn to Reason Via Off-Policy RL
Feb 22, 2026Reinforcement learning (RL) approaches for Large Language Models (LLMs) frequently use on-policy algorithms, such as PPO or GRPO. However, policy lag from distributed training architectures and differences between the training and inference policies break this assumption, making the data off-policy by design. To rectify this, prior work has focused on making this off-policy data appear more on-policy, either via importance sampling (IS), or by more closely aligning the training and inference policies by explicitly modifying the inference engine. In this work, we embrace off-policyness and propose a novel off-policy RL algorithm that does not require these modifications: Optimal Advantage-based Policy Optimization with Lagged Inference policy (OAPL). We show that OAPL outperforms GRPO with importance sampling on competition math benchmarks, and can match the performance of a publicly available coding model, DeepCoder, on LiveCodeBench, while using 3x fewer generations during training. We further empirically demonstrate that models trained via OAPL have improved test time scaling under the Pass@k metric. OAPL allows for efficient, effective post-training even with lags of more than 400 gradient steps between the training and inference policies, 100x more off-policy than prior approaches.
Value-Guided Search for Efficient Chain-of-Thought Reasoning
May 23, 2025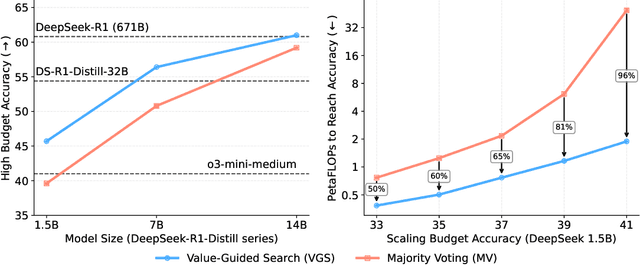
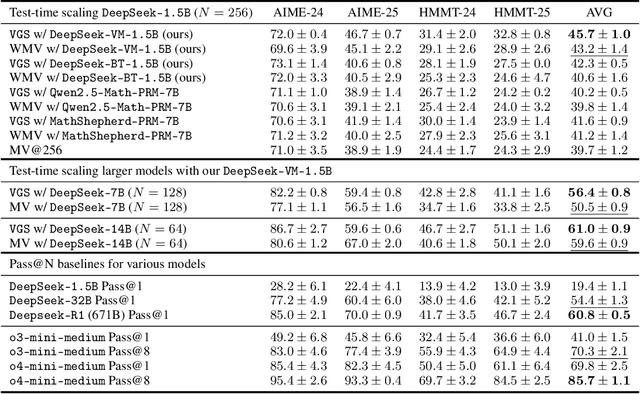
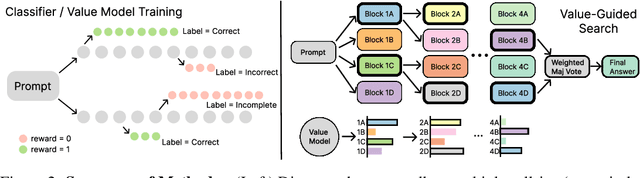
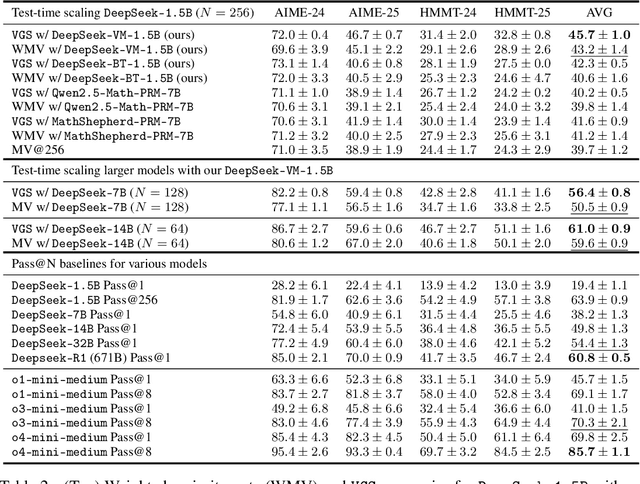
In this paper, we propose a simple and efficient method for value model training on long-context reasoning traces. Compared to existing process reward models (PRMs), our method does not require a fine-grained notion of "step," which is difficult to define for long-context reasoning models. By collecting a dataset of 2.5 million reasoning traces, we train a 1.5B token-level value model and apply it to DeepSeek models for improved performance with test-time compute scaling. We find that block-wise value-guided search (VGS) with a final weighted majority vote achieves better test-time scaling than standard methods such as majority voting or best-of-n. With an inference budget of 64 generations, VGS with DeepSeek-R1-Distill-1.5B achieves an average accuracy of 45.7% across four competition math benchmarks (AIME 2024 & 2025, HMMT Feb 2024 & 2025), reaching parity with o3-mini-medium. Moreover, VGS significantly reduces the inference FLOPs required to achieve the same performance of majority voting. Our dataset, model and codebase are open-sourced.
Application of an attention-based CNN-BiLSTM framework for in vivo two-photon calcium imaging of neuronal ensembles: decoding complex bilateral forelimb movements from unilateral M1
Apr 23, 2025Decoding behavior, such as movement, from multiscale brain networks remains a central objective in neuroscience. Over the past decades, artificial intelligence and machine learning have played an increasingly significant role in elucidating the neural mechanisms underlying motor function. The advancement of brain-monitoring technologies, capable of capturing complex neuronal signals with high spatial and temporal resolution, necessitates the development and application of more sophisticated machine learning models for behavioral decoding. In this study, we employ a hybrid deep learning framework, an attention-based CNN-BiLSTM model, to decode skilled and complex forelimb movements using signals obtained from in vivo two-photon calcium imaging. Our findings demonstrate that the intricate movements of both ipsilateral and contralateral forelimbs can be accurately decoded from unilateral M1 neuronal ensembles. These results highlight the efficacy of advanced hybrid deep learning models in capturing the spatiotemporal dependencies of neuronal networks activity linked to complex movement execution.
$Q\sharp$: Provably Optimal Distributional RL for LLM Post-Training
Feb 27, 2025



Reinforcement learning (RL) post-training is crucial for LLM alignment and reasoning, but existing policy-based methods, such as PPO and DPO, can fall short of fixing shortcuts inherited from pre-training. In this work, we introduce $Q\sharp$, a value-based algorithm for KL-regularized RL that guides the reference policy using the optimal regularized $Q$ function. We propose to learn the optimal $Q$ function using distributional RL on an aggregated online dataset. Unlike prior value-based baselines that guide the model using unregularized $Q$-values, our method is theoretically principled and provably learns the optimal policy for the KL-regularized RL problem. Empirically, $Q\sharp$ outperforms prior baselines in math reasoning benchmarks while maintaining a smaller KL divergence to the reference policy. Theoretically, we establish a reduction from KL-regularized RL to no-regret online learning, providing the first bounds for deterministic MDPs under only realizability. Thanks to distributional RL, our bounds are also variance-dependent and converge faster when the reference policy has small variance. In sum, our results highlight $Q\sharp$ as an effective approach for post-training LLMs, offering both improved performance and theoretical guarantees. The code can be found at https://github.com/jinpz/q_sharp.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021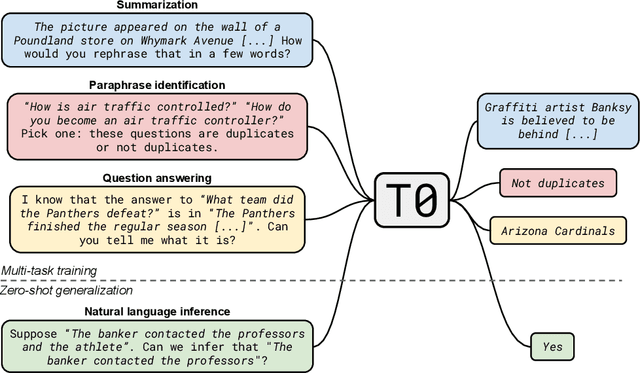

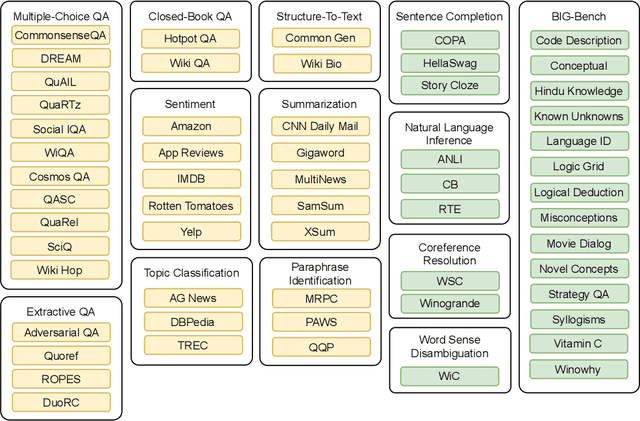

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
Optimism is All You Need: Model-Based Imitation Learning From Observation Alone
Feb 22, 2021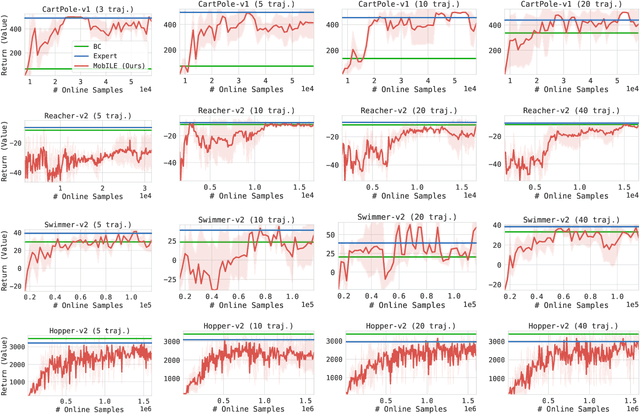
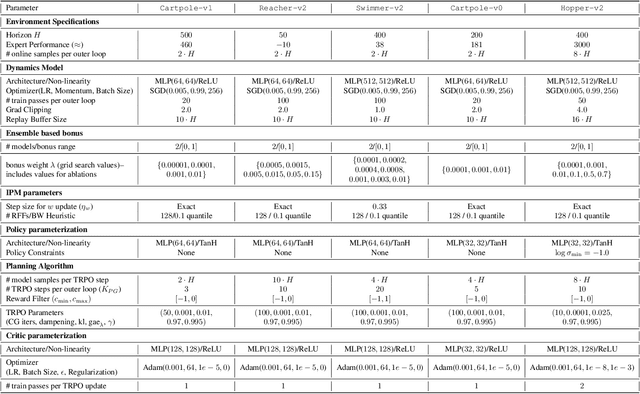

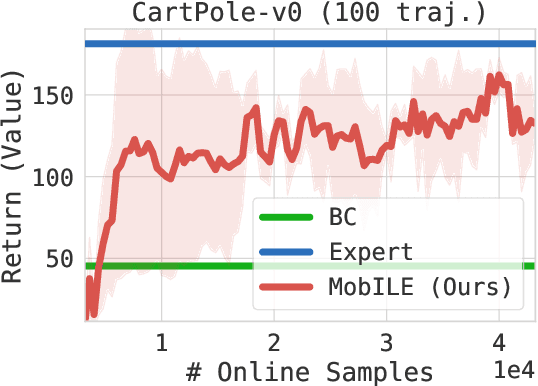
This paper studies Imitation Learning from Observations alone (ILFO) where the learner is presented with expert demonstrations that only consist of states encountered by an expert (without access to actions taken by the expert). We present a provably efficient model-based framework MobILE to solve the ILFO problem. MobILE involves carefully trading off exploration against imitation - this is achieved by integrating the idea of optimism in the face of uncertainty into the distribution matching imitation learning (IL) framework. We provide a unified analysis for MobILE, and demonstrate that MobILE enjoys strong performance guarantees for classes of MDP dynamics that satisfy certain well studied notions of complexity. We also show that the ILFO problem is strictly harder than the standard IL problem by reducing ILFO to a multi-armed bandit problem indicating that exploration is necessary for ILFO. We complement these theoretical results with experimental simulations on benchmark OpenAI Gym tasks that indicate the efficacy of MobILE.
Learning Deep Parameterized Skills from Demonstration for Re-targetable Visuomotor Control
Oct 23, 2019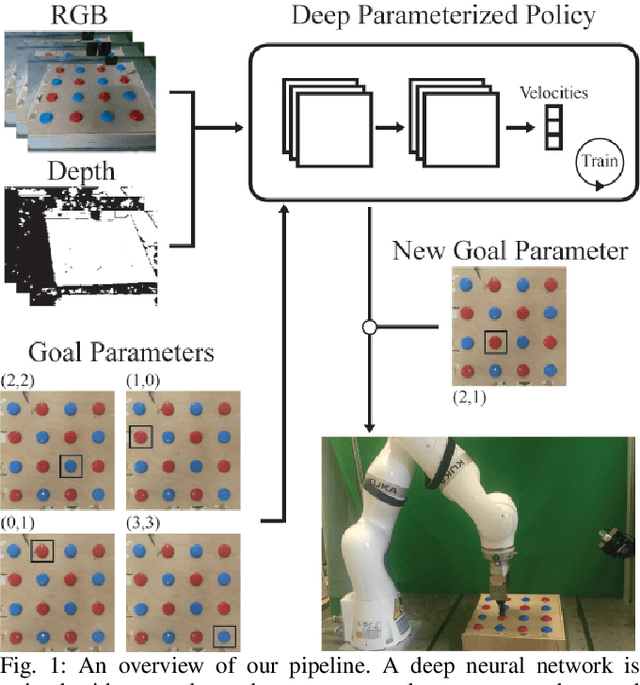
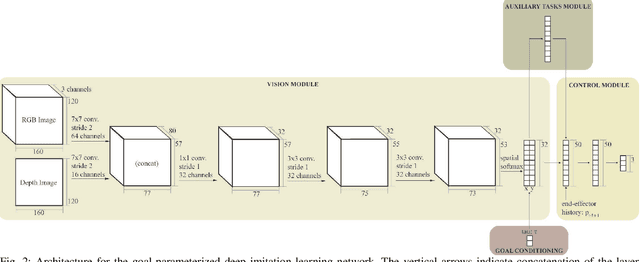
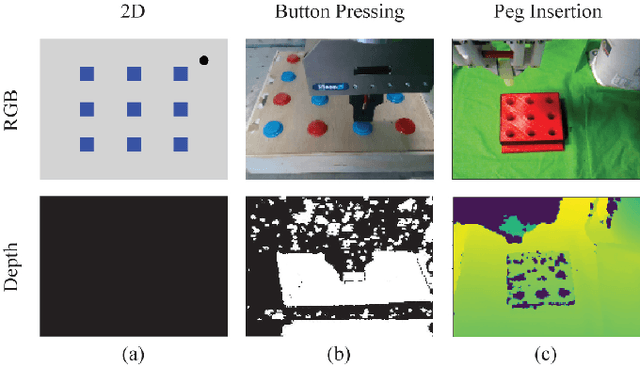
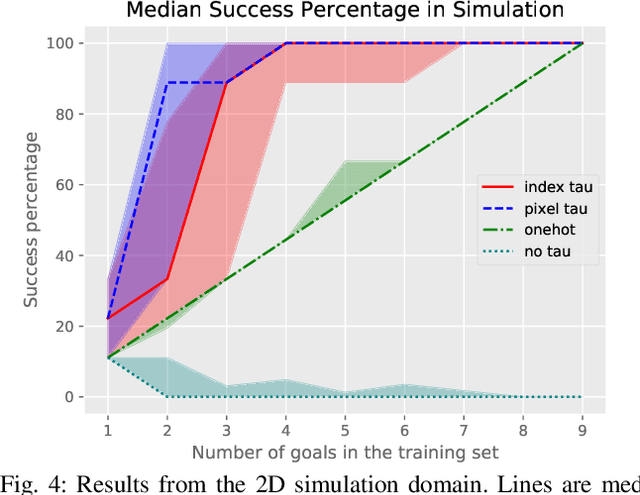
Robots need to learn skills that can not only generalize across similar problems but also be directed to a specific goal. Previous methods either train a new skill for every different goal or do not infer the specific target in the presence of multiple goals from visual data. We introduce an end-to-end method that represents targetable visuomotor skills as a goal-parameterized neural network policy. By training on an informative subset of available goals with the associated target parameters, we are able to learn a policy that can zero-shot generalize to previously unseen goals. We evaluate our method in a representative 2D simulation of a button-grid and on both button-pressing and peg-insertion tasks on two different physical arms. We demonstrate that our model trained on 33% of the possible goals is able to generalize to more than 90% of the targets in the scene for both simulation and robot experiments. We also successfully learn a mapping from target pixel coordinates to a robot policy to complete a specified goal.
Learning Representations of Emotional Speech with Deep Convolutional Generative Adversarial Networks
Apr 22, 2017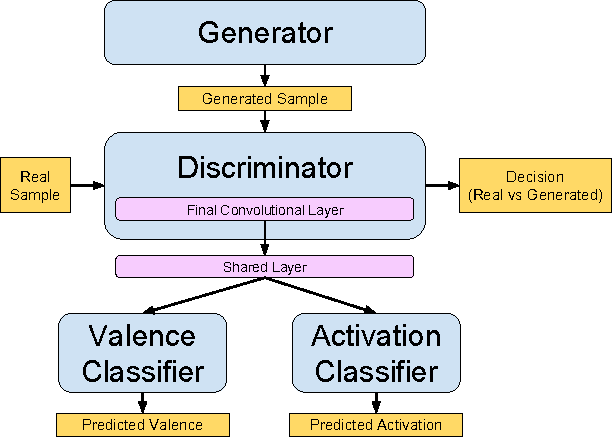
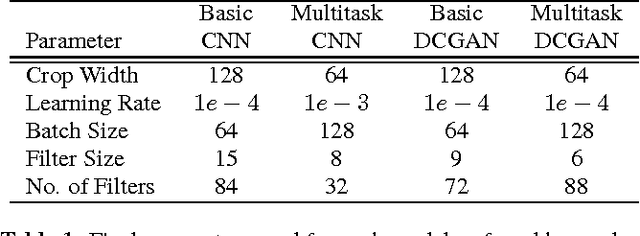
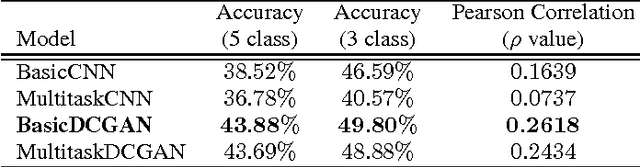
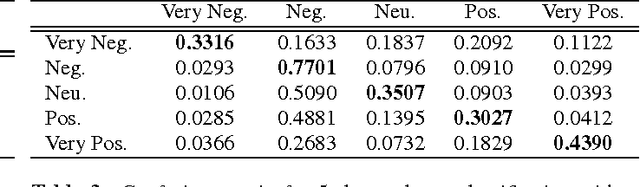
Automatically assessing emotional valence in human speech has historically been a difficult task for machine learning algorithms. The subtle changes in the voice of the speaker that are indicative of positive or negative emotional states are often "overshadowed" by voice characteristics relating to emotional intensity or emotional activation. In this work we explore a representation learning approach that automatically derives discriminative representations of emotional speech. In particular, we investigate two machine learning strategies to improve classifier performance: (1) utilization of unlabeled data using a deep convolutional generative adversarial network (DCGAN), and (2) multitask learning. Within our extensive experiments we leverage a multitask annotated emotional corpus as well as a large unlabeled meeting corpus (around 100 hours). Our speaker-independent classification experiments show that in particular the use of unlabeled data in our investigations improves performance of the classifiers and both fully supervised baseline approaches are outperformed considerably. We improve the classification of emotional valence on a discrete 5-point scale to 43.88% and on a 3-point scale to 49.80%, which is competitive to state-of-the-art performance.