 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
hmBERT: Historical Multilingual Language Models for Named Entity Recognition
May 31, 2022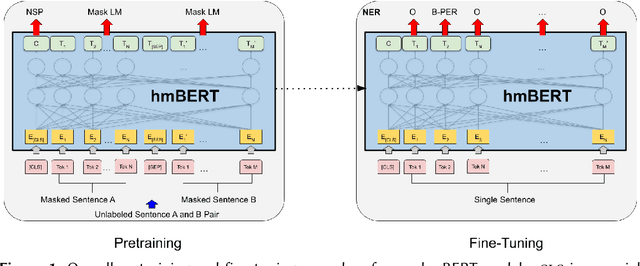



Compared to standard Named Entity Recognition (NER), identifying persons, locations, and organizations in historical texts forms a big challenge. To obtain machine-readable corpora, the historical text is usually scanned and optical character recognition (OCR) needs to be performed. As a result, the historical corpora contain errors. Also, entities like location or organization can change over time, which poses another challenge. Overall historical texts come with several peculiarities that differ greatly from modern texts and large labeled corpora for training a neural tagger are hardly available for this domain. In this work, we tackle NER for historical German, English, French, Swedish, and Finnish by training large historical language models. We circumvent the need for labeled data by using unlabeled data for pretraining a language model. hmBERT, a historical multilingual BERT-based language model is proposed, with different sizes of it being publicly released. Furthermore, we evaluate the capability of hmBERT by solving downstream NER as part of this year's HIPE-2022 shared task and provide detailed analysis and insights. For the Multilingual Classical Commentary coarse-grained NER challenge, our tagger HISTeria outperforms the other teams' models for two out of three languages.
Entities, Dates, and Languages: Zero-Shot on Historical Texts with T0
Apr 11, 2022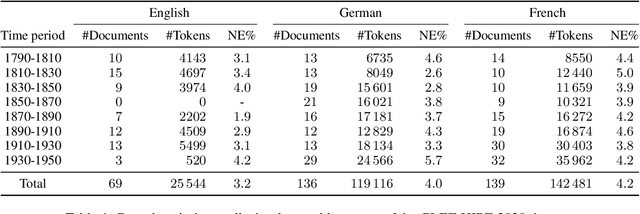



In this work, we explore whether the recently demonstrated zero-shot abilities of the T0 model extend to Named Entity Recognition for out-of-distribution languages and time periods. Using a historical newspaper corpus in 3 languages as test-bed, we use prompts to extract possible named entities. Our results show that a naive approach for prompt-based zero-shot multilingual Named Entity Recognition is error-prone, but highlights the potential of such an approach for historical languages lacking labeled datasets. Moreover, we also find that T0-like models can be probed to predict the publication date and language of a document, which could be very relevant for the study of historical texts.
Data Centric Domain Adaptation for Historical Text with OCR Errors
Jul 02, 2021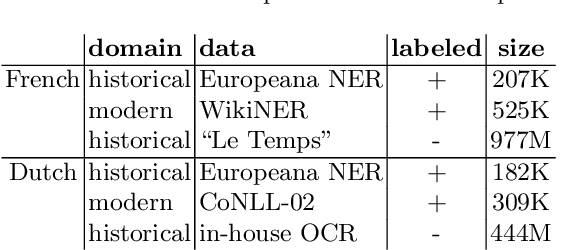
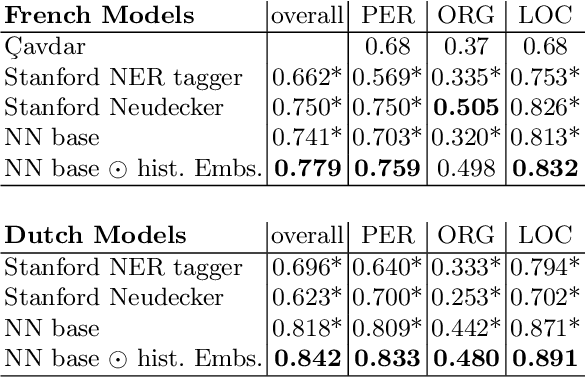
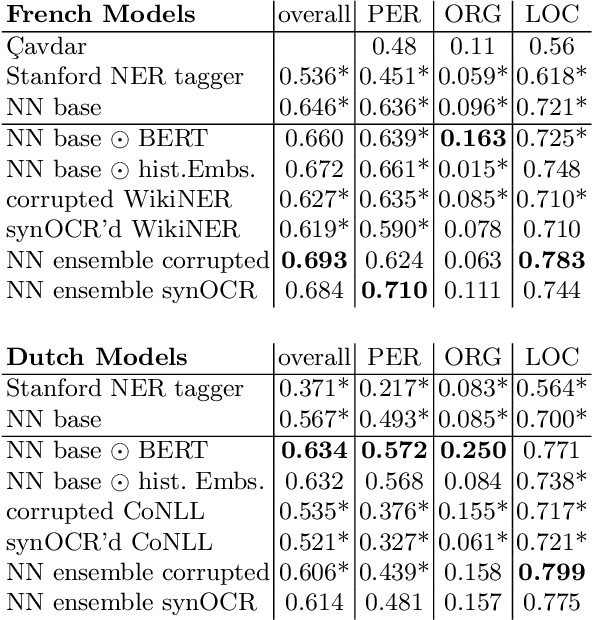

We propose new methods for in-domain and cross-domain Named Entity Recognition (NER) on historical data for Dutch and French. For the cross-domain case, we address domain shift by integrating unsupervised in-domain data via contextualized string embeddings; and OCR errors by injecting synthetic OCR errors into the source domain and address data centric domain adaptation. We propose a general approach to imitate OCR errors in arbitrary input data. Our cross-domain as well as our in-domain results outperform several strong baselines and establish state-of-the-art results. We publish preprocessed versions of the French and Dutch Europeana NER corpora.
FLERT: Document-Level Features for Named Entity Recognition
Nov 13, 2020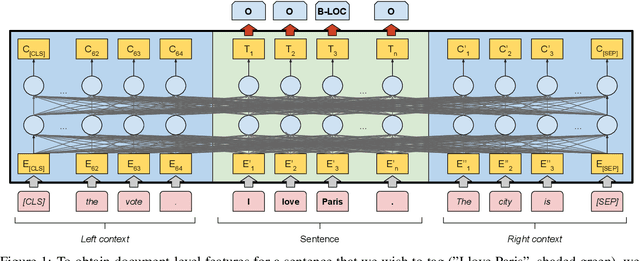
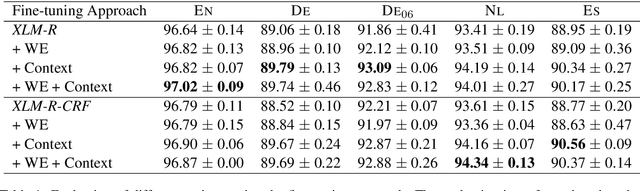
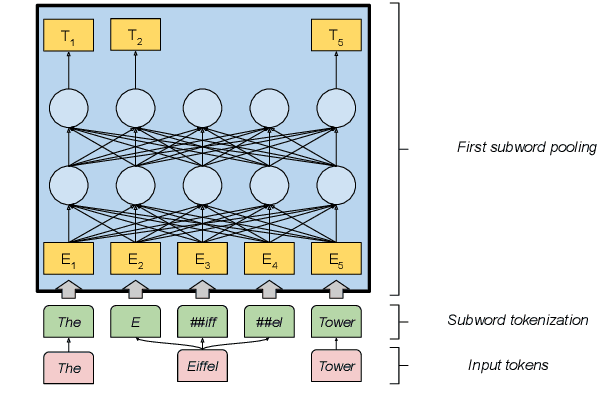
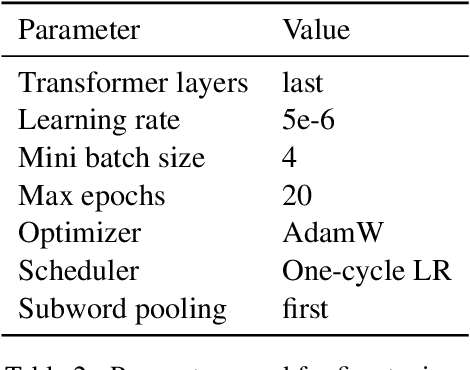
Current state-of-the-art approaches for named entity recognition (NER) using BERT-style transformers typically use one of two different approaches: (1) The first fine-tunes the transformer itself on the NER task and adds only a simple linear layer for word-level predictions. (2) The second uses the transformer only to provide features to a standard LSTM-CRF sequence labeling architecture and thus performs no fine-tuning. In this paper, we perform a comparative analysis of both approaches in a variety of settings currently considered in the literature. In particular, we evaluate how well they work when document-level features are leveraged. Our evaluation on the classic CoNLL benchmark datasets for 4 languages shows that document-level features significantly improve NER quality and that fine-tuning generally outperforms the feature-based approaches. We present recommendations for parameters as well as several new state-of-the-art numbers. Our approach is integrated into the Flair framework to facilitate reproduction of our experiments.
German's Next Language Model
Oct 30, 2020
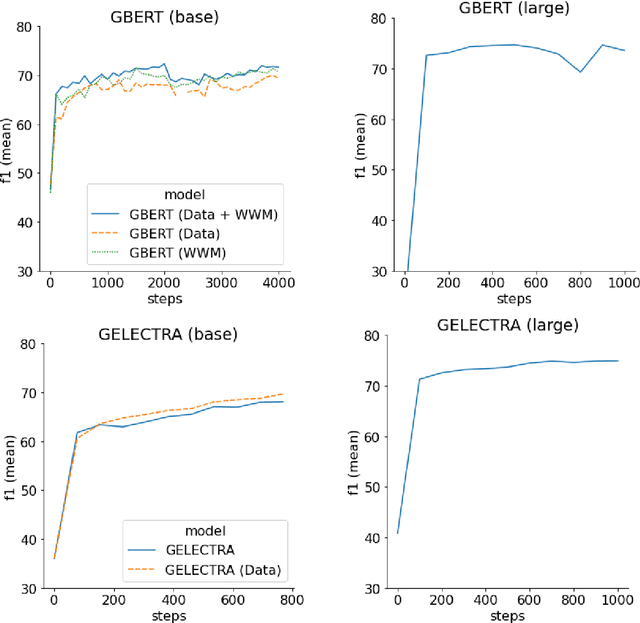
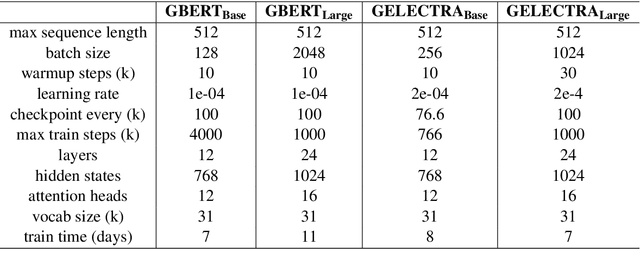

In this work we present the experiments which lead to the creation of our BERT and ELECTRA based German language models, GBERT and GELECTRA. By varying the input training data, model size, and the presence of Whole Word Masking (WWM) we were able to attain SoTA performance across a set of document classification and named entity recognition (NER) tasks for both models of base and large size. We adopt an evaluation driven approach in training these models and our results indicate that both adding more data and utilizing WWM improve model performance. By benchmarking against existing German models, we show that these models are the best German models to date. Our trained models will be made publicly available to the research community.
Towards Robust Named Entity Recognition for Historic German
Jun 18, 2019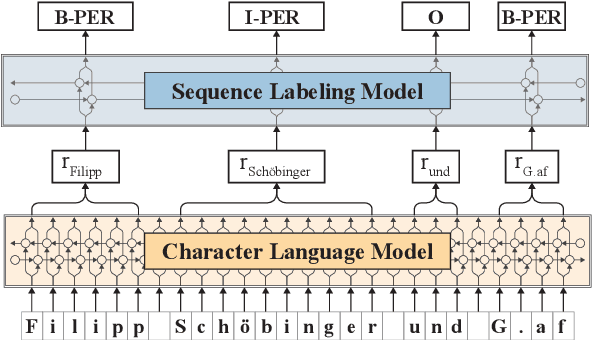
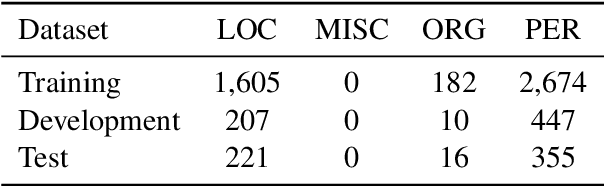
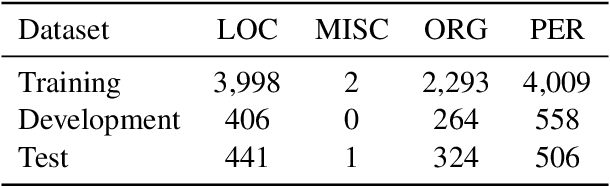
Recent advances in language modeling using deep neural networks have shown that these models learn representations, that vary with the network depth from morphology to semantic relationships like co-reference. We apply pre-trained language models to low-resource named entity recognition for Historic German. We show on a series of experiments that character-based pre-trained language models do not run into trouble when faced with low-resource datasets. Our pre-trained character-based language models improve upon classical CRF-based methods and previous work on Bi-LSTMs by boosting F1 score performance by up to 6%. Our pre-trained language and NER models are publicly available under https://github.com/stefan-it/historic-ner .