 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
Feb 02, 2022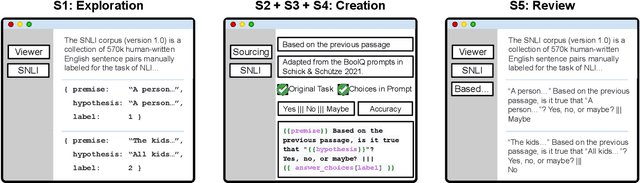
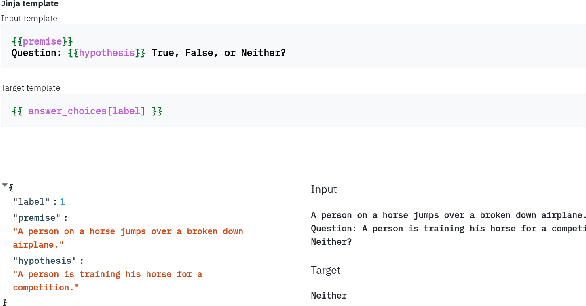

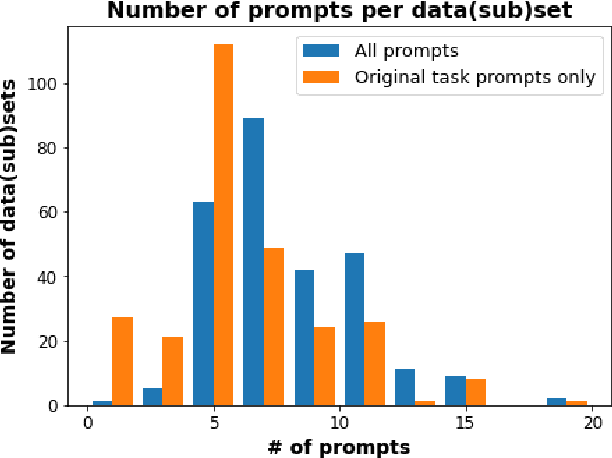
PromptSource is a system for creating, sharing, and using natural language prompts. Prompts are functions that map an example from a dataset to a natural language input and target output. Using prompts to train and query language models is an emerging area in NLP that requires new tools that let users develop and refine these prompts collaboratively. PromptSource addresses the emergent challenges in this new setting with (1) a templating language for defining data-linked prompts, (2) an interface that lets users quickly iterate on prompt development by observing outputs of their prompts on many examples, and (3) a community-driven set of guidelines for contributing new prompts to a common pool. Over 2,000 prompts for roughly 170 datasets are already available in PromptSource. PromptSource is available at https://github.com/bigscience-workshop/promptsource.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021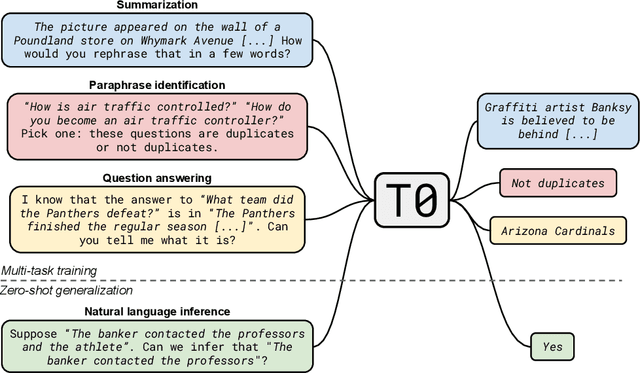

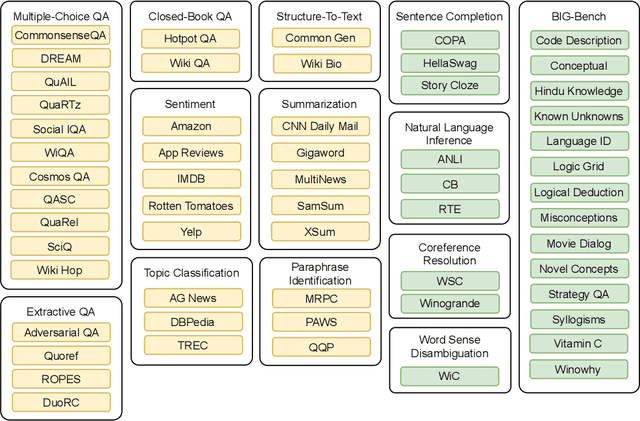

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
Character Feature Engineering for Japanese Word Segmentation
Oct 03, 2019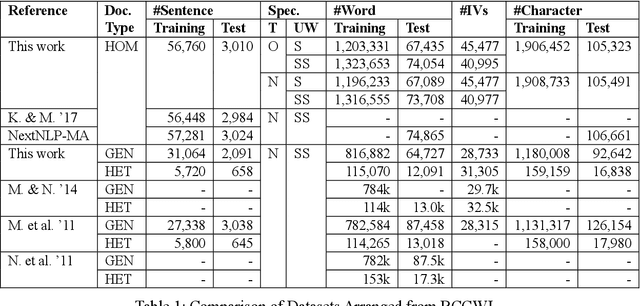
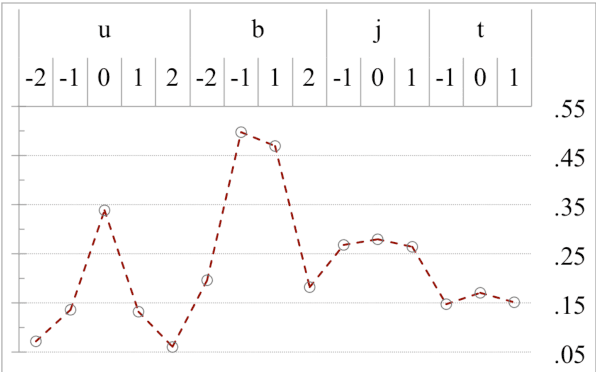
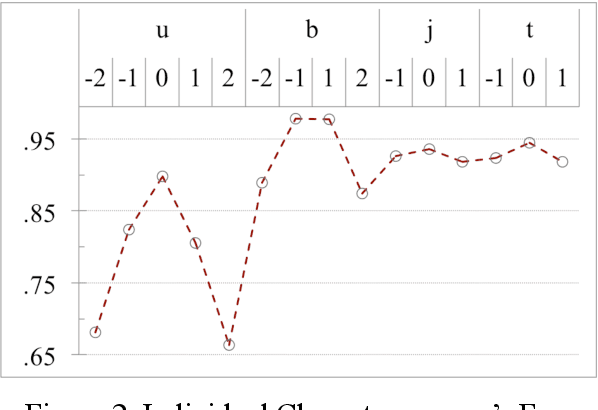
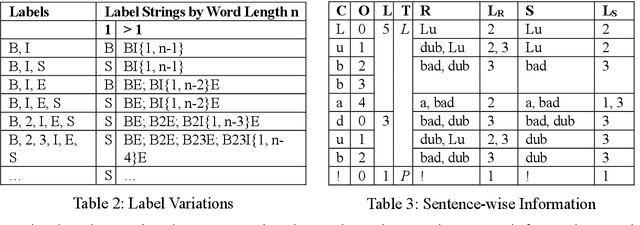
On word segmentation problems, machine learning architecture engineering often draws attention. The problem representation itself, however, has remained almost static as either word lattice ranking or character sequence tagging, for at least two decades. The latter of-ten shows stronger predictive power than the former for out-of-vocabulary (OOV) issue. When the issue escalating to rapid adaptation, which is a common scenario for industrial applications, active learning of partial annotations or re-training with additional lexical re-sources is usually applied, however, from a somewhat word-based perspective. Not only it is uneasy for end-users to comply with linguistically consistent word boundary decisions, but also the risk/cost of forking models permanently with estimated weights is seldom affordable. To overcome the obstacle, this work provides an alternative, which uses linguistic intuition about character compositions, such that a sophisticated feature set and its derived scheme can enable dynamic lexicon expansion with the model remaining intact. Experiment results suggest that the proposed solution, with or without external lexemes, performs competitively in terms of F1 score and OOV recall across various datasets.
On the Development of Text Input Method - Lessons Learned
Apr 27, 2007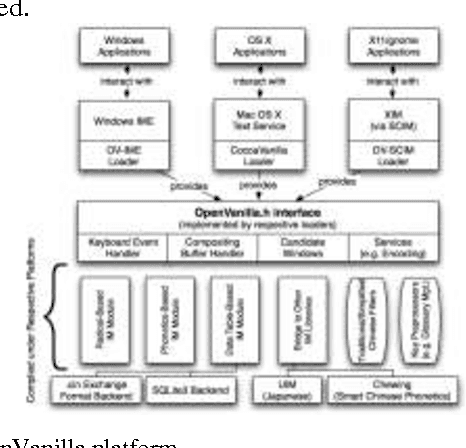
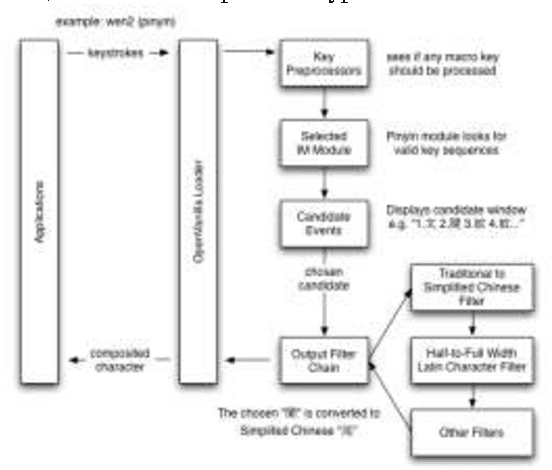
Intelligent Input Methods (IM) are essential for making text entries in many East Asian scripts, but their application to other languages has not been fully explored. This paper discusses how such tools can contribute to the development of computer processing of other oriental languages. We propose a design philosophy that regards IM as a text service platform, and treats the study of IM as a cross disciplinary subject from the perspectives of software engineering, human-computer interaction (HCI), and natural language processing (NLP). We discuss these three perspectives and indicate a number of possible future research directions.
An Automated Evaluation Metric for Chinese Text Entry
Apr 27, 2007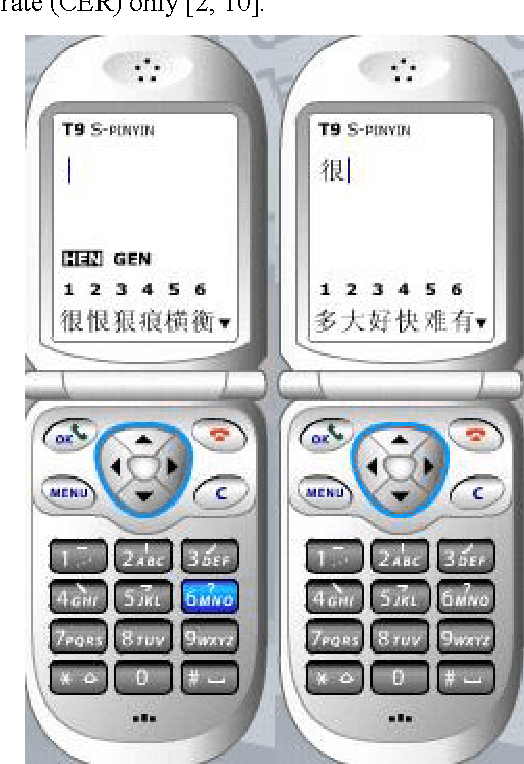

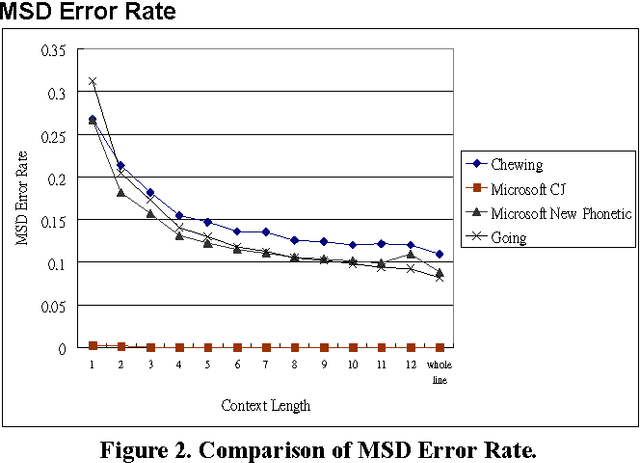

In this paper, we propose an automated evaluation metric for text entry. We also consider possible improvements to existing text entry evaluation metrics, such as the minimum string distance error rate, keystrokes per character, cost per correction, and a unified approach proposed by MacKenzie, so they can accommodate the special characteristics of Chinese text. Current methods lack an integrated concern about both typing speed and accuracy for Chinese text entry evaluation. Our goal is to remove the bias that arises due to human factors. First, we propose a new metric, called the correction penalty (P), based on Fitts' law and Hick's law. Next, we transform it into the approximate amortized cost (AAC) of information theory. An analysis of the AAC of Chinese text input methods with different context lengths is also presented.
* 8 pages