 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Printed Circuit Board Defect Detection through Ensemble Learning
Sep 14, 2024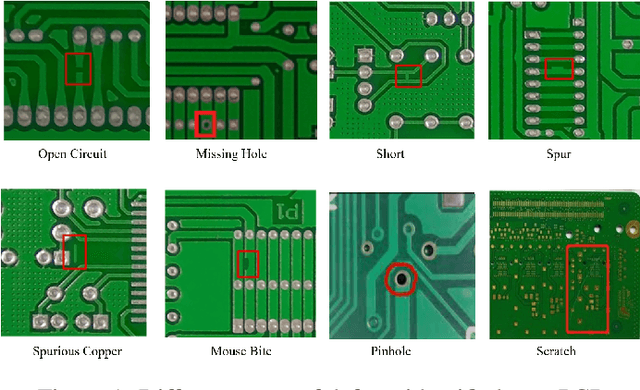
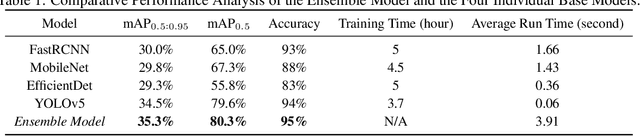


The quality control of printed circuit boards (PCBs) is paramount in advancing electronic device technology. While numerous machine learning methodologies have been utilized to augment defect detection efficiency and accuracy, previous studies have predominantly focused on optimizing individual models for specific defect types, often overlooking the potential synergies between different approaches. This paper introduces a comprehensive inspection framework leveraging an ensemble learning strategy to address this gap. Initially, we utilize four distinct PCB defect detection models utilizing state-of-the-art methods: EfficientDet, MobileNet SSDv2, Faster RCNN, and YOLOv5. Each method is capable of identifying PCB defects independently. Subsequently, we integrate these models into an ensemble learning framework to enhance detection performance. A comparative analysis reveals that our ensemble learning framework significantly outperforms individual methods, achieving a 95% accuracy in detecting diverse PCB defects. These findings underscore the efficacy of our proposed ensemble learning framework in enhancing PCB quality control processes.
Rapid Parameter Estimation for Extreme Mass Ratio Inspirals Using Machine Learning
Sep 12, 2024



Extreme-mass-ratio inspiral (EMRI) signals pose significant challenges in gravitational wave (GW) astronomy owing to their low-frequency nature and highly complex waveforms, which occupy a high-dimensional parameter space with numerous variables. Given their extended inspiral timescales and low signal-to-noise ratios, EMRI signals warrant prolonged observation periods. Parameter estimation becomes particularly challenging due to non-local parameter degeneracies, arising from multiple local maxima, as well as flat regions and ridges inherent in the likelihood function. These factors lead to exceptionally high time complexity for parameter analysis while employing traditional matched filtering and random sampling methods. To address these challenges, the present study applies machine learning to Bayesian posterior estimation of EMRI signals, leveraging the recently developed flow matching technique based on ODE neural networks. Our approach demonstrates computational efficiency several orders of magnitude faster than the traditional Markov Chain Monte Carlo (MCMC) methods, while preserving the unbiasedness of parameter estimation. We show that machine learning technology has the potential to efficiently handle the vast parameter space, involving up to seventeen parameters, associated with EMRI signals. Furthermore, to our knowledge, this is the first instance of applying machine learning, specifically the Continuous Normalizing Flows (CNFs), to EMRI signal analysis. Our findings highlight the promising potential of machine learning in EMRI waveform analysis, offering new perspectives for the advancement of space-based GW detection and GW astronomy.
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
DuA: Dual Attentive Transformer in Long-Term Continuous EEG Emotion Analysis
Jul 30, 2024



Affective brain-computer interfaces (aBCIs) are increasingly recognized for their potential in monitoring and interpreting emotional states through electroencephalography (EEG) signals. Current EEG-based emotion recognition methods perform well with short segments of EEG data. However, these methods encounter significant challenges in real-life scenarios where emotional states evolve over extended periods. To address this issue, we propose a Dual Attentive (DuA) transformer framework for long-term continuous EEG emotion analysis. Unlike segment-based approaches, the DuA transformer processes an entire EEG trial as a whole, identifying emotions at the trial level, referred to as trial-based emotion analysis. This framework is designed to adapt to varying signal lengths, providing a substantial advantage over traditional methods. The DuA transformer incorporates three key modules: the spatial-spectral network module, the temporal network module, and the transfer learning module. The spatial-spectral network module simultaneously captures spatial and spectral information from EEG signals, while the temporal network module detects temporal dependencies within long-term EEG data. The transfer learning module enhances the model's adaptability across different subjects and conditions. We extensively evaluate the DuA transformer using a self-constructed long-term EEG emotion database, along with two benchmark EEG emotion databases. On the basis of the trial-based leave-one-subject-out cross-subject cross-validation protocol, our experimental results demonstrate that the proposed DuA transformer significantly outperforms existing methods in long-term continuous EEG emotion analysis, with an average enhancement of 5.28%.
ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
Jul 19, 2024



In this work, we introduce ChatQA 2, a Llama3-based model designed to bridge the gap between open-access LLMs and leading proprietary models (e.g., GPT-4-Turbo) in long-context understanding and retrieval-augmented generation (RAG) capabilities. These two capabilities are essential for LLMs to process large volumes of information that cannot fit into a single prompt and are complementary to each other, depending on the downstream tasks and computational budgets. We present a detailed continued training recipe to extend the context window of Llama3-70B-base from 8K to 128K tokens, along with a three-stage instruction tuning process to enhance the model's instruction-following, RAG performance, and long-context understanding capabilities. Our results demonstrate that the Llama3-ChatQA-2-70B model achieves accuracy comparable to GPT-4-Turbo-2024-0409 on many long-context understanding tasks and surpasses it on the RAG benchmark. Interestingly, we find that the state-of-the-art long-context retriever can alleviate the top-k context fragmentation issue in RAG, further improving RAG-based results for long-context understanding tasks. We also provide extensive comparisons between RAG and long-context solutions using state-of-the-art long-context LLMs.
Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
Jul 10, 2024



An elusive goal in navigation research is to build an intelligent agent that can understand multimodal instructions including natural language and image, and perform useful navigation. To achieve this, we study a widely useful category of navigation tasks we call Multimodal Instruction Navigation with demonstration Tours (MINT), in which the environment prior is provided through a previously recorded demonstration video. Recent advances in Vision Language Models (VLMs) have shown a promising path in achieving this goal as it demonstrates capabilities in perceiving and reasoning about multimodal inputs. However, VLMs are typically trained to predict textual output and it is an open research question about how to best utilize them in navigation. To solve MINT, we present Mobility VLA, a hierarchical Vision-Language-Action (VLA) navigation policy that combines the environment understanding and common sense reasoning power of long-context VLMs and a robust low-level navigation policy based on topological graphs. The high-level policy consists of a long-context VLM that takes the demonstration tour video and the multimodal user instruction as input to find the goal frame in the tour video. Next, a low-level policy uses the goal frame and an offline constructed topological graph to generate robot actions at every timestep. We evaluated Mobility VLA in a 836m^2 real world environment and show that Mobility VLA has a high end-to-end success rates on previously unsolved multimodal instructions such as "Where should I return this?" while holding a plastic bin.
PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jul 03, 2024



Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
PharmGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
Jun 26, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP) by by minimizing the need for complex feature engineering. However, the application of LLMs in specialized domains like biopharmaceuticals and chemistry remains largely unexplored. These fields are characterized by intricate terminologies, specialized knowledge, and a high demand for precision areas where general purpose LLMs often fall short. In this study, we introduce PharmGPT, a suite of multilingual LLMs with 13 billion and 70 billion parameters, specifically trained on a comprehensive corpus of hundreds of billions of tokens tailored to the Bio-Pharmaceutical and Chemical sectors. Our evaluation shows that PharmGPT matches or surpasses existing general models on key benchmarks, such as NAPLEX, demonstrating its exceptional capability in domain-specific tasks. This advancement establishes a new benchmark for LLMs in the Bio-Pharmaceutical and Chemical fields, addressing the existing gap in specialized language modeling. Furthermore, this suggests a promising path for enhanced research and development in these specialized areas, paving the way for more precise and effective applications of NLP in specialized domains.
ECLIPSE: Expunging Clean-label Indiscriminate Poisons via Sparse Diffusion Purification
Jun 25, 2024



Clean-label indiscriminate poisoning attacks add invisible perturbations to correctly labeled training images, thus dramatically reducing the generalization capability of the victim models. Recently, some defense mechanisms have been proposed such as adversarial training, image transformation techniques, and image purification. However, these schemes are either susceptible to adaptive attacks, built on unrealistic assumptions, or only effective against specific poison types, limiting their universal applicability. In this research, we propose a more universally effective, practical, and robust defense scheme called ECLIPSE. We first investigate the impact of Gaussian noise on the poisons and theoretically prove that any kind of poison will be largely assimilated when imposing sufficient random noise. In light of this, we assume the victim has access to an extremely limited number of clean images (a more practical scene) and subsequently enlarge this sparse set for training a denoising probabilistic model (a universal denoising tool). We then begin by introducing Gaussian noise to absorb the poisons and then apply the model for denoising, resulting in a roughly purified dataset. Finally, to address the trade-off of the inconsistency in the assimilation sensitivity of different poisons by Gaussian noise, we propose a lightweight corruption compensation module to effectively eliminate residual poisons, providing a more universal defense approach. Extensive experiments demonstrate that our defense approach outperforms 10 state-of-the-art defenses. We also propose an adaptive attack against ECLIPSE and verify the robustness of our defense scheme. Our code is available at https://github.com/CGCL-codes/ECLIPSE.
PatentGPT: A Large Language Model for Intellectual Property
Apr 30, 2024



In recent years, large language models have attracted significant attention due to their exceptional performance across a multitude of natural language process tasks, and have been widely applied in various fields. However, the application of large language models in the Intellectual Property (IP) space is challenging due to the strong need for specialized knowledge, privacy protection, processing of extremely long text in this field. In this technical report, we present for the first time a low-cost, standardized procedure for training IP-oriented LLMs, meeting the unique requirements of the IP domain. Using this standard process, we have trained the PatentGPT series models based on open-source pretrained models. By evaluating them on the open-source IP-oriented benchmark MOZIP, our domain-specific LLMs outperforms GPT-4, indicating the effectiveness of the proposed training procedure and the expertise of the PatentGPT models in the IP demain. What is impressive is that our model significantly outperformed GPT-4 on the 2019 China Patent Agent Qualification Examination by achieving a score of 65, reaching the level of human experts. Additionally, the PatentGPT model, which utilizes the SMoE architecture, achieves performance comparable to that of GPT-4 in the IP domain and demonstrates a better cost-performance ratio on long-text tasks, potentially serving as an alternative to GPT-4 within the IP domain.