 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Impact of Geometric Foundation Models on Vision-Language-Action Models
May 23, 2026Recent work explores new opportunities at the intersection of vision-language-action models (VLAs) and geometric foundation models (GFMs) for 3D reconstruction, such as VGGT. While the resulting geometric VLAs often show improved performance, it remains unclear (i) if modern VLAs already have sufficient geometric understanding to start with, (ii) what is the best architecture to inject geometric understanding into a VLA, and (iii) what is the effect of other design choices that affect geometric VLAs. In this paper we provide a rigorous experimental analysis to shed light on these questions, for a specific choice of VLA (GR00T-N1.5) and GFM (VGGT). Our first contribution is to formalize prior work's intuition that current VLAs lack geometric understanding, by providing a rigorous analysis based on linear probing. The analysis quantifies, for the first time, the "geometric gap" between VLAs and GFMs. Our second contribution is to identify and compare different strategies to bridge GFMs with VLAs. We implement three different architectures, which differ in the way they inject geometry in the VLA, while keeping low-level implementation details as similar as possible, to ensure a fair comparison. Finally, we analyze the impact of non-architectural choices (e.g., training data, number of cameras, reconstruction quality) on the performance of the geometric VLAs.
Simple Recipe Works: Vision-Language-Action Models are Natural Continual Learners with Reinforcement Learning
Mar 12, 2026Continual Reinforcement Learning (CRL) for Vision-Language-Action (VLA) models is a promising direction toward self-improving embodied agents that can adapt in openended, evolving environments. However, conventional wisdom from continual learning suggests that naive Sequential Fine-Tuning (Seq. FT) leads to catastrophic forgetting, necessitating complex CRL strategies. In this work, we take a step back and conduct a systematic study of CRL for large pretrained VLAs across three models and five challenging lifelong RL benchmarks. We find that, contrary to established belief, simple Seq. FT with low-rank adaptation (LoRA) is remarkably strong: it achieves high plasticity, exhibits little to no forgetting, and retains strong zero-shot generalization, frequently outperforming more sophisticated CRL methods. Through detailed analysis, we show that this robustness arises from a synergy between the large pretrained model, parameter-efficient adaptation, and on-policy RL. Together, these components reshape the stability-plasticity trade-off, making continual adaptation both stable and scalable. Our results position Sequential Fine-Tuning as a powerful method for continual RL with VLAs and provide new insights into lifelong learning in the large model era. Code is available at github.com/UT-Austin-RobIn/continual-vla-rl.
FLaRe: Achieving Masterful and Adaptive Robot Policies with Large-Scale Reinforcement Learning Fine-Tuning
Sep 25, 2024



In recent years, the Robotics field has initiated several efforts toward building generalist robot policies through large-scale multi-task Behavior Cloning. However, direct deployments of these policies have led to unsatisfactory performance, where the policy struggles with unseen states and tasks. How can we break through the performance plateau of these models and elevate their capabilities to new heights? In this paper, we propose FLaRe, a large-scale Reinforcement Learning fine-tuning framework that integrates robust pre-trained representations, large-scale training, and gradient stabilization techniques. Our method aligns pre-trained policies towards task completion, achieving state-of-the-art (SoTA) performance both on previously demonstrated and on entirely novel tasks and embodiments. Specifically, on a set of long-horizon mobile manipulation tasks, FLaRe achieves an average success rate of 79.5% in unseen environments, with absolute improvements of +23.6% in simulation and +30.7% on real robots over prior SoTA methods. By utilizing only sparse rewards, our approach can enable generalizing to new capabilities beyond the pretraining data with minimal human effort. Moreover, we demonstrate rapid adaptation to new embodiments and behaviors with less than a day of fine-tuning. Videos can be found on the project website at https://robot-flare.github.io/
TeleMoMa: A Modular and Versatile Teleoperation System for Mobile Manipulation
Mar 12, 2024



A critical bottleneck limiting imitation learning in robotics is the lack of data. This problem is more severe in mobile manipulation, where collecting demonstrations is harder than in stationary manipulation due to the lack of available and easy-to-use teleoperation interfaces. In this work, we demonstrate TeleMoMa, a general and modular interface for whole-body teleoperation of mobile manipulators. TeleMoMa unifies multiple human interfaces including RGB and depth cameras, virtual reality controllers, keyboard, joysticks, etc., and any combination thereof. In its more accessible version, TeleMoMa works using simply vision (e.g., an RGB-D camera), lowering the entry bar for humans to provide mobile manipulation demonstrations. We demonstrate the versatility of TeleMoMa by teleoperating several existing mobile manipulators - PAL Tiago++, Toyota HSR, and Fetch - in simulation and the real world. We demonstrate the quality of the demonstrations collected with TeleMoMa by training imitation learning policies for mobile manipulation tasks involving synchronized whole-body motion. Finally, we also show that TeleMoMa's teleoperation channel enables teleoperation on site, looking at the robot, or remote, sending commands and observations through a computer network, and perform user studies to evaluate how easy it is for novice users to learn to collect demonstrations with different combinations of human interfaces enabled by our system. We hope TeleMoMa becomes a helpful tool for the community enabling researchers to collect whole-body mobile manipulation demonstrations. For more information and video results, https://robin-lab.cs.utexas.edu/telemoma-web.
ELDEN: Exploration via Local Dependencies
Oct 12, 2023



Tasks with large state space and sparse rewards present a longstanding challenge to reinforcement learning. In these tasks, an agent needs to explore the state space efficiently until it finds a reward. To deal with this problem, the community has proposed to augment the reward function with intrinsic reward, a bonus signal that encourages the agent to visit interesting states. In this work, we propose a new way of defining interesting states for environments with factored state spaces and complex chained dependencies, where an agent's actions may change the value of one entity that, in order, may affect the value of another entity. Our insight is that, in these environments, interesting states for exploration are states where the agent is uncertain whether (as opposed to how) entities such as the agent or objects have some influence on each other. We present ELDEN, Exploration via Local DepENdencies, a novel intrinsic reward that encourages the discovery of new interactions between entities. ELDEN utilizes a novel scheme -- the partial derivative of the learned dynamics to model the local dependencies between entities accurately and computationally efficiently. The uncertainty of the predicted dependencies is then used as an intrinsic reward to encourage exploration toward new interactions. We evaluate the performance of ELDEN on four different domains with complex dependencies, ranging from 2D grid worlds to 3D robotic tasks. In all domains, ELDEN correctly identifies local dependencies and learns successful policies, significantly outperforming previous state-of-the-art exploration methods.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
M-EMBER: Tackling Long-Horizon Mobile Manipulation via Factorized Domain Transfer
May 23, 2023In this paper, we propose a method to create visuomotor mobile manipulation solutions for long-horizon activities. We propose to leverage the recent advances in simulation to train visual solutions for mobile manipulation. While previous works have shown success applying this procedure to autonomous visual navigation and stationary manipulation, applying it to long-horizon visuomotor mobile manipulation is still an open challenge that demands both perceptual and compositional generalization of multiple skills. In this work, we develop Mobile-EMBER, or M-EMBER, a factorized method that decomposes a long-horizon mobile manipulation activity into a repertoire of primitive visual skills, reinforcement-learns each skill, and composes these skills to a long-horizon mobile manipulation activity. On a mobile manipulation robot, we find that M-EMBER completes a long-horizon mobile manipulation activity, cleaning_kitchen, achieving a 53% success rate. This requires successfully planning and executing five factorized, learned visual skills.
Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction
Mar 26, 2021
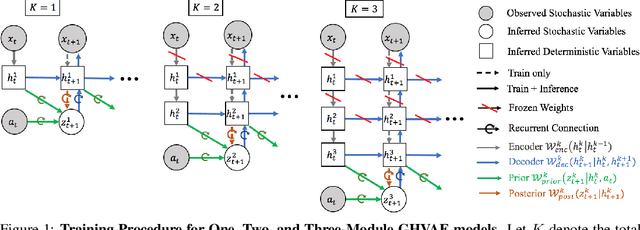

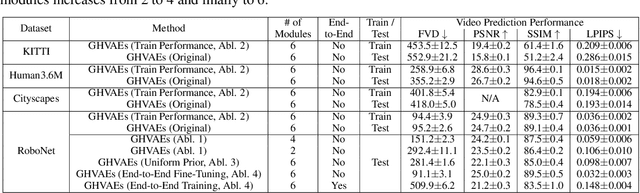
A video prediction model that generalizes to diverse scenes would enable intelligent agents such as robots to perform a variety of tasks via planning with the model. However, while existing video prediction models have produced promising results on small datasets, they suffer from severe underfitting when trained on large and diverse datasets. To address this underfitting challenge, we first observe that the ability to train larger video prediction models is often bottlenecked by the memory constraints of GPUs or TPUs. In parallel, deep hierarchical latent variable models can produce higher quality predictions by capturing the multi-level stochasticity of future observations, but end-to-end optimization of such models is notably difficult. Our key insight is that greedy and modular optimization of hierarchical autoencoders can simultaneously address both the memory constraints and the optimization challenges of large-scale video prediction. We introduce Greedy Hierarchical Variational Autoencoders (GHVAEs), a method that learns high-fidelity video predictions by greedily training each level of a hierarchical autoencoder. In comparison to state-of-the-art models, GHVAEs provide 17-55% gains in prediction performance on four video datasets, a 35-40% higher success rate on real robot tasks, and can improve performance monotonically by simply adding more modules.
Probabilistic Visual Navigation with Bidirectional Image Prediction
Mar 20, 2020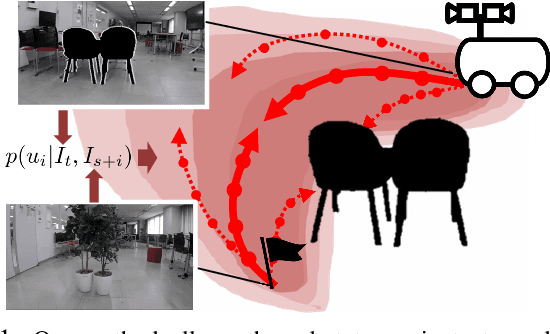
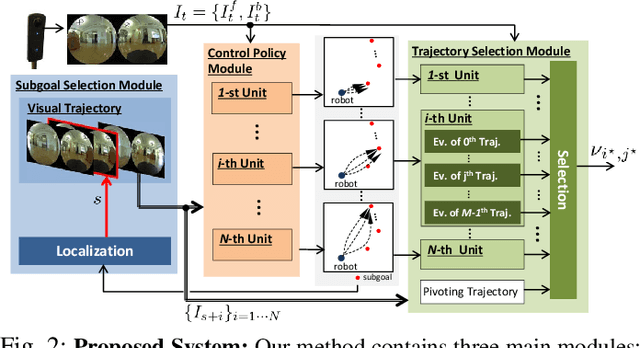
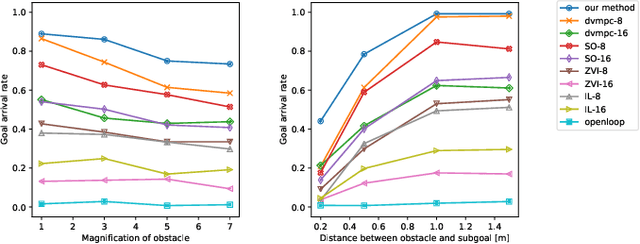
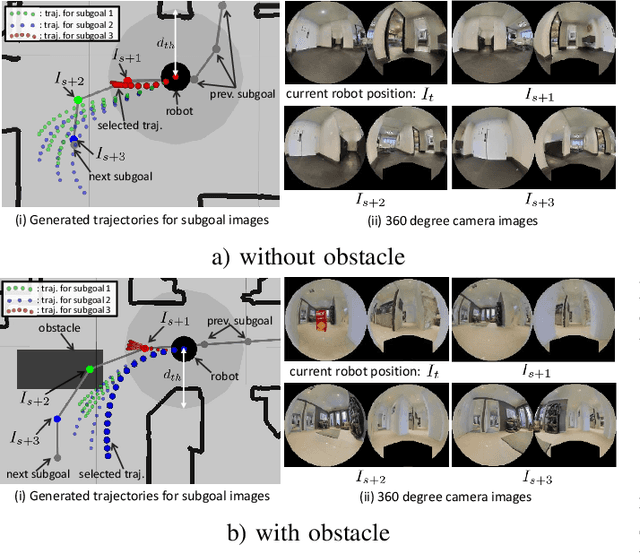
Humans can robustly follow a visual trajectory defined by a sequence of images (i.e. a video) regardless of substantial changes in the environment or the presence of obstacles. We aim at endowing similar visual navigation capabilities to mobile robots solely equipped with a RGB fisheye camera. We propose a novel probabilistic visual navigation system that learns to follow a sequence of images with bidirectional visual predictions conditioned on possible navigation velocities. By predicting bidirectionally (from start towards goal and vice versa) our method extends its predictive horizon enabling the robot to go around unseen large obstacles that are not visible in the video trajectory. Learning how to react to obstacles and potential risks in the visual field is achieved by imitating human teleoperators. Since the human teleoperation commands are diverse, we propose a probabilistic representation of trajectories that we can sample to find the safest path. Integrated into our navigation system, we present a novel localization approach that infers the current location of the robot based on the virtual predicted trajectories required to reach different images in the visual trajectory. We evaluate our navigation system quantitatively and qualitatively in multiple simulated and real environments and compare to state-of-the-art baselines.Our approach outperforms the most recent visual navigation methods with a large margin with regard to goal arrival rate, subgoal coverage rate, and success weighted by path length (SPL). Our method also generalizes to new robot embodiments never used during training.
HRL4IN: Hierarchical Reinforcement Learning for Interactive Navigation with Mobile Manipulators
Oct 24, 2019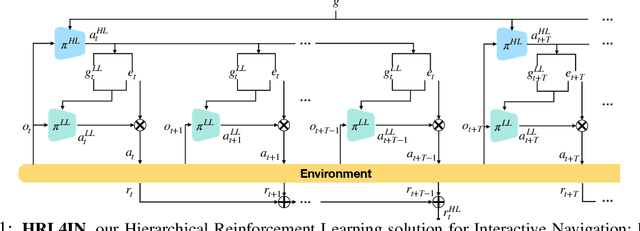

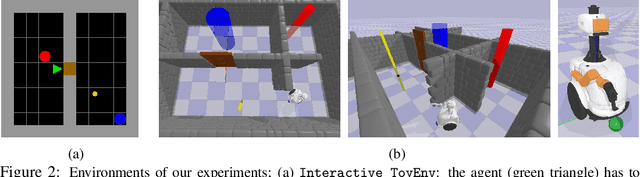
Most common navigation tasks in human environments require auxiliary arm interactions, e.g. opening doors, pressing buttons and pushing obstacles away. This type of navigation tasks, which we call Interactive Navigation, requires the use of mobile manipulators: mobile bases with manipulation capabilities. Interactive Navigation tasks are usually long-horizon and composed of heterogeneous phases of pure navigation, pure manipulation, and their combination. Using the wrong part of the embodiment is inefficient and hinders progress. We propose HRL4IN, a novel Hierarchical RL architecture for Interactive Navigation tasks. HRL4IN exploits the exploration benefits of HRL over flat RL for long-horizon tasks thanks to temporally extended commitments towards subgoals. Different from other HRL solutions, HRL4IN handles the heterogeneous nature of the Interactive Navigation task by creating subgoals in different spaces in different phases of the task. Moreover, HRL4IN selects different parts of the embodiment to use for each phase, improving energy efficiency. We evaluate HRL4IN against flat PPO and HAC, a state-of-the-art HRL algorithm, on Interactive Navigation in two environments - a 2D grid-world environment and a 3D environment with physics simulation. We show that HRL4IN significantly outperforms its baselines in terms of task performance and energy efficiency. More information is available at https://sites.google.com/view/hrl4in.