 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Coding Agents Understand Least-Privilege Authorization?
May 14, 2026As coding agents gain access to shells, repositories, and user files, least-privilege authorization becomes a prerequisite for safe deployment: an agent should receive enough authority to complete the task, without unnecessary authority that exposes sensitive surfaces.To study whether current models can infer this boundary themselves, we first introduce permission-boundary inference, where a model maps a task instruction and terminal environment to a file-level read/write/execute policy, and AuthBench, a benchmark of 120 realistic terminal tasks with human-reviewed permission labels and executable validators for utility and attack outcomes.AuthBench shows that authorization is not a simple conservative-versus-permissive calibration problem: frontier models often omit permissions required by the execution chain while also granting unused or sensitive accesses.Increasing inference-time reasoning does not resolve this mismatch. Instead, each model moves toward a model-specific authorization attractor: more reasoning makes it more consistent in its own failure mode, whether broad-but-exposed or tight-but-brittle.This suggests that direct policy generation is the bottleneck, because a single generation must both discover all necessary accesses and reject all unnecessary ones.We therefore propose Sufficiency-Tightness Decomposition, which first generates a coverage-oriented policy by forward-simulating the task and then audits each granted entry for grounding and sensitivity.Across tested models, this decomposition improves sensitive-task success by up to 15.8% on tightness-biased models while reducing attack success across all evaluated models.
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Apr 26, 2026Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
Gym-V: A Unified Vision Environment System for Agentic Vision Research
Mar 17, 2026As agentic systems increasingly rely on reinforcement learning from verifiable rewards, standardized ``gym'' infrastructure has become essential for rapid iteration, reproducibility, and fair comparison. Vision agents lack such infrastructure, limiting systematic study of what drives their learning and where current models fall short. We introduce \textbf{Gym-V}, a unified platform of 179 procedurally generated visual environments across 10 domains with controllable difficulty, enabling controlled experiments that were previously infeasible across fragmented toolkits. Using it, we find that observation scaffolding is more decisive for training success than the choice of RL algorithm, with captions and game rules determining whether learning succeeds at all. Cross-domain transfer experiments further show that training on diverse task categories generalizes broadly while narrow training can cause negative transfer, with multi-turn interaction amplifying all of these effects. Gym-V is released as a convenient foundation for training environments and evaluation toolkits, aiming to accelerate future research on agentic VLMs.
Attention Residuals
Mar 16, 2026Residual connections with PreNorm are standard in modern LLMs, yet they accumulate all layer outputs with fixed unit weights. This uniform aggregation causes uncontrolled hidden-state growth with depth, progressively diluting each layer's contribution. We propose Attention Residuals (AttnRes), which replaces this fixed accumulation with softmax attention over preceding layer outputs, allowing each layer to selectively aggregate earlier representations with learned, input-dependent weights. To address the memory and communication overhead of attending over all preceding layer outputs for large-scale model training, we introduce Block AttnRes, which partitions layers into blocks and attends over block-level representations, reducing the memory footprint while preserving most of the gains of full AttnRes. Combined with cache-based pipeline communication and a two-phase computation strategy, Block AttnRes becomes a practical drop-in replacement for standard residual connections with minimal overhead. Scaling law experiments confirm that the improvement is consistent across model sizes, and ablations validate the benefit of content-dependent depth-wise selection. We further integrate AttnRes into the Kimi Linear architecture (48B total / 3B activated parameters) and pre-train on 1.4T tokens, where AttnRes mitigates PreNorm dilution, yielding more uniform output magnitudes and gradient distribution across depth, and improves downstream performance across all evaluated tasks.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Equipping Retrieval-Augmented Large Language Models with Document Structure Awareness
Oct 05, 2025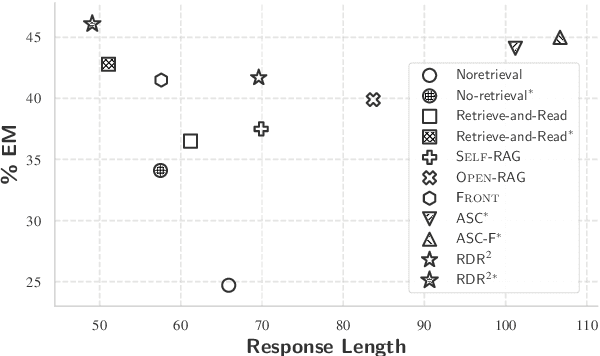
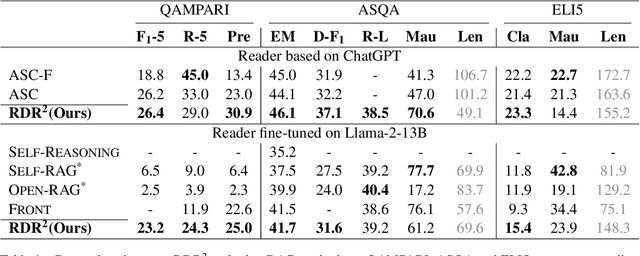
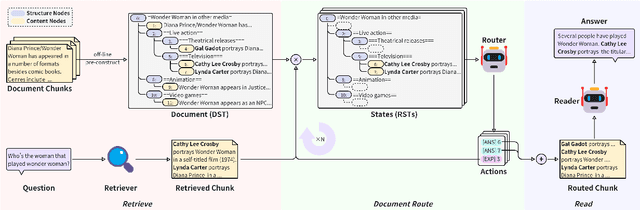
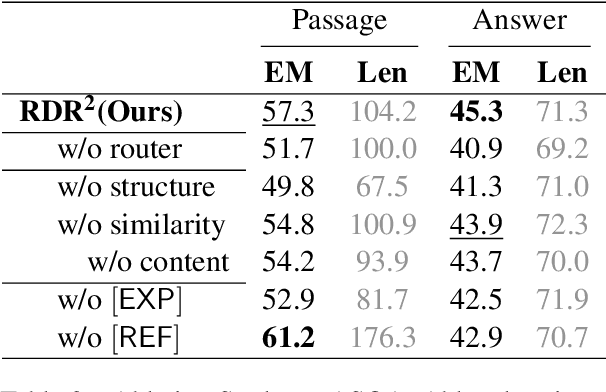
While large language models (LLMs) demonstrate impressive capabilities, their reliance on parametric knowledge often leads to factual inaccuracies. Retrieval-Augmented Generation (RAG) mitigates this by leveraging external documents, yet existing approaches treat retrieved passages as isolated chunks, ignoring valuable structure that is crucial for document organization. Motivated by this gap, we propose Retrieve-DocumentRoute-Read (RDR2), a novel framework that explicitly incorporates structural information throughout the RAG process. RDR2 employs an LLM-based router to dynamically navigate document structure trees, jointly evaluating content relevance and hierarchical relationships to assemble optimal evidence. Our key innovation lies in formulating document routing as a trainable task, with automatic action curation and structure-aware passage selection inspired by human reading strategies. Through comprehensive evaluation on five challenging datasets, RDR2 achieves state-of-the-art performance, demonstrating that explicit structural awareness significantly enhances RAG systems' ability to acquire and utilize knowledge, particularly in complex scenarios requiring multi-document synthesis.
VideoREPA: Learning Physics for Video Generation through Relational Alignment with Foundation Models
May 29, 2025Recent advancements in text-to-video (T2V) diffusion models have enabled high-fidelity and realistic video synthesis. However, current T2V models often struggle to generate physically plausible content due to their limited inherent ability to accurately understand physics. We found that while the representations within T2V models possess some capacity for physics understanding, they lag significantly behind those from recent video self-supervised learning methods. To this end, we propose a novel framework called VideoREPA, which distills physics understanding capability from video understanding foundation models into T2V models by aligning token-level relations. This closes the physics understanding gap and enable more physics-plausible generation. Specifically, we introduce the Token Relation Distillation (TRD) loss, leveraging spatio-temporal alignment to provide soft guidance suitable for finetuning powerful pre-trained T2V models, a critical departure from prior representation alignment (REPA) methods. To our knowledge, VideoREPA is the first REPA method designed for finetuning T2V models and specifically for injecting physical knowledge. Empirical evaluations show that VideoREPA substantially enhances the physics commonsense of baseline method, CogVideoX, achieving significant improvement on relevant benchmarks and demonstrating a strong capacity for generating videos consistent with intuitive physics. More video results are available at https://videorepa.github.io/.
MM-PRM: Enhancing Multimodal Mathematical Reasoning with Scalable Step-Level Supervision
May 19, 2025While Multimodal Large Language Models (MLLMs) have achieved impressive progress in vision-language understanding, they still struggle with complex multi-step reasoning, often producing logically inconsistent or partially correct solutions. A key limitation lies in the lack of fine-grained supervision over intermediate reasoning steps. To address this, we propose MM-PRM, a process reward model trained within a fully automated, scalable framework. We first build MM-Policy, a strong multimodal model trained on diverse mathematical reasoning data. Then, we construct MM-K12, a curated dataset of 10,000 multimodal math problems with verifiable answers, which serves as seed data. Leveraging a Monte Carlo Tree Search (MCTS)-based pipeline, we generate over 700k step-level annotations without human labeling. The resulting PRM is used to score candidate reasoning paths in the Best-of-N inference setup and achieves significant improvements across both in-domain (MM-K12 test set) and out-of-domain (OlympiadBench, MathVista, etc.) benchmarks. Further analysis confirms the effectiveness of soft labels, smaller learning rates, and path diversity in optimizing PRM performance. MM-PRM demonstrates that process supervision is a powerful tool for enhancing the logical robustness of multimodal reasoning systems. We release all our codes and data at https://github.com/ModalMinds/MM-PRM.
CPGD: Toward Stable Rule-based Reinforcement Learning for Language Models
May 18, 2025Recent advances in rule-based reinforcement learning (RL) have significantly improved the reasoning capability of language models (LMs) with rule-based rewards. However, existing RL methods -- such as GRPO, REINFORCE++, and RLOO -- often suffer from training instability, where large policy updates and improper clipping can lead to training collapse. To address this issue, we propose Clipped Policy Gradient Optimization with Policy Drift (CPGD), a novel algorithm designed to stabilize policy learning in LMs. CPGD introduces a policy drift constraint based on KL divergence to dynamically regularize policy updates, and leverages a clip mechanism on the logarithm of the ratio to prevent excessive policy updates. We provide theoretical justification for CPGD and demonstrate through empirical analysis that it mitigates the instability observed in prior approaches. Furthermore, we show that CPGD significantly improves performance while maintaining training stability. Our implementation balances theoretical rigor with practical usability, offering a robust alternative for RL in the post-training of LMs. We release our code at https://github.com/ModalMinds/MM-EUREKA.