 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVid2Real HRI: Align video-based HRI study designs with real-world settings
Mar 23, 2024



HRI research using autonomous robots in real-world settings can produce results with the highest ecological validity of any study modality, but many difficulties limit such studies' feasibility and effectiveness. We propose Vid2Real HRI, a research framework to maximize real-world insights offered by video-based studies. The Vid2Real HRI framework was used to design an online study using first-person videos of robots as real-world encounter surrogates. The online study ($n = 385$) distinguished the within-subjects effects of four robot behavioral conditions on perceived social intelligence and human willingness to help the robot enter an exterior door. A real-world, between-subjects replication ($n = 26$) using two conditions confirmed the validity of the online study's findings and the sufficiency of the participant recruitment target ($22$) based on a power analysis of online study results. The Vid2Real HRI framework offers HRI researchers a principled way to take advantage of the efficiency of video-based study modalities while generating directly transferable knowledge of real-world HRI. Code and data from the study are provided at https://vid2real.github.io/vid2realHRI
Influencing Incidental Human-Robot Encounters: Expressive movement improves pedestrians' impressions of a quadruped service robot
Nov 08, 2023



A single mobile service robot may generate hundreds of encounters with pedestrians, yet there is little published data on the factors influencing these incidental human-robot encounters. We report the results of a between-subjects experiment (n=222) testing the impact of robot body language, defined as non-functional modifications to robot movement, upon incidental pedestrian encounters with a quadruped service robot in a real-world setting. We find that canine-inspired body language had a positive influence on participants' perceptions of the robot compared to the robot's stock movement. This effect was visible across all questions of a questionnaire on the perceptions of robots (Godspeed). We argue that body language is a promising and practical design space for improving pedestrian encounters with service robots.
Dobby: A Conversational Service Robot Driven by GPT-4
Oct 10, 2023



This work introduces a robotics platform which embeds a conversational AI agent in an embodied system for natural language understanding and intelligent decision-making for service tasks; integrating task planning and human-like conversation. The agent is derived from a large language model, which has learned from a vast corpus of general knowledge. In addition to generating dialogue, this agent can interface with the physical world by invoking commands on the robot; seamlessly merging communication and behavior. This system is demonstrated in a free-form tour-guide scenario, in an HRI study combining robots with and without conversational AI capabilities. Performance is measured along five dimensions: overall effectiveness, exploration abilities, scrutinization abilities, receptiveness to personification, and adaptability.
Propagating Semantic Labels in Video Data
Oct 01, 2023



Semantic Segmentation combines two sub-tasks: the identification of pixel-level image masks and the application of semantic labels to those masks. Recently, so-called Foundation Models have been introduced; general models trained on very large datasets which can be specialized and applied to more specific tasks. One such model, the Segment Anything Model (SAM), performs image segmentation. Semantic segmentation systems such as CLIPSeg and MaskRCNN are trained on datasets of paired segments and semantic labels. Manual labeling of custom data, however, is time-consuming. This work presents a method for performing segmentation for objects in video. Once an object has been found in a frame of video, the segment can then be propagated to future frames; thus reducing manual annotation effort. The method works by combining SAM with Structure from Motion (SfM). The video input to the system is first reconstructed into 3D geometry using SfM. A frame of video is then segmented using SAM. Segments identified by SAM are then projected onto the the reconstructed 3D geometry. In subsequent video frames, the labeled 3D geometry is reprojected into the new perspective, allowing SAM to be invoked fewer times. System performance is evaluated, including the contributions of the SAM and SfM components. Performance is evaluated over three main metrics: computation time, mask IOU with manual labels, and the number of tracking losses. Results demonstrate that the system has substantial computation time improvements over human performance for tracking objects over video frames, but suffers in performance.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Automatic Sign Reading and Localization for Semantic Mapping with an Office Robot
Sep 23, 2022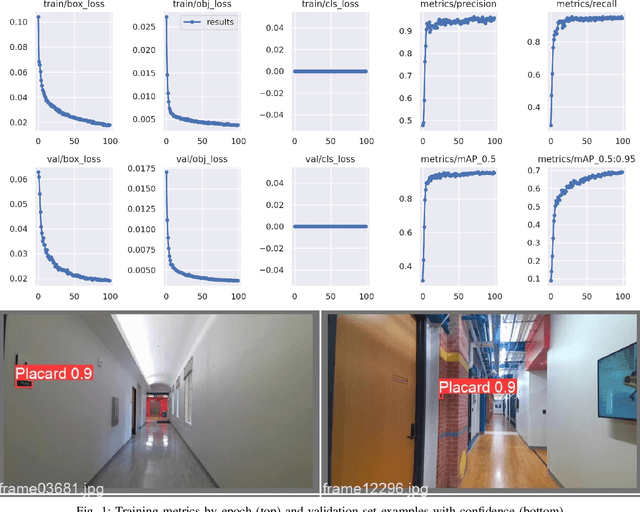

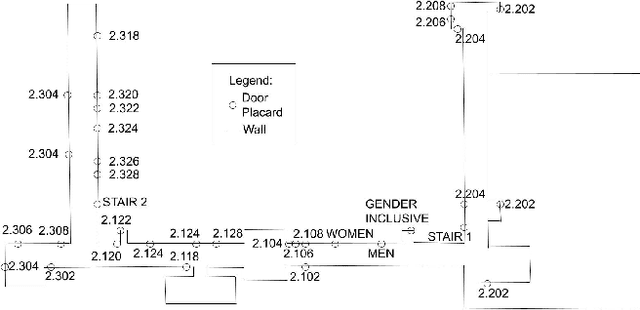
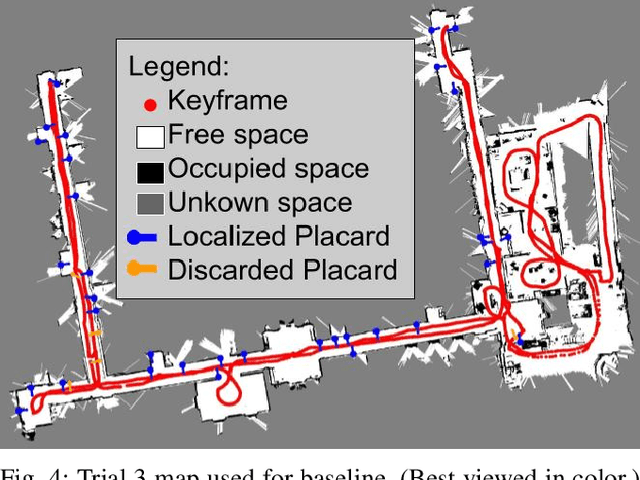
Semantic mapping is the task of providing a robot with a map of its environment beyond the open, navigable space of traditional Simultaneous Localization and Mapping (SLAM) algorithms by attaching semantics to locations. The system presented in this work reads door placards to annotate the locations of offices. Whereas prior work on this system developed hand-crafted detectors, this system leverages YOLOv5 for sign detection and EAST for text recognition. Placards are localized by computing their pose from a point cloud in a RGB-D camera frame localized by a modified ORB-SLAM. Semantic mapping is accomplished in a post-processing step after robot exploration from video recording. System performance is reported in terms of the number of placards identified, the accuracy of their placement onto a SLAM map, the accuracy of the map built, and the correctness transcribed placard text.
Socially Compliant Navigation Dataset (SCAND): A Large-Scale Dataset of Demonstrations for Social Navigation
Mar 28, 2022


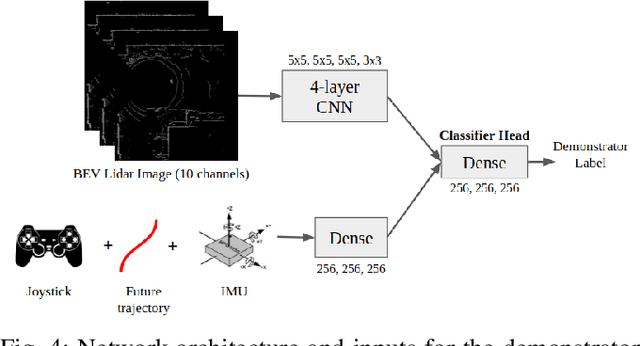
Social navigation is the capability of an autonomous agent, such as a robot, to navigate in a 'socially compliant' manner in the presence of other intelligent agents such as humans. With the emergence of autonomously navigating mobile robots in human populated environments (e.g., domestic service robots in homes and restaurants and food delivery robots on public sidewalks), incorporating socially compliant navigation behaviors on these robots becomes critical to ensuring safe and comfortable human robot coexistence. To address this challenge, imitation learning is a promising framework, since it is easier for humans to demonstrate the task of social navigation rather than to formulate reward functions that accurately capture the complex multi objective setting of social navigation. The use of imitation learning and inverse reinforcement learning to social navigation for mobile robots, however, is currently hindered by a lack of large scale datasets that capture socially compliant robot navigation demonstrations in the wild. To fill this gap, we introduce Socially CompliAnt Navigation Dataset (SCAND) a large scale, first person view dataset of socially compliant navigation demonstrations. Our dataset contains 8.7 hours, 138 trajectories, 25 miles of socially compliant, human teleoperated driving demonstrations that comprises multi modal data streams including 3D lidar, joystick commands, odometry, visual and inertial information, collected on two morphologically different mobile robots a Boston Dynamics Spot and a Clearpath Jackal by four different human demonstrators in both indoor and outdoor environments. We additionally perform preliminary analysis and validation through real world robot experiments and show that navigation policies learned by imitation learning on SCAND generate socially compliant behaviors
Efficient Placard Discovery for Semantic Mapping During Frontier Exploration
Oct 27, 2021
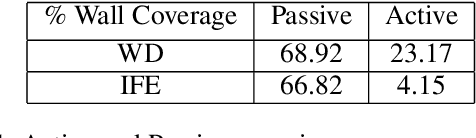

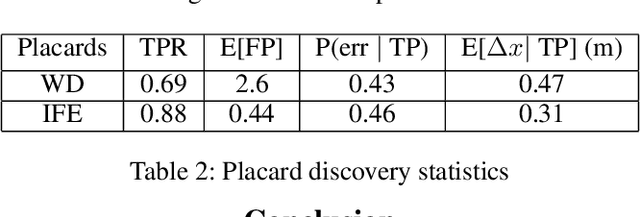
Semantic mapping is the task of providing a robot with a map of its environment beyond the open, navigable space of traditional Simultaneous Localization and Mapping (SLAM) algorithms by attaching semantics to locations. The system presented in this work reads door placards to annotate the locations of offices. Whereas prior work on this system developed hand-crafted detectors, this system leverages YOLOv2 for detection and a segmentation network for segmentation. Placards are localized by computing their pose from a homography computed from a segmented quadrilateral outline. This work also introduces an Interruptable Frontier Exploration algorithm, enabling the robot to explore its environment to construct its SLAM map while pausing to inspect placards observed during this process. This allows the robot to autonomously discover room placards without human intervention while speeding up significantly over previous autonomous exploration methods.
AI-HRI 2021 Proceedings
Sep 23, 2021The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. During that time, these symposia provided a fertile ground for numerous collaborations and pioneered many discussions revolving trust in HRI, XAI for HRI, service robots, interactive learning, and more. This year, we aim to review the achievements of the AI-HRI community in the last decade, identify the challenges facing ahead, and welcome new researchers who wish to take part in this growing community. Taking this wide perspective, this year there will be no single theme to lead the symposium and we encourage AI-HRI submissions from across disciplines and research interests. Moreover, with the rising interest in AR and VR as part of an interaction and following the difficulties in running physical experiments during the pandemic, this year we specifically encourage researchers to submit works that do not include a physical robot in their evaluation, but promote HRI research in general. In addition, acknowledging that ethics is an inherent part of the human-robot interaction, we encourage submissions of works on ethics for HRI. Over the course of the two-day meeting, we will host a collaborative forum for discussion of current efforts in AI-HRI, with additional talks focused on the topics of ethics in HRI and ubiquitous HRI.
Incorporating Gaze into Social Navigation
Jul 10, 2021

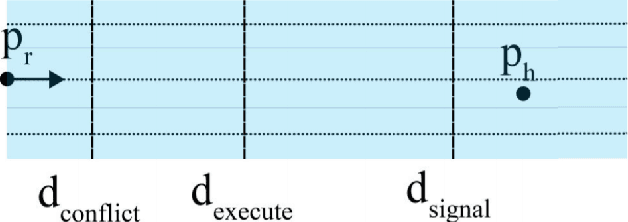
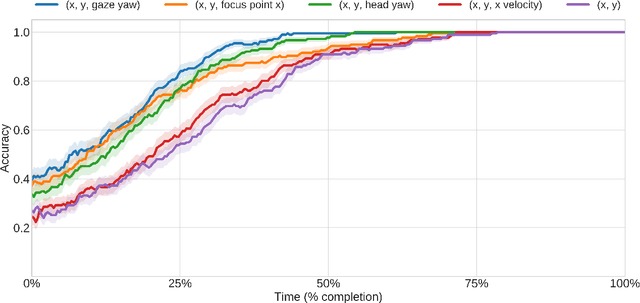
Most current approaches to social navigation focus on the trajectory and position of participants in the interaction. Our current work on the topic focuses on integrating gaze into social navigation, both to cue nearby pedestrians as to the intended trajectory of the robot and to enable the robot to read the intentions of nearby pedestrians. This paper documents a series of experiments in our laboratory investigating the role of gaze in social navigation.