 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiQi-Agent: Aligning Vision, Tools and Aesthetics in Multimodal Agent for Cultural Reasoning on Chinese Porcelains
Mar 30, 2026The connoisseurship of antique Chinese porcelain demands extensive historical expertise, material understanding, and aesthetic sensitivity, making it difficult for non-specialists to engage. To democratize cultural-heritage understanding and assist expert connoisseurship, we introduce CiQi-Agent -- a domain-specific Porcelain Connoisseurship Agent for intelligent analysis of antique Chinese porcelain. CiQi-Agent supports multi-image porcelain inputs and enables vision tool invocation and multimodal retrieval-augmented generation, performing fine-grained connoisseurship analysis across six attributes: dynasty, reign period, kiln site, glaze color, decorative motif, and vessel shape. Beyond attribute classification, it captures subtle visual details, retrieves relevant domain knowledge, and integrates visual and textual evidence to produce coherent, explainable connoisseurship descriptions. To achieve this capability, we construct a large-scale, expert-annotated dataset CiQi-VQA, comprising 29,596 porcelain specimens, 51,553 images, and 557,940 visual question--answering pairs, and further establish a comprehensive benchmark CiQi-Bench aligned with the previously mentioned six attributes. CiQi-Agent is trained through supervised fine-tuning, reinforcement learning, and a tool-augmented reasoning framework that integrates two categories of tools: a vision tool and multimodal retrieval tools. Experimental results show that CiQi-Agent (7B) outperforms all competitive open- and closed-source models across all six attributes on CiQi-Bench, achieving on average 12.2\% higher accuracy than GPT-5. The model and dataset have been released and are publicly available at https://huggingface.co/datasets/SII-Monument-Valley/CiQi-VQA.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback
Mar 12, 2026Standard reinforcement learning (RL) for large language model (LLM)-based agents typically optimizes extrinsic task-success rewards, prioritizing one-off task solving over continual adaptation. As a result, agents may converge to suboptimal policies due to limited exploration, and accumulated experience remains implicitly stored in model parameters, hindering efficient experiential learning. Inspired by humans' capacity for retrospective self-improvement, we introduce RetroAgent, an online RL framework that enables agents to master complex interactive environments not only by solving, but also by evolving under the joint guidance of extrinsic task-success rewards and retrospective dual intrinsic feedback. Concretely, RetroAgent features a hindsight self-reflection mechanism that produces: (1) intrinsic numerical feedback, which tracks incremental subtask completion relative to prior attempts to reward promising exploration; and (2) intrinsic language feedback, which distills reusable lessons into a memory buffer retrieved via our proposed Similarity & Utility-Aware Upper Confidence Bound (SimUtil-UCB) strategy, jointly balancing relevance, utility, and exploration. Extensive experiments across four challenging agentic tasks show that RetroAgent achieves state-of-the-art (SOTA) performance, substantially outperforming RL fine-tuning, memory-augmented RL, exploration-guided RL, and meta-RL methods -- e.g., exceeding Group Relative Policy Optimization (GRPO)-trained agents by +18.3% on ALFWorld, +15.4% on WebShop, +27.1% on Sokoban, and +8.9% on MineSweeper -- while maintaining strong test-time adaptation and out-of-distribution generalization.
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
More Than One Teacher: Adaptive Multi-Guidance Policy Optimization for Diverse Exploration
Oct 02, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) is a promising paradigm for enhancing the reasoning ability in Large Language Models (LLMs). However, prevailing methods primarily rely on self-exploration or a single off-policy teacher to elicit long chain-of-thought (LongCoT) reasoning, which may introduce intrinsic model biases and restrict exploration, ultimately limiting reasoning diversity and performance. Drawing inspiration from multi-teacher strategies in knowledge distillation, we introduce Adaptive Multi-Guidance Policy Optimization (AMPO), a novel framework that adaptively leverages guidance from multiple proficient teacher models, but only when the on-policy model fails to generate correct solutions. This "guidance-on-demand" approach expands exploration while preserving the value of self-discovery. Moreover, AMPO incorporates a comprehension-based selection mechanism, prompting the student to learn from the reasoning paths that it is most likely to comprehend, thus balancing broad exploration with effective exploitation. Extensive experiments show AMPO substantially outperforms a strong baseline (GRPO), with a 4.3% improvement on mathematical reasoning tasks and 12.2% on out-of-distribution tasks, while significantly boosting Pass@k performance and enabling more diverse exploration. Notably, using four peer-sized teachers, our method achieves comparable results to approaches that leverage a single, more powerful teacher (e.g., DeepSeek-R1) with more data. These results demonstrate a more efficient and scalable path to superior reasoning and generalizability. Our code is available at https://github.com/SII-Enigma/AMPO.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
MDK12-Bench: A Comprehensive Evaluation of Multimodal Large Language Models on Multidisciplinary Exams
Aug 09, 2025Multimodal large language models (MLLMs), which integrate language and visual cues for problem-solving, are crucial for advancing artificial general intelligence (AGI). However, current benchmarks for measuring the intelligence of MLLMs suffer from limited scale, narrow coverage, and unstructured knowledge, offering only static and undifferentiated evaluations. To bridge this gap, we introduce MDK12-Bench, a large-scale multidisciplinary benchmark built from real-world K-12 exams spanning six disciplines with 141K instances and 6,225 knowledge points organized in a six-layer taxonomy. Covering five question formats with difficulty and year annotations, it enables comprehensive evaluation to capture the extent to which MLLMs perform over four dimensions: 1) difficulty levels, 2) temporal (cross-year) shifts, 3) contextual shifts, and 4) knowledge-driven reasoning. We propose a novel dynamic evaluation framework that introduces unfamiliar visual, textual, and question form shifts to challenge model generalization while improving benchmark objectivity and longevity by mitigating data contamination. We further evaluate knowledge-point reference-augmented generation (KP-RAG) to examine the role of knowledge in problem-solving. Key findings reveal limitations in current MLLMs in multiple aspects and provide guidance for enhancing model robustness, interpretability, and AI-assisted education.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025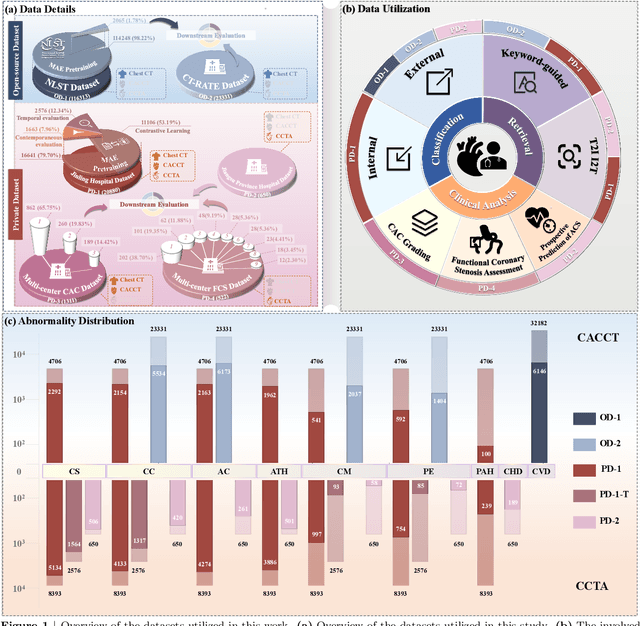
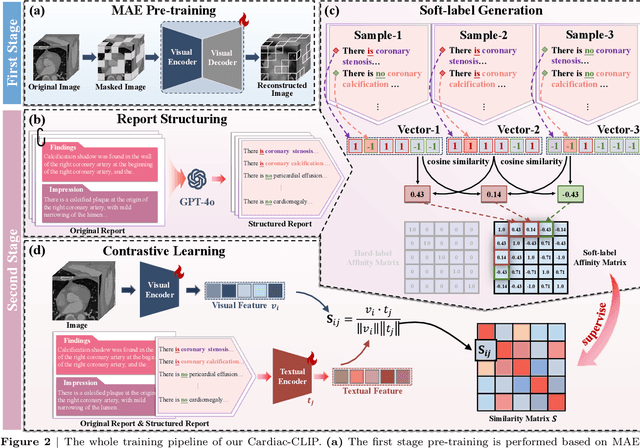
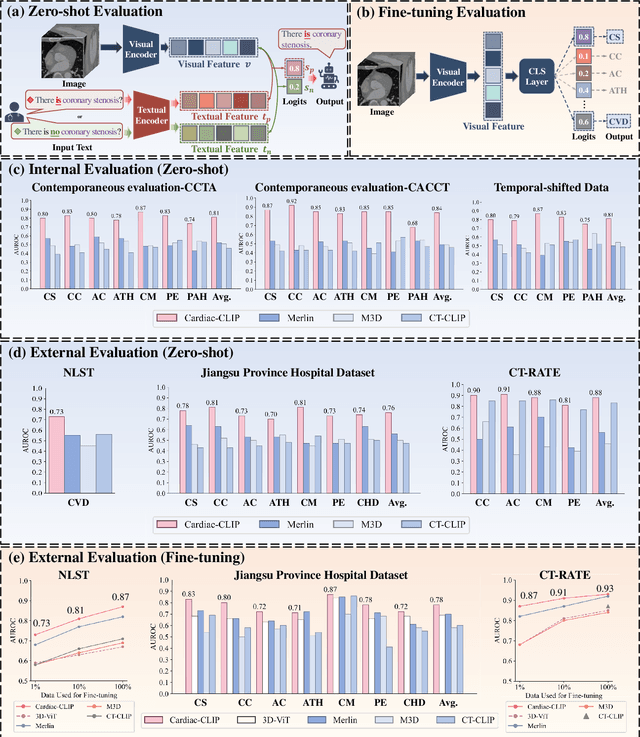
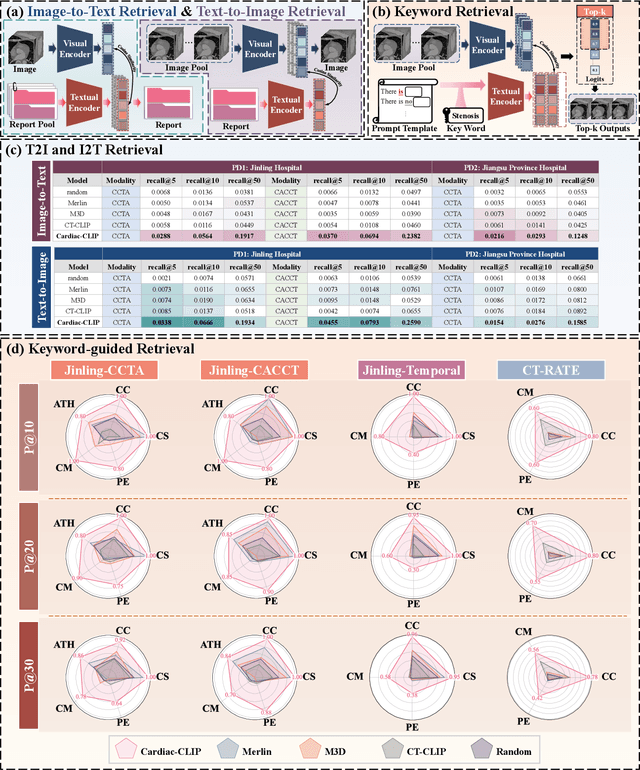
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Flow-Anything: Learning Real-World Optical Flow Estimation from Large-Scale Single-view Images
Jun 09, 2025Optical flow estimation is a crucial subfield of computer vision, serving as a foundation for video tasks. However, the real-world robustness is limited by animated synthetic datasets for training. This introduces domain gaps when applied to real-world applications and limits the benefits of scaling up datasets. To address these challenges, we propose \textbf{Flow-Anything}, a large-scale data generation framework designed to learn optical flow estimation from any single-view images in the real world. We employ two effective steps to make data scaling-up promising. First, we convert a single-view image into a 3D representation using advanced monocular depth estimation networks. This allows us to render optical flow and novel view images under a virtual camera. Second, we develop an Object-Independent Volume Rendering module and a Depth-Aware Inpainting module to model the dynamic objects in the 3D representation. These two steps allow us to generate realistic datasets for training from large-scale single-view images, namely \textbf{FA-Flow Dataset}. For the first time, we demonstrate the benefits of generating optical flow training data from large-scale real-world images, outperforming the most advanced unsupervised methods and supervised methods on synthetic datasets. Moreover, our models serve as a foundation model and enhance the performance of various downstream video tasks.