 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth-ORSC-Bench: A Benchmark for Measuring Over-Refusal and Safety Completion in Health Context
Jan 25, 2026Safety alignment in Large Language Models is critical for healthcare; however, reliance on binary refusal boundaries often results in \emph{over-refusal} of benign queries or \emph{unsafe compliance} with harmful ones. While existing benchmarks measure these extremes, they fail to evaluate Safe Completion: the model's ability to maximise helpfulness on dual-use or borderline queries by providing safe, high-level guidance without crossing into actionable harm. We introduce \textbf{Health-ORSC-Bench}, the first large-scale benchmark designed to systematically measure \textbf{Over-Refusal} and \textbf{Safe Completion} quality in healthcare. Comprising 31,920 benign boundary prompts across seven health categories (e.g., self-harm, medical misinformation), our framework uses an automated pipeline with human validation to test models at varying levels of intent ambiguity. We evaluate 30 state-of-the-art LLMs, including GPT-5 and Claude-4, revealing a significant tension: safety-optimised models frequently refuse up to 80\% of "Hard" benign prompts, while domain-specific models often sacrifice safety for utility. Our findings demonstrate that model family and size significantly influence calibration: larger frontier models (e.g., GPT-5, Llama-4) exhibit "safety-pessimism" and higher over-refusal than smaller or MoE-based counterparts (e.g., Qwen-3-Next), highlighting that current LLMs struggle to balance refusal and compliance. Health-ORSC-Bench provides a rigorous standard for calibrating the next generation of medical AI assistants toward nuanced, safe, and helpful completions. The code and data will be released upon acceptance. \textcolor{red}{Warning: Some contents may include toxic or undesired contents.}
VISPA: Pluralistic Alignment via Automatic Value Selection and Activation
Jan 19, 2026As large language models are increasingly used in high-stakes domains, it is essential that their outputs reflect not average} human preference, rather range of varying perspectives. Achieving such pluralism, however, remains challenging. Existing approaches consider limited values or rely on prompt-level interventions, lacking value control and representation. To address this, we introduce VISPA, a training-free pluralistic alignment framework, that enables direct control over value expression by dynamic selection and internal model activation steering. Across extensive empirical studies spanning multiple models and evaluation settings, we show VISPA is performant across all pluralistic alignment modes in healthcare and beyond. Further analysis reveals VISPA is adaptable with different steering initiations, model, and/or values. These results suggest that pluralistic alignment can be achieved through internal activation mechanisms, offering a scalable path toward language models that serves all.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
PEARL: Self-Evolving Assistant for Time Management with Reinforcement Learning
Jan 17, 2026Overlapping calendar invitations force busy professionals to repeatedly decide which meetings to attend, reschedule, or decline. We refer to this preference-driven decision process as calendar conflict resolution. Automating such process is crucial yet challenging. Scheduling logistics drain hours, and human delegation often fails at scale, which motivate we to ask: Can we trust large language model (LLM) or language agent to manager time? To enable systematic study of this question, we introduce CalConflictBench, a benchmark for long-horizon calendar conflict resolution. Conflicts are presented sequentially and agents receive feedback after each round, requiring them to infer and adapt to user preferences progressively. Our experiments show that current LLM agents perform poorly with high error rates, e.g., Qwen-3-30B-Think has 35% average error rate. To address this gap, we propose PEARL, a reinforcement-learning framework that augments language agent with an external memory module and optimized round-wise reward design, enabling agent to progressively infer and adapt to user preferences on-the-fly. Experiments on CalConflictBench shows that PEARL achieves 0.76 error reduction rate, and 55% improvement in average error rate compared to the strongest baseline.
Current Agents Fail to Leverage World Model as Tool for Foresight
Jan 08, 2026Agents built on vision-language models increasingly face tasks that demand anticipating future states rather than relying on short-horizon reasoning. Generative world models offer a promising remedy: agents could use them as external simulators to foresee outcomes before acting. This paper empirically examines whether current agents can leverage such world models as tools to enhance their cognition. Across diverse agentic and visual question answering tasks, we observe that some agents rarely invoke simulation (fewer than 1%), frequently misuse predicted rollouts (approximately 15%), and often exhibit inconsistent or even degraded performance (up to 5%) when simulation is available or enforced. Attribution analysis further indicates that the primary bottleneck lies in the agents' capacity to decide when to simulate, how to interpret predicted outcomes, and how to integrate foresight into downstream reasoning. These findings underscore the need for mechanisms that foster calibrated, strategic interaction with world models, paving the way toward more reliable anticipatory cognition in future agent systems.
Beyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
Adaptation of Agentic AI
Dec 22, 2025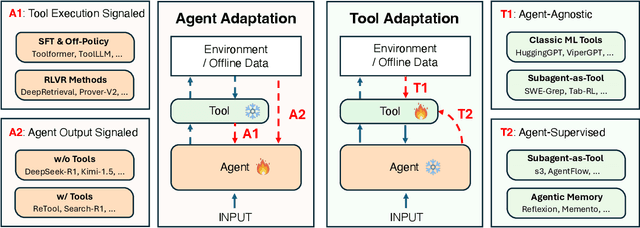
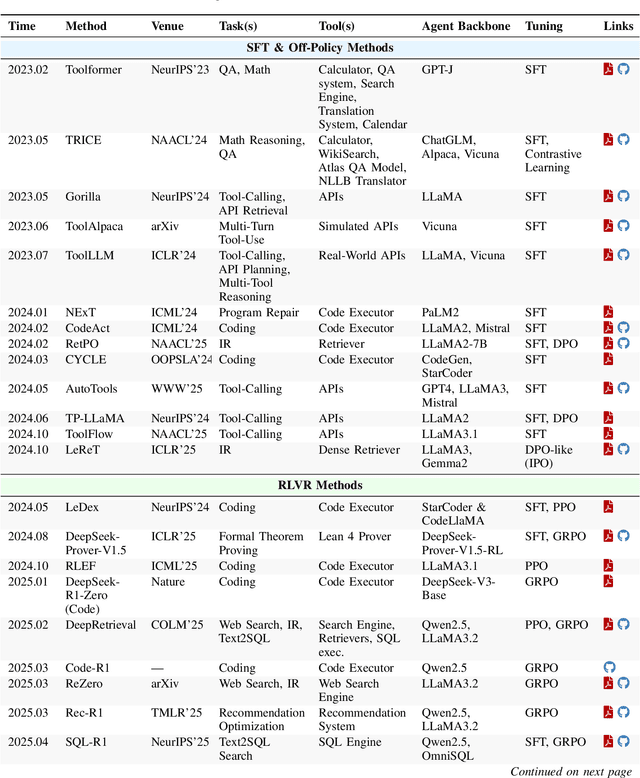
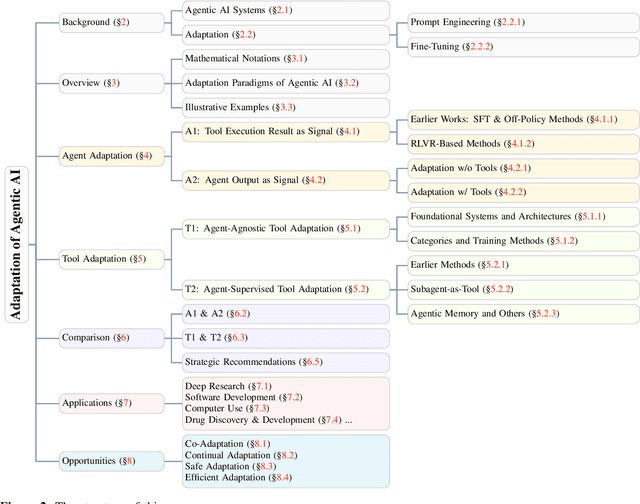
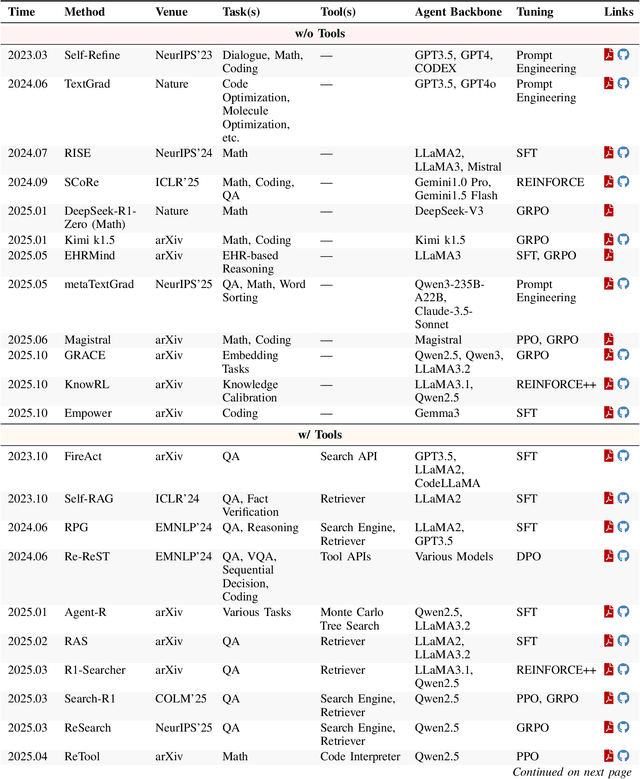
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
From Word to World: Can Large Language Models be Implicit Text-based World Models?
Dec 21, 2025Agentic reinforcement learning increasingly relies on experience-driven scaling, yet real-world environments remain non-adaptive, limited in coverage, and difficult to scale. World models offer a potential way to improve learning efficiency through simulated experience, but it remains unclear whether large language models can reliably serve this role and under what conditions they meaningfully benefit agents. We study these questions in text-based environments, which provide a controlled setting to reinterpret language modeling as next-state prediction under interaction. We introduce a three-level framework for evaluating LLM-based world models: (i) fidelity and consistency, (ii) scalability and robustness, and (iii) agent utility. Across five representative environments, we find that sufficiently trained world models maintain coherent latent state, scale predictably with data and model size, and improve agent performance via action verification, synthetic trajectory generation, and warm-starting reinforcement learning. Meanwhile, these gains depend critically on behavioral coverage and environment complexity, delineating clear boundry on when world modeling effectively supports agent learning.
SpeakRL: Synergizing Reasoning, Speaking, and Acting in Language Models with Reinforcement Learning
Dec 15, 2025



Effective human-agent collaboration is increasingly prevalent in real-world applications. Current trends in such collaborations are predominantly unidirectional, with users providing instructions or posing questions to agents, where agents respond directly without seeking necessary clarifications or confirmations. However, the evolving capabilities of these agents require more proactive engagement, where agents should dynamically participate in conversations to clarify user intents, resolve ambiguities, and adapt to changing circumstances. Existing prior work under-utilize the conversational capabilities of language models (LMs), thereby optimizing agents as better followers rather than effective speakers. In this work, we introduce SpeakRL, a reinforcement learning (RL) method that enhances agents' conversational capabilities by rewarding proactive interactions with users, such as asking right clarification questions when necessary. To support this, we curate SpeakER, a synthetic dataset that includes diverse scenarios from task-oriented dialogues, where tasks are resolved through interactive clarification questions. We present a systematic analysis of reward design for conversational proactivity and propose a principled reward formulation for teaching agents to balance asking with acting. Empirical evaluations demonstrate that our approach achieves a 20.14% absolute improvement in task completion over base models without increasing conversation turns even surpassing even much larger proprietary models, demonstrating the promise of clarification-centric user-agent interactions.
MAC: A Multi-Agent Framework for Interactive User Clarification in Multi-turn Conversations
Dec 15, 2025Conversational agents often encounter ambiguous user requests, requiring an effective clarification to successfully complete tasks. While recent advancements in real-world applications favor multi-agent architectures to manage complex conversational scenarios efficiently, ambiguity resolution remains a critical and underexplored challenge--particularly due to the difficulty of determining which agent should initiate a clarification and how agents should coordinate their actions when faced with uncertain or incomplete user input. The fundamental questions of when to interrupt a user and how to formulate the optimal clarification query within the most optimal multi-agent settings remain open. In this paper, we propose MAC (Multi-Agent Clarification), an interactive multi-agent framework specifically optimized to resolve user ambiguities by strategically managing clarification dialogues. We first introduce a novel taxonomy categorizing user ambiguities to systematically guide clarification strategies. Then, we present MAC that autonomously coordinates multiple agents to interact synergistically with users. Empirical evaluations on MultiWOZ 2.4 demonstrate that enabling clarification at both levels increases task success rate 7.8\% (54.5 to 62.3) and reduces the average number of dialogue turns (6.53 to 4.86) by eliciting all required user information up front and minimizing repetition. Our findings highlight the importance of active user interaction and role-aware clarification for more reliable human-agent communication.