 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
Mar 19, 2026We introduce Nemotron-Cascade 2, an open 30B MoE model with 3B activated parameters that delivers best-in-class reasoning and strong agentic capabilities. Despite its compact size, its mathematical and coding reasoning performance approaches that of frontier open models. It is the second open-weight LLM, after DeepSeekV3.2-Speciale-671B-A37B, to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, demonstrating remarkably high intelligence density with 20x fewer parameters. In contrast to Nemotron-Cascade 1, the key technical advancements are as follows. After SFT on a meticulously curated dataset, we substantially expand Cascade RL to cover a much broader spectrum of reasoning and agentic domains. Furthermore, we introduce multi-domain on-policy distillation from the strongest intermediate teacher models for each domain throughout the Cascade RL process, allowing us to efficiently recover benchmark regressions and sustain strong performance gains along the way. We release the collection of model checkpoint and training data.
Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models
Dec 15, 2025



Building general-purpose reasoning models with reinforcement learning (RL) entails substantial cross-domain heterogeneity, including large variation in inference-time response lengths and verification latency. Such variability complicates the RL infrastructure, slows training, and makes training curriculum (e.g., response length extension) and hyperparameter selection challenging. In this work, we propose cascaded domain-wise reinforcement learning (Cascade RL) to develop general-purpose reasoning models, Nemotron-Cascade, capable of operating in both instruct and deep thinking modes. Departing from conventional approaches that blend heterogeneous prompts from different domains, Cascade RL orchestrates sequential, domain-wise RL, reducing engineering complexity and delivering state-of-the-art performance across a wide range of benchmarks. Notably, RLHF for alignment, when used as a pre-step, boosts the model's reasoning ability far beyond mere preference optimization, and subsequent domain-wise RLVR stages rarely degrade the benchmark performance attained in earlier domains and may even improve it (see an illustration in Figure 1). Our 14B model, after RL, outperforms its SFT teacher, DeepSeek-R1-0528, on LiveCodeBench v5/v6/Pro and achieves silver-medal performance in the 2025 International Olympiad in Informatics (IOI). We transparently share our training and data recipes.
Perception-Aware Policy Optimization for Multimodal Reasoning
Jul 08, 2025
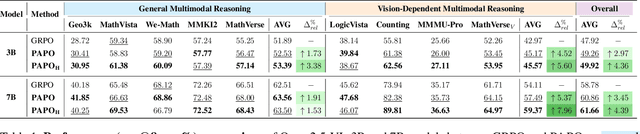
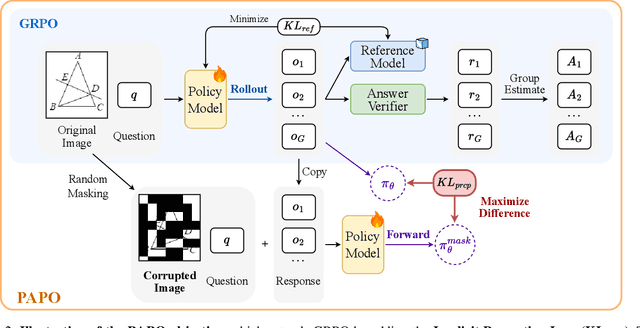
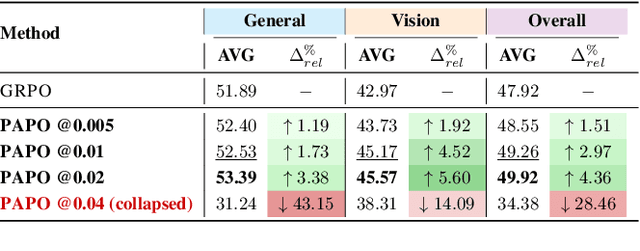
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.
Prioritizing Image-Related Tokens Enhances Vision-Language Pre-Training
May 13, 2025



In standard large vision-language models (LVLMs) pre-training, the model typically maximizes the joint probability of the caption conditioned on the image via next-token prediction (NTP); however, since only a small subset of caption tokens directly relates to the visual content, this naive NTP unintentionally fits the model to noise and increases the risk of hallucination. We present PRIOR, a simple vision-language pre-training approach that addresses this issue by prioritizing image-related tokens through differential weighting in the NTP loss, drawing from the importance sampling framework. PRIOR introduces a reference model-a text-only large language model (LLM) trained on the captions without image inputs, to weight each token based on its probability for LVLMs training. Intuitively, tokens that are directly related to the visual inputs are harder to predict without the image and thus receive lower probabilities from the text-only reference LLM. During training, we implement a token-specific re-weighting term based on the importance scores to adjust each token's loss. We implement PRIOR in two distinct settings: LVLMs with visual encoders and LVLMs without visual encoders. We observe 19% and 8% average relative improvement, respectively, on several vision-language benchmarks compared to NTP. In addition, PRIOR exhibits superior scaling properties, as demonstrated by significantly higher scaling coefficients, indicating greater potential for performance gains compared to NTP given increasing compute and data.
SyncMind: Measuring Agent Out-of-Sync Recovery in Collaborative Software Engineering
Feb 10, 2025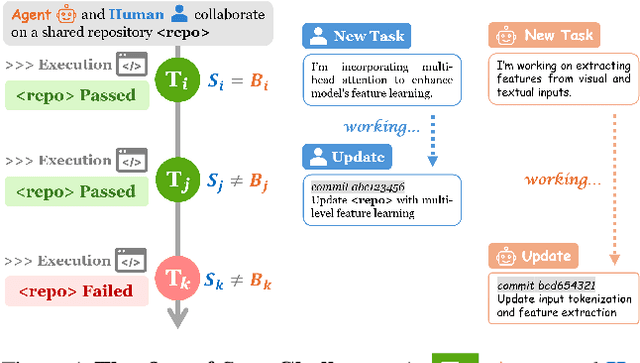
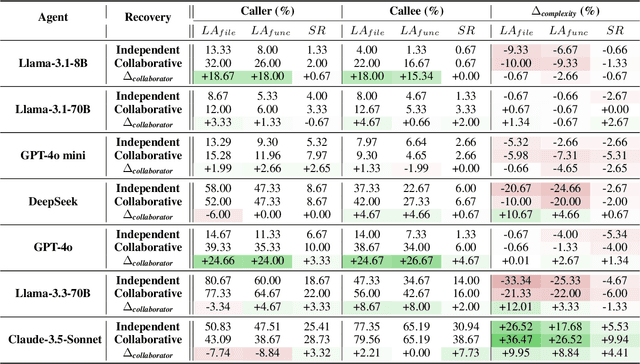


Software engineering (SE) is increasingly collaborative, with developers working together on shared complex codebases. Effective collaboration in shared environments requires participants -- whether humans or AI agents -- to stay on the same page as their environment evolves. When a collaborator's understanding diverges from the current state -- what we term the out-of-sync challenge -- the collaborator's actions may fail, leading to integration issues. In this work, we introduce SyncMind, a framework that systematically defines the out-of-sync problem faced by large language model (LLM) agents in collaborative software engineering (CSE). Based on SyncMind, we create SyncBench, a benchmark featuring 24,332 instances of agent out-of-sync scenarios in real-world CSE derived from 21 popular GitHub repositories with executable verification tests. Experiments on SyncBench uncover critical insights into existing LLM agents' capabilities and limitations. Besides substantial performance gaps among agents (from Llama-3.1 agent <= 3.33% to Claude-3.5-Sonnet >= 28.18%), their consistently low collaboration willingness (<= 4.86%) suggests fundamental limitations of existing LLM in CSE. However, when collaboration occurs, it positively correlates with out-of-sync recovery success. Minimal performance differences in agents' resource-aware out-of-sync recoveries further reveal their significant lack of resource awareness and adaptability, shedding light on future resource-efficient collaborative systems. Code and data are openly available on our project website: https://xhguo7.github.io/SyncMind/.
OpenOmni: Large Language Models Pivot Zero-shot Omnimodal Alignment across Language with Real-time Self-Aware Emotional Speech Synthesis
Jan 08, 2025



Recent advancements in omnimodal learning have been achieved in understanding and generation across images, text, and speech, though mainly within proprietary models. Limited omnimodal datasets and the inherent challenges associated with real-time emotional speech generation have hindered open-source progress. To address these issues, we propose openomni, a two-stage training method combining omnimodal alignment and speech generation to develop a state-of-the-art omnimodal large language model. In the alignment phase, a pre-trained speech model is further trained on text-image tasks to generalize from vision to speech in a (near) zero-shot manner, outperforming models trained on tri-modal datasets. In the speech generation phase, a lightweight decoder facilitates real-time emotional speech through training on speech tasks and preference learning. Experiments demonstrate that openomni consistently improves across omnimodal, vision-language, and speech-language evaluations, enabling natural, emotion-rich dialogues and real-time emotional speech generation.
Scaling Laws for Predicting Downstream Performance in LLMs
Oct 11, 2024



Precise estimation of downstream performance in large language models (LLMs) prior to training is essential for guiding their development process. Scaling laws analysis utilizes the statistics of a series of significantly smaller sampling language models (LMs) to predict the performance of the target LLM. For downstream performance prediction, the critical challenge lies in the emergent abilities in LLMs that occur beyond task-specific computational thresholds. In this work, we focus on the pre-training loss as a more computation-efficient metric for performance estimation. Our two-stage approach consists of first estimating a function that maps computational resources (e.g., FLOPs) to the pre-training Loss using a series of sampling models, followed by mapping the pre-training loss to downstream task Performance after the critical "emergent phase". In preliminary experiments, this FLP solution accurately predicts the performance of LLMs with 7B and 13B parameters using a series of sampling LMs up to 3B, achieving error margins of 5% and 10%, respectively, and significantly outperforming the FLOPs-to-Performance approach. This motivates FLP-M, a fundamental approach for performance prediction that addresses the practical need to integrate datasets from multiple sources during pre-training, specifically blending general corpora with code data to accurately represent the common necessity. FLP-M extends the power law analytical function to predict domain-specific pre-training loss based on FLOPs across data sources, and employs a two-layer neural network to model the non-linear relationship between multiple domain-specific loss and downstream performance. By utilizing a 3B LLM trained on a specific ratio and a series of smaller sampling LMs, FLP-M can effectively forecast the performance of 3B and 7B LLMs across various data mixtures for most benchmarks within 10% error margins.
A Single Transformer for Scalable Vision-Language Modeling
Jul 08, 2024



We present SOLO, a single transformer for Scalable visiOn-Language mOdeling. Current large vision-language models (LVLMs) such as LLaVA mostly employ heterogeneous architectures that connect pre-trained visual encoders with large language models (LLMs) to facilitate visual recognition and complex reasoning. Although achieving remarkable performance with relatively lightweight training, we identify four primary scalability limitations: (1) The visual capacity is constrained by pre-trained visual encoders, which are typically an order of magnitude smaller than LLMs. (2) The heterogeneous architecture complicates the use of established hardware and software infrastructure. (3) Study of scaling laws on such architecture must consider three separate components - visual encoder, connector, and LLMs, which complicates the analysis. (4) The use of existing visual encoders typically requires following a pre-defined specification of image inputs pre-processing, for example, by reshaping inputs to fixed-resolution square images, which presents difficulties in processing and training on high-resolution images or those with unusual aspect ratio. A unified single Transformer architecture, like SOLO, effectively addresses these scalability concerns in LVLMs; however, its limited adoption in the modern context likely stems from the absence of reliable training recipes that balance both modalities and ensure stable training for billion-scale models. In this paper, we introduce the first open-source training recipe for developing SOLO, an open-source 7B LVLM using moderate academic resources. The training recipe involves initializing from LLMs, sequential pre-training on ImageNet and web-scale data, and instruction fine-tuning on our curated high-quality datasets. On extensive evaluation, SOLO demonstrates performance comparable to LLaVA-v1.5-7B, particularly excelling in visual mathematical reasoning.