 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Adam? Surprisingly Strong and Sparse Reinforcement Learning with SGD in LLMs
Feb 07, 2026Reinforcement learning (RL), particularly RL from verifiable reward (RLVR), has become a crucial phase of training large language models (LLMs) and a key focus of current scaling efforts. However, optimization practices in RL largely follow those of next-token prediction stages (e.g., pretraining and supervised fine-tuning), despite fundamental differences between RL and these stages highlighted by recent work. One such practice is the use of the AdamW optimizer, which is widely adopted for training large-scale transformers despite its high memory overhead. Our analysis shows that both momentum and adaptive learning rates in AdamW are less influential in RL than in SFT, leading us to hypothesize that RL benefits less from Adam-style per-parameter adaptive learning rates and momentum. Confirming this hypothesis, our experiments demonstrate that the substantially more memory-efficient SGD, which is known to perform poorly in supervised learning of large-scale transformers, matches or even outperforms AdamW in RL for LLMs. Remarkably, full fine-tuning with SGD updates fewer than 0.02% of model parameters without any sparsity-promoting regularization, more than 1000 times fewer than AdamW. Our analysis offers potential reasons for this update sparsity. These findings provide new insights into the optimization dynamics of RL in LLMs and show that RL can be substantially more parameter-efficient than previously recognized.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025



We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025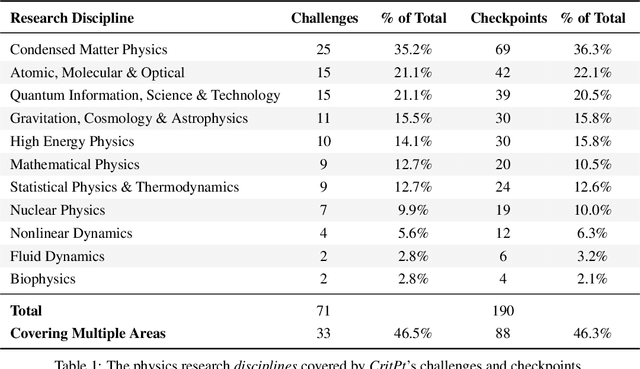



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
May 21, 2025



Entropy minimization (EM) trains the model to concentrate even more probability mass on its most confident outputs. We show that this simple objective alone, without any labeled data, can substantially improve large language models' (LLMs) performance on challenging math, physics, and coding tasks. We explore three approaches: (1) EM-FT minimizes token-level entropy similarly to instruction finetuning, but on unlabeled outputs drawn from the model; (2) EM-RL: reinforcement learning with negative entropy as the only reward to maximize; (3) EM-INF: inference-time logit adjustment to reduce entropy without any training data or parameter updates. On Qwen-7B, EM-RL, without any labeled data, achieves comparable or better performance than strong RL baselines such as GRPO and RLOO that are trained on 60K labeled examples. Furthermore, EM-INF enables Qwen-32B to match or exceed the performance of proprietary models like GPT-4o, Claude 3 Opus, and Gemini 1.5 Pro on the challenging SciCode benchmark, while being 3x more efficient than self-consistency and sequential refinement. Our findings reveal that many pretrained LLMs possess previously underappreciated reasoning capabilities that can be effectively elicited through entropy minimization alone, without any labeled data or even any parameter updates.
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
May 16, 2025



Reinforcement learning (RL) yields substantial improvements in large language models (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from updating only a small subnetwork comprising just 5 percent to 30 percent of the parameters, with the rest effectively unchanged. We refer to this phenomenon as parameter update sparsity induced by RL. It is observed across all 7 widely used RL algorithms (e.g., PPO, GRPO, DPO) and all 10 LLMs from different families in our experiments. This sparsity is intrinsic and occurs without any explicit sparsity promoting regularizations or architectural constraints. Finetuning the subnetwork alone recovers the test accuracy, and, remarkably, produces a model nearly identical to the one obtained via full finetuning. The subnetworks from different random seeds, training data, and even RL algorithms show substantially greater overlap than expected by chance. Our analysis suggests that this sparsity is not due to updating only a subset of layers, instead, nearly all parameter matrices receive similarly sparse updates. Moreover, the updates to almost all parameter matrices are nearly full-rank, suggesting RL updates a small subset of parameters that nevertheless span almost the full subspaces that the parameter matrices can represent. We conjecture that the this update sparsity can be primarily attributed to training on data that is near the policy distribution, techniques that encourage the policy to remain close to the pretrained model, such as the KL regularization and gradient clipping, have limited impact.
Process Reinforcement through Implicit Rewards
Feb 03, 2025



Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
Free Process Rewards without Process Labels
Dec 02, 2024



Different from its counterpart outcome reward models (ORMs), which evaluate the entire responses, a process reward model (PRM) scores a reasoning trajectory step by step, providing denser and more fine grained rewards. However, training a PRM requires labels annotated at every intermediate step, presenting significant challenges for both manual and automatic data collection. This paper aims to address this challenge. Both theoretically and empirically, we show that an \textit{implicit PRM} can be obtained at no additional cost, by simply training an ORM on the cheaper response-level labels. The only assumption is to parameterize the outcome reward as the log-likelihood ratios of the policy and reference models, which can be optimized regardless of the specific choice of loss objectives. In experiments, we instantiate our implicit PRMs with various objectives and evaluate their performance on MATH. We show that our implicit PRM outperforms a strong MCTS-based baseline \textit{\'a la} Math-Shepherd using less than $1/38$ of the training data. Its performance can be further improved with majority voting. We further find that scaling up instructions and responses benefits our implicit PRM, and the latter brings a larger gain. Particularly, we find that our implicit PRM, when instantiated with the cross-entropy (CE) loss, is more data-efficient and can keep improving generation models even when trained with only one response per instruction, the setup that suffers from extreme data scarcity and imbalance. Further, instructions should be relevant to downstream tasks while the diversity of responses does not bring gains. Surprisingly, training on extra Math-Shepherd step labels brings no further improvements to our implicit PRM trained on only outcome data. We hope that our work will encourage a rethinking of PRM training approaches and contribute to making training PRMs more accessible.
Zero-Shot Generalization during Instruction Tuning: Insights from Similarity and Granularity
Jun 17, 2024



Understanding alignment techniques begins with comprehending zero-shot generalization brought by instruction tuning, but little of the mechanism has been understood. Existing work has largely been confined to the task level, without considering that tasks are artificially defined and, to LLMs, merely consist of tokens and representations. This line of research has been limited to examining transfer between tasks from a task-pair perspective, with few studies focusing on understanding zero-shot generalization from the perspective of the data itself. To bridge this gap, we first demonstrate through multiple metrics that zero-shot generalization during instruction tuning happens very early. Next, we investigate the facilitation of zero-shot generalization from both data similarity and granularity perspectives, confirming that encountering highly similar and fine-grained training data earlier during instruction tuning, without the constraints of defined "tasks", enables better generalization. Finally, we propose a more grounded training data arrangement method, Test-centric Multi-turn Arrangement, and show its effectiveness in promoting continual learning and further loss reduction. For the first time, we show that zero-shot generalization during instruction tuning is a form of similarity-based generalization between training and test data at the instance level. We hope our analysis will advance the understanding of zero-shot generalization during instruction tuning and contribute to the development of more aligned LLMs. Our code is released at https://github.com/HBX-hbx/dynamics_of_zero-shot_generalization.
Advancing LLM Reasoning Generalists with Preference Trees
Apr 02, 2024



We introduce Eurus, a suite of large language models (LLMs) optimized for reasoning. Finetuned from Mistral-7B and CodeLlama-70B, Eurus models achieve state-of-the-art results among open-source models on a diverse set of benchmarks covering mathematics, code generation, and logical reasoning problems. Notably, Eurus-70B beats GPT-3.5 Turbo in reasoning through a comprehensive benchmarking across 12 tests covering five tasks, and achieves a 33.3% pass@1 accuracy on LeetCode and 32.6% on TheoremQA, two challenging benchmarks, substantially outperforming existing open-source models by margins more than 13.3%. The strong performance of Eurus can be primarily attributed to UltraInteract, our newly-curated large-scale, high-quality alignment dataset specifically designed for complex reasoning tasks. UltraInteract can be used in both supervised fine-tuning and preference learning. For each instruction, it includes a preference tree consisting of (1) reasoning chains with diverse planning strategies in a unified format, (2) multi-turn interaction trajectories with the environment and the critique, and (3) pairwise data to facilitate preference learning. UltraInteract allows us to conduct an in-depth exploration of preference learning for reasoning tasks. Our investigation reveals that some well-established preference learning algorithms may be less suitable for reasoning tasks compared to their effectiveness in general conversations. Inspired by this, we derive a novel reward modeling objective which, together with UltraInteract, leads to a strong reward model.