 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThrough the PRISM: Principle-Aware, Interpretable, and Multi-Scale Evaluation of Visual Designs
May 30, 2026Effective visual communication stems from the harmony of multiple design principles, such as readability, contrast, alignment, overlap, and coherence, which collectively govern clarity and intent of the communicator. While human designers reason holistically over these principles, machine agents typically condense them into a single heuristic score, offering limited interpretability and diagnostic precision. To address this gap, we introduce PRISM (PRinciple-aware, Interpretable, and Structure-guided Design Modifications), a benchmark that systematically perturbs professional layouts from the Crello dataset along measurable design principles. The benchmark comprises 100K perturbed training samples and 10K perturbed validation designs, each isolating a specific principle violation for controlled analysis of multimodal reasoning about design quality. We show that models like Qwen-2.5-VL and GPT-4o-mini are largely insensitive to targeted principle degradations, whereas GPT-4o exhibits global awareness without fine-grained disentanglement. Building on these insights, we propose a multi-scale evaluation framework that integrates lightweight scorers for quantitative assessment, instruction-tuned vision-language models for localised feedback, and prompt-based methods for global reasoning. Our framework provides interpretable explanations of design failures. Using these localised insights, we show targeted refinements that improve layout quality. Together, PRISM and our framework lay the foundation for interpretable design-literate multimodal reasoning systems.
Do LLM Decoders Listen Fairly? Benchmarking How Language Model Priors Shape Bias in Speech Recognition
Apr 23, 2026As pretrained large language models replace task-specific decoders in speech recognition, a critical question arises: do their text-derived priors make recognition fairer or more biased across demographic groups? We evaluate nine models spanning three architectural generations (CTC with no language model, encoder-decoder with an implicit LM, and LLM-based with an explicit pretrained decoder) on about 43,000 utterances across five demographic axes (ethnicity, accent, gender, age, first language) using Common Voice 24 and Meta's Fair-Speech, a controlled-prompt dataset that eliminates vocabulary confounds. On clean audio, three findings challenge assumptions: LLM decoders do not amplify racial bias (Granite-8B has the best ethnicity fairness, max/min WER = 2.28); Whisper exhibits pathological hallucination on Indian-accented speech with a non-monotonic insertion-rate spike to 9.62% at large-v3; and audio compression predicts accent fairness more than LLM scale. We then stress-test these findings under 12 acoustic degradation conditions (noise, reverberation, silence injection, chunk masking) across both datasets, totaling 216 inference runs. Severe degradation paradoxically compresses fairness gaps as all groups converge to high WER, but silence injection amplifies Whisper's accent bias up to 4.64x by triggering demographic-selective hallucination. Under masking, Whisper enters catastrophic repetition loops (86% of 51,797 insertions) while explicit-LLM decoders produce 38x fewer insertions with near-zero repetition; high-compression audio encoding (Q-former) reintroduces repetition pathology even in LLM decoders. These results suggest that audio encoder design, not LLM scaling, is the primary lever for equitable and robust speech recognition.
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers
Apr 09, 2026We study implicit reasoning, i.e. the ability to combine knowledge or rules within a single forward pass. While transformer-based large language models store substantial factual knowledge and rules, they often fail to compose this knowledge for implicit multi-hop reasoning, suggesting a lack of compositional generalization over their parametric knowledge. To address this limitation, we study recurrent-depth transformers, which enables iterative computation over the same transformer layers. We investigate two compositional generalization challenges under the implicit reasoning scenario: systematic generalization, i.e. combining knowledge that is never used for compositions during training, and depth extrapolation, i.e. generalizing from limited reasoning depth (e.g. training on up to 5-hop) to deeper compositions (e.g. 10-hop). Through controlled studies with models trained from scratch, we show that while vanilla transformers struggle with both generalization challenges, recurrent-depth transformers can effectively make such generalization. For systematic generalization, we find that this ability emerges through a three-stage grokking process, transitioning from memorization to in-distribution generalization and finally to systematic generalization, supported by mechanistic analysis. For depth extrapolation, we show that generalization beyond training depth can be unlocked by scaling inference-time recurrence, with more iterations enabling deeper reasoning. We further study how training strategies affect extrapolation, providing guidance on training recurrent-depth transformers, and identify a key limitation, overthinking, where excessive recurrence degrades predictions and limits generalization to very deep compositions.
Benchmarking Long Roll-outs of Auto-regressive Neural Operators for the Compressible Navier-Stokes Equations with Conserved Quantity Correction
Jan 30, 2026Deep learning has been proposed as an efficient alternative for the numerical approximation of PDE solutions, offering fast, iterative simulation of PDEs through the approximation of solution operators. However, deep learning solutions have struggle to perform well over long prediction durations due to the accumulation of auto-regressive error, which is compounded by the inability of models to conserve physical quantities. In this work, we present conserved quantity correction, a model-agnostic technique for incorporation physical conservation criteria within deep learning models. Our results demonstrate consistent improvement in the long-term stability of auto-regressive neural operator models, regardless of the model architecture. Furthermore, we analyze the performance of neural operators from the spectral domain, highlighting significant limitations of present architectures. These results highlight the need for future work to consider architectures that place specific emphasis on high frequency components, which are integral to the understanding and modeling of turbulent flows.
DiffER: Categorical Diffusion for Chemical Retrosynthesis
May 29, 2025Methods for automatic chemical retrosynthesis have found recent success through the application of models traditionally built for natural language processing, primarily through transformer neural networks. These models have demonstrated significant ability to translate between the SMILES encodings of chemical products and reactants, but are constrained as a result of their autoregressive nature. We propose DiffER, an alternative template-free method for retrosynthesis prediction in the form of categorical diffusion, which allows the entire output SMILES sequence to be predicted in unison. We construct an ensemble of diffusion models which achieves state-of-the-art performance for top-1 accuracy and competitive performance for top-3, top-5, and top-10 accuracy among template-free methods. We prove that DiffER is a strong baseline for a new class of template-free model, capable of learning a variety of synthetic techniques used in laboratory settings and outperforming a variety of other template-free methods on top-k accuracy metrics. By constructing an ensemble of categorical diffusion models with a novel length prediction component with variance, our method is able to approximately sample from the posterior distribution of reactants, producing results with strong metrics of confidence and likelihood. Furthermore, our analyses demonstrate that accurate prediction of the SMILES sequence length is key to further boosting the performance of categorical diffusion models.
A Generic Framework for Conformal Fairness
May 22, 2025



Conformal Prediction (CP) is a popular method for uncertainty quantification with machine learning models. While conformal prediction provides probabilistic guarantees regarding the coverage of the true label, these guarantees are agnostic to the presence of sensitive attributes within the dataset. In this work, we formalize \textit{Conformal Fairness}, a notion of fairness using conformal predictors, and provide a theoretically well-founded algorithm and associated framework to control for the gaps in coverage between different sensitive groups. Our framework leverages the exchangeability assumption (implicit to CP) rather than the typical IID assumption, allowing us to apply the notion of Conformal Fairness to data types and tasks that are not IID, such as graph data. Experiments were conducted on graph and tabular datasets to demonstrate that the algorithm can control fairness-related gaps in addition to coverage aligned with theoretical expectations.
Ranking Free RAG: Replacing Re-ranking with Selection in RAG for Sensitive Domains
May 21, 2025Traditional Retrieval-Augmented Generation (RAG) pipelines rely on similarity-based retrieval and re-ranking, which depend on heuristics such as top-k, and lack explainability, interpretability, and robustness against adversarial content. To address this gap, we propose a novel method METEORA that replaces re-ranking in RAG with a rationale-driven selection approach. METEORA operates in two stages. First, a general-purpose LLM is preference-tuned to generate rationales conditioned on the input query using direct preference optimization. These rationales guide the evidence chunk selection engine, which selects relevant chunks in three stages: pairing individual rationales with corresponding retrieved chunks for local relevance, global selection with elbow detection for adaptive cutoff, and context expansion via neighboring chunks. This process eliminates the need for top-k heuristics. The rationales are also used for consistency check using a Verifier LLM to detect and filter poisoned or misleading content for safe generation. The framework provides explainable and interpretable evidence flow by using rationales consistently across both selection and verification. Our evaluation across six datasets spanning legal, financial, and academic research domains shows that METEORA improves generation accuracy by 33.34% while using approximately 50% fewer chunks than state-of-the-art re-ranking methods. In adversarial settings, METEORA significantly improves the F1 score from 0.10 to 0.44 over the state-of-the-art perplexity-based defense baseline, demonstrating strong resilience to poisoning attacks. Code available at: https://anonymous.4open.science/r/METEORA-DC46/README.md
From Guessing to Asking: An Approach to Resolving the Persona Knowledge Gap in LLMs during Multi-Turn Conversations
Mar 16, 2025In multi-turn dialogues, large language models (LLM) face a critical challenge of ensuring coherence while adapting to user-specific information. This study introduces the persona knowledge gap, the discrepancy between a model's internal understanding and the knowledge required for coherent, personalized conversations. While prior research has recognized these gaps, computational methods for their identification and resolution remain underexplored. We propose Conversation Preference Elicitation and Recommendation (CPER), a novel framework that dynamically detects and resolves persona knowledge gaps using intrinsic uncertainty quantification and feedback-driven refinement. CPER consists of three key modules: a Contextual Understanding Module for preference extraction, a Dynamic Feedback Module for measuring uncertainty and refining persona alignment, and a Persona-Driven Response Generation module for adapting responses based on accumulated user context. We evaluate CPER on two real-world datasets: CCPE-M for preferential movie recommendations and ESConv for mental health support. Using A/B testing, human evaluators preferred CPER's responses 42% more often than baseline models in CCPE-M and 27% more often in ESConv. A qualitative human evaluation confirms that CPER's responses are preferred for maintaining contextual relevance and coherence, particularly in longer (12+ turn) conversations.
Graph Sparsification for Enhanced Conformal Prediction in Graph Neural Networks
Oct 28, 2024



Conformal Prediction is a robust framework that ensures reliable coverage across machine learning tasks. Although recent studies have applied conformal prediction to graph neural networks, they have largely emphasized post-hoc prediction set generation. Improving conformal prediction during the training stage remains unaddressed. In this work, we tackle this challenge from a denoising perspective by introducing SparGCP, which incorporates graph sparsification and a conformal prediction-specific objective into GNN training. SparGCP employs a parameterized graph sparsification module to filter out task-irrelevant edges, thereby improving conformal prediction efficiency. Extensive experiments on real-world graph datasets demonstrate that SparGCP outperforms existing methods, reducing prediction set sizes by an average of 32\% and scaling seamlessly to large networks on commodity GPUs.
Benchmarking Graph Conformal Prediction: Empirical Analysis, Scalability, and Theoretical Insights
Sep 26, 2024

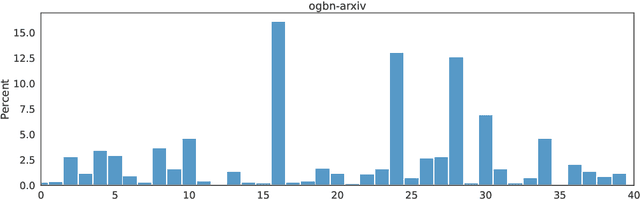

Conformal prediction has become increasingly popular for quantifying the uncertainty associated with machine learning models. Recent work in graph uncertainty quantification has built upon this approach for conformal graph prediction. The nascent nature of these explorations has led to conflicting choices for implementations, baselines, and method evaluation. In this work, we analyze the design choices made in the literature and discuss the tradeoffs associated with existing methods. Building on the existing implementations for existing methods, we introduce techniques to scale existing methods to large-scale graph datasets without sacrificing performance. Our theoretical and empirical results justify our recommendations for future scholarship in graph conformal prediction.