 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-modal Agentic Co-pilot for Evidence Grounded Computational Pathology
Jun 06, 2026Pathology is the cornerstone of modern medicine, where accurate decision-making relies heavily on evidence-based practices. While artificial intelligence (AI) has the potential to transform clinical workflows, the intersection of AI and evidence-based medicine remains under-explored, with primitive attempts restricted to text-only general medicine. In this work, we present PathPocket, a multimodal AI agentic co-pilot designed specifically for evidence grounded pathology. We construct the most comprehensive pathology evidence corpus to date, encompassing approximately 110,472 public and authorized documents structured across a rigorous hierarchy of evidence from clinical guideline to expert opinion. From this meticulously graded foundation, we build a large-scale multimodal pathology hypergraph containing over 4.55 million entities and 7.10 million relations. Serving as a robust knowledge engine, this hypergraph provides traceable evidence for a collaborative multi-agent reasoning framework integrating input understanding, evidence retrieval, filtering, and diagnosis generation. This enables PathPocket to seamlessly resolve a wide spectrum of clinical tasks, ranging from text-only queries to complex multimodal diagnostics involving region-of-interest (ROI) and gigapixel whole-slide images (WSIs). We rigorously evaluate the system on a multidimensional benchmark of over 200,000 real-world cases, where it significantly outperforms existing state-of-the-arts. Crucially, extensive user studies demonstrate that PathPocket substantially improves the diagnostic accuracy and confidence of pathologists. By directly grounding pathology interpretations in verifiable literature, PathPocket offers a practical and scalable solution for the future of evidence grounded computational pathology.
A Pathology Foundation Model for Gastric Cancer with Real-World Validation
Jun 03, 2026Gastric cancer remains a major cause of cancer mortality, yet its histological and molecular heterogeneity complicates diagnosis and risk stratification. General-purpose pathology foundation models (PFMs) often plateau on fine-grained endpoints central to gastric cancer care, and few have undergone rigorous prospective validation or clinical reader studies. We present GRACE, a Gastric-specific foundation model for Real-world Assessment and Clinical dEcision support. GRACE was developed from multicenter gastric pathology datasets totaling 48,364 primarily HE-stained whole-slide images from 37,493 patients. When evaluated on 28 clinically relevant tasks, GRACE consistently outperformed representative pancancer PFMs, achieving a macro-AUC of 0.9188, with strong performance for precancerous lesion diagnosis (macro-AUC 0.9322), tumor histopathological assessment (macro-AUC 0.9119), molecular profiling (macro-AUC 0.8682), and prognostic prediction. Beyond benchmarking, GRACE's translational value was substantiated through a rigorous evidence chain. Under safety-gated criteria requiring 100% NPV for rule-out and 100% PPV for rule-in, GRACE streamlined review for up to 69.6% of malignancy-diagnosis cases and triaged 46.8% of MMR-IHC follow-up requests. This translational feasibility was further strengthened by a randomized crossover reader study of pathologist-AI collaboration. With GRACE assistance, diagnostic accuracy improved from 82.0% to 89.9%, yielding nearly twofold higher adjusted odds of a correct diagnosis (OR 1.987) alongside concurrent gains in sensitivity and specificity. AI assistance also reduced diagnostic time by 14.9%, elevated diagnostic confidence by 9.0%, and markedly improved inter-rater agreement. When calibrated to maintain non-inferior performance to senior pathologists, the AI-assisted workflow could triage 60.7% of atrophy and 82.7% of intestinal metaplasia cases.
Spatial Transcriptomics-Guided Alignment Enhances Molecular Profiling in Pathology Foundation Model
May 29, 2026Comprehensive molecular profiling is essential for modern precision oncology but remains hindered by prohibitive costs, specimen exhaustion, and protracted turnaround times. While pathology foundation models (PFMs) have demonstrated potential for inferring molecular phenotypes from routine hematoxylin and eosin (H&E) whole-slide images (WSIs), current architectures primarily rely on vision-centric self-supervised learning or vision-language alignment, lacking the spatially resolved molecular supervision required to connect subtle morphological features with underlying genomic alterations. Spatial transcriptomics (ST) emerges as a transformative technology that enables transcriptomic quantification within intact tissue sections, thereby preserving the precise spatial link between histology and molecular profiles. In this study, we present a Spatial Transcriptomics-guided Alignment framework for Molecular Profiling (STAMP), which endows PFMs with intrinsic molecular awareness. To support this paradigm, we curated HumanST-1k, a human ST dataset spanning diverse anatomical organs and sequencing platforms. This atlas yields 1.8 million pairs of H&E patches and corresponding transcriptomic profiles, providing a corpus that links histological structures with their molecular states. To mitigate the technical noise inherent to raw transcriptomics, STAMP applies a pathway-informed alignment strategy that aggregates transcriptomic data into biologically functional pathways, which are subsequently integrated into PFMs via parameter-efficient fine-tuning. This alignment enriches the representation space of PFMs and unlocks their capacity to resolve sub-visual molecular signatures. The clinical utility of these augmented representations was validated through a multi-tier evaluation framework.
PR2: Predictive Routing Replay for MoE-Based LLM Reinforcement Learning
May 29, 2026Mixture of Experts (MoE) Large Language Models (LLMs) achieve strong performance at scale. However, reinforcement learning (RL) on MoE-based LLMs often suffers from training instability. A root cause is router drift, i.e., expert activations can change drastically across model updates and differ between disaggregated rollout and training phases, causing large rollout--training mismatch and unstable importance sampling weights in PPO-style RL algorithms. Routing replay mitigates this issue by freezing the replay route within each reasoning trajectory, but it ignores how the router evolves under off-policy updates and thus causes router staleness. To address this limitation, we propose Predictive Routing Replay (PR2), which augments each router with a lightweight evolution predictor that learns to anticipate short-horizon router evolution. During the rollout phase, we use the predictive routing distribution to apply top-$k$ routing, enabling gradients to reach experts that are likely to become active after updates. During the training phase, we replay the resulting predicted route to retain consistency for stable importance estimation. Theoretical analysis and experiments support that PR2 reduces routing-induced mismatch, improves RL stability, and yields stronger performance across various reasoning benchmarks.
Convergence of Spectral Principal Paths: How Deep Networks Distill Linear Representations from Noisy Inputs
Jun 10, 2025



High-level representations have become a central focus in enhancing AI transparency and control, shifting attention from individual neurons or circuits to structured semantic directions that align with human-interpretable concepts. Motivated by the Linear Representation Hypothesis (LRH), we propose the Input-Space Linearity Hypothesis (ISLH), which posits that concept-aligned directions originate in the input space and are selectively amplified with increasing depth. We then introduce the Spectral Principal Path (SPP) framework, which formalizes how deep networks progressively distill linear representations along a small set of dominant spectral directions. Building on this framework, we further demonstrate the multimodal robustness of these representations in Vision-Language Models (VLMs). By bridging theoretical insights with empirical validation, this work advances a structured theory of representation formation in deep networks, paving the way for improving AI robustness, fairness, and transparency.
From EduVisBench to EduVisAgent: A Benchmark and Multi-Agent Framework for Pedagogical Visualization
May 22, 2025
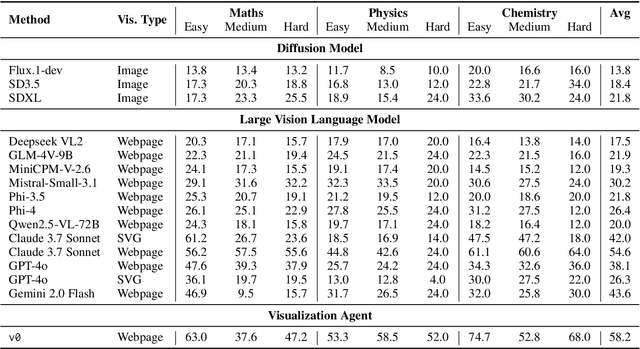
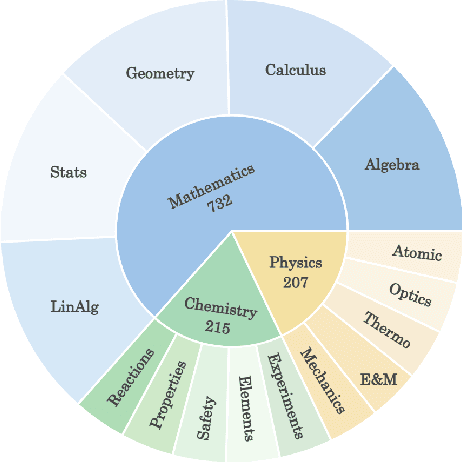
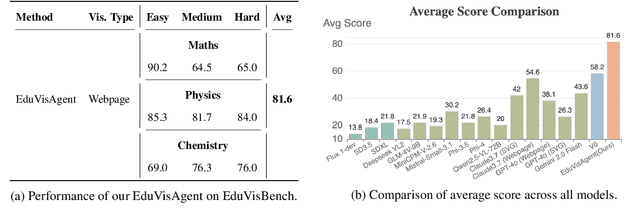
While foundation models (FMs), such as diffusion models and large vision-language models (LVLMs), have been widely applied in educational contexts, their ability to generate pedagogically effective visual explanations remains limited. Most existing approaches focus primarily on textual reasoning, overlooking the critical role of structured and interpretable visualizations in supporting conceptual understanding. To better assess the visual reasoning capabilities of FMs in educational settings, we introduce EduVisBench, a multi-domain, multi-level benchmark. EduVisBench features diverse STEM problem sets requiring visually grounded solutions, along with a fine-grained evaluation rubric informed by pedagogical theory. Our empirical analysis reveals that existing models frequently struggle with the inherent challenge of decomposing complex reasoning and translating it into visual representations aligned with human cognitive processes. To address these limitations, we propose EduVisAgent, a multi-agent collaborative framework that coordinates specialized agents for instructional planning, reasoning decomposition, metacognitive prompting, and visualization design. Experimental results show that EduVisAgent substantially outperforms all baselines, achieving a 40.2% improvement and delivering more educationally aligned visualizations. EduVisBench and EduVisAgent are available at https://github.com/aiming-lab/EduVisBench and https://github.com/aiming-lab/EduVisAgent.
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
Token Level Routing Inference System for Edge Devices
Apr 10, 2025



The computational complexity of large language model (LLM) inference significantly constrains their deployment efficiency on edge devices. In contrast, small language models offer faster decoding and lower resource consumption but often suffer from degraded response quality and heightened susceptibility to hallucinations. To address this trade-off, collaborative decoding, in which a large model assists in generating critical tokens, has emerged as a promising solution. This paradigm leverages the strengths of both model types by enabling high-quality inference through selective intervention of the large model, while maintaining the speed and efficiency of the smaller model. In this work, we present a novel collaborative decoding inference system that allows small models to perform on-device inference while selectively consulting a cloud-based large model for critical token generation. Remarkably, the system achieves a 60% performance gain on CommonsenseQA using only a 0.5B model on an M1 MacBook, with under 7% of tokens generation uploaded to the large model in the cloud.
CITER: Collaborative Inference for Efficient Large Language Model Decoding with Token-Level Routing
Feb 04, 2025



Large language models have achieved remarkable success in various tasks but suffer from high computational costs during inference, limiting their deployment in resource-constrained applications. To address this issue, we propose a novel CITER (\textbf{C}ollaborative \textbf{I}nference with \textbf{T}oken-l\textbf{E}vel \textbf{R}outing) framework that enables efficient collaboration between small and large language models (SLMs & LLMs) through a token-level routing strategy. Specifically, CITER routes non-critical tokens to an SLM for efficiency and routes critical tokens to an LLM for generalization quality. We formulate router training as a policy optimization, where the router receives rewards based on both the quality of predictions and the inference costs of generation. This allows the router to learn to predict token-level routing scores and make routing decisions based on both the current token and the future impact of its decisions. To further accelerate the reward evaluation process, we introduce a shortcut which significantly reduces the costs of the reward estimation and improving the practicality of our approach. Extensive experiments on five benchmark datasets demonstrate that CITER reduces the inference costs while preserving high-quality generation, offering a promising solution for real-time and resource-constrained applications.
LLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.