 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Evaluation of Text-To-Image Models
Nov 07, 2023



The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at https://crfm.stanford.edu/heim/v1.1.0 and the code at https://github.com/stanford-crfm/helm, which is integrated with the HELM codebase.
MGit: A Model Versioning and Management System
Jul 14, 2023Models derived from other models are extremely common in machine learning (ML) today. For example, transfer learning is used to create task-specific models from "pre-trained" models through finetuning. This has led to an ecosystem where models are related to each other, sharing structure and often even parameter values. However, it is hard to manage these model derivatives: the storage overhead of storing all derived models quickly becomes onerous, prompting users to get rid of intermediate models that might be useful for further analysis. Additionally, undesired behaviors in models are hard to track down (e.g., is a bug inherited from an upstream model?). In this paper, we propose a model versioning and management system called MGit that makes it easier to store, test, update, and collaborate on model derivatives. MGit introduces a lineage graph that records provenance and versioning information between models, optimizations to efficiently store model parameters, as well as abstractions over this lineage graph that facilitate relevant testing, updating and collaboration functionality. MGit is able to reduce the lineage graph's storage footprint by up to 7x and automatically update downstream models in response to updates to upstream models.
Cheaply Evaluating Inference Efficiency Metrics for Autoregressive Transformer APIs
May 03, 2023Large language models (LLMs) power many state-of-the-art systems in natural language processing. However, these models are extremely computationally expensive, even at inference time, raising the natural question: when is the extra cost of deploying a larger model worth the anticipated boost in capabilities? Better understanding this tradeoff fundamentally could benefit from an inference efficiency metric that is both (i) easily comparable across models from different providers, and (ii) representative of the true cost of running queries in an isolated performance environment. Unfortunately, access to LLMs today is largely restricted to black-box text generation APIs and raw runtimes measured through this interface do not satisfy these desiderata: model providers can apply various software and hardware optimizations orthogonal to the model, and models served on shared infrastructure are susceptible to performance contention. To circumvent these problems, we propose a new metric for comparing inference efficiency across models. This metric puts models on equal footing as though they were served (i) on uniform hardware and software, and (ii) without performance contention. We call this metric the \emph{idealized runtime}, and we propose a methodology to efficiently estimate this metric for autoregressive Transformer models. We also propose cost-aware variants that incorporate the number of accelerators needed to serve the model. Using these metrics, we compare ten state-of-the-art LLMs to provide the first analysis of inference efficiency-capability tradeoffs; we make several observations from this analysis, including the fact that the superior inference runtime performance of certain APIs is often a byproduct of optimizations within the API rather than the underlying model. Our methodology also facilitates the efficient comparison of different software and hardware stacks.
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
Nov 29, 2022



We present MegaBlocks, a system for efficient Mixture-of-Experts (MoE) training on GPUs. Our system is motivated by the limitations of current frameworks, which restrict the dynamic routing in MoE layers to satisfy the constraints of existing software and hardware. These formulations force a tradeoff between model quality and hardware efficiency, as users must choose between dropping tokens from the computation or wasting computation and memory on padding. To address these limitations, we reformulate MoE computation in terms of block-sparse operations and develop new block-sparse GPU kernels that efficiently handle the dynamism present in MoEs. Our approach never drops tokens and maps efficiently to modern hardware, enabling end-to-end training speedups of up to 40% over MoEs trained with the state-of-the-art Tutel library and 2.4x over DNNs trained with the highly-optimized Megatron-LM framework.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Efficient Large-Scale Language Model Training on GPU Clusters
Apr 09, 2021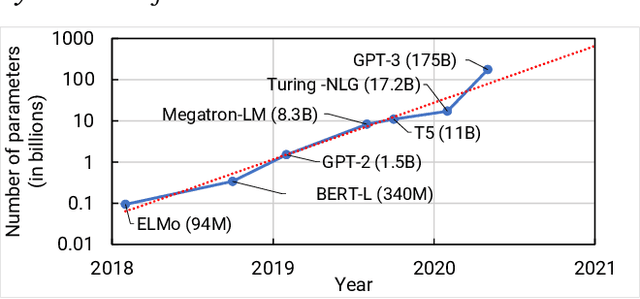
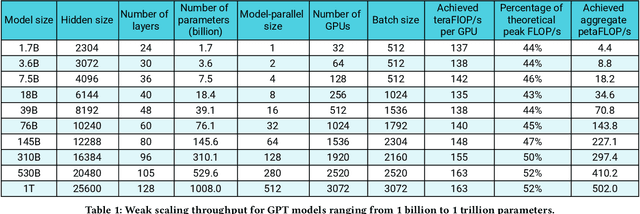
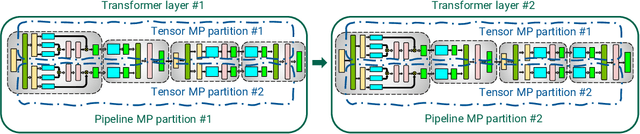
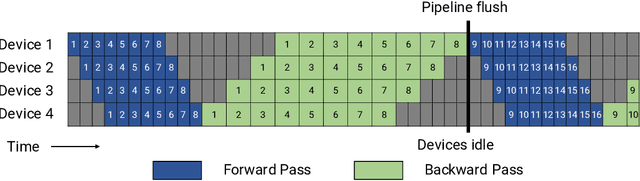
Large language models have led to state-of-the-art accuracies across a range of tasks. However, training these large models efficiently is challenging for two reasons: a) GPU memory capacity is limited, making it impossible to fit large models on a single GPU or even on a multi-GPU server; and b) the number of compute operations required to train these models can result in unrealistically long training times. New methods of model parallelism such as tensor and pipeline parallelism have been proposed to address these challenges; unfortunately, naive usage leads to fundamental scaling issues at thousands of GPUs due to various reasons, e.g., expensive cross-node communication or idle periods waiting on other devices. In this work, we show how to compose different types of parallelism methods (tensor, pipeline, and data paralleism) to scale to thousands of GPUs, achieving a two-order-of-magnitude increase in the sizes of models we can efficiently train compared to existing systems. We discuss various implementations of pipeline parallelism and propose a novel schedule that can improve throughput by more than 10% with comparable memory footprint compared to previously-proposed approaches. We quantitatively study the trade-offs between tensor, pipeline, and data parallelism, and provide intuition as to how to configure distributed training of a large model. The composition of these techniques allows us to perform training iterations on a model with 1 trillion parameters at 502 petaFLOP/s on 3072 GPUs with achieved per-GPU throughput of 52% of peak; previous efforts to train similar-sized models achieve much lower throughput (36% of theoretical peak). Our code has been open-sourced at https://github.com/nvidia/megatron-lm.
Memory-Efficient Pipeline-Parallel DNN Training
Jun 16, 2020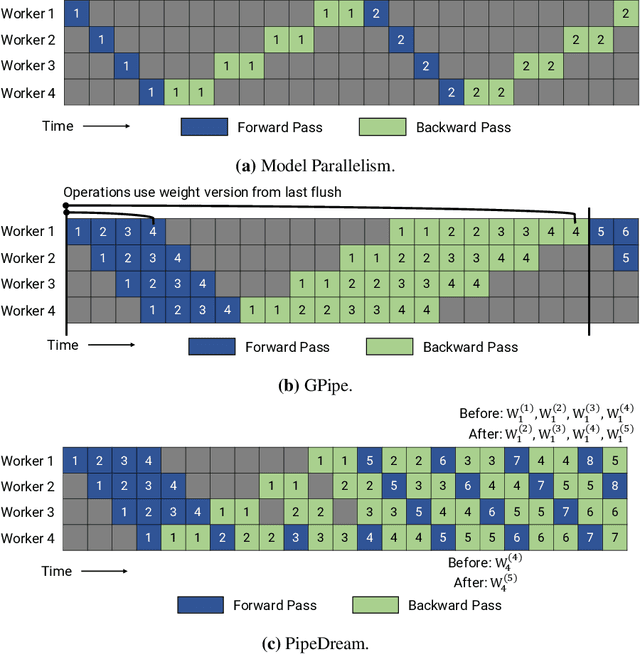
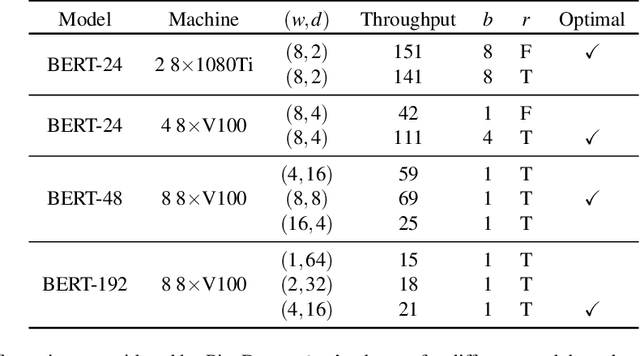
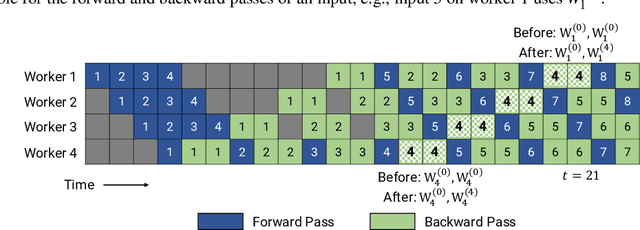
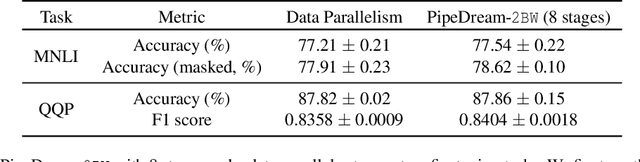
Many state-of-the-art results in domains such as NLP and computer vision have been obtained by scaling up the number of parameters in existing models. However, the weight parameters and intermediate outputs of these large models often do not fit in the main memory of a single accelerator device; this means that it is necessary to use multiple accelerators to train large models, which is challenging to do in a time-efficient way. In this work, we propose PipeDream-2BW, a system that performs memory-efficient pipeline parallelism, a hybrid form of parallelism that combines data and model parallelism with input pipelining. Our system uses a novel pipelining and weight gradient coalescing strategy, combined with the double buffering of weights, to ensure high throughput, low memory footprint, and weight update semantics similar to data parallelism. In addition, PipeDream-2BW automatically partitions the model over the available hardware resources, while being cognizant of constraints such as compute capabilities, memory capacities, and interconnect topologies, and determines when to employ existing memory-savings techniques, such as activation recomputation, that trade off extra computation for lower memory footprint. PipeDream-2BW is able to accelerate the training of large language models with up to 2.5 billion parameters by up to 6.9x compared to optimized baselines.
MLPerf Training Benchmark
Oct 30, 2019
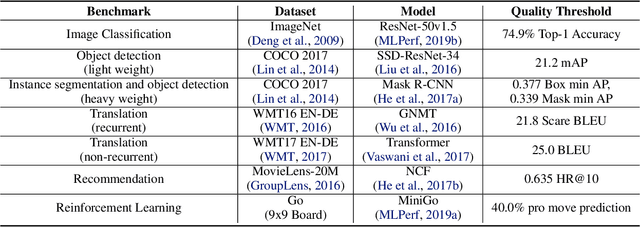
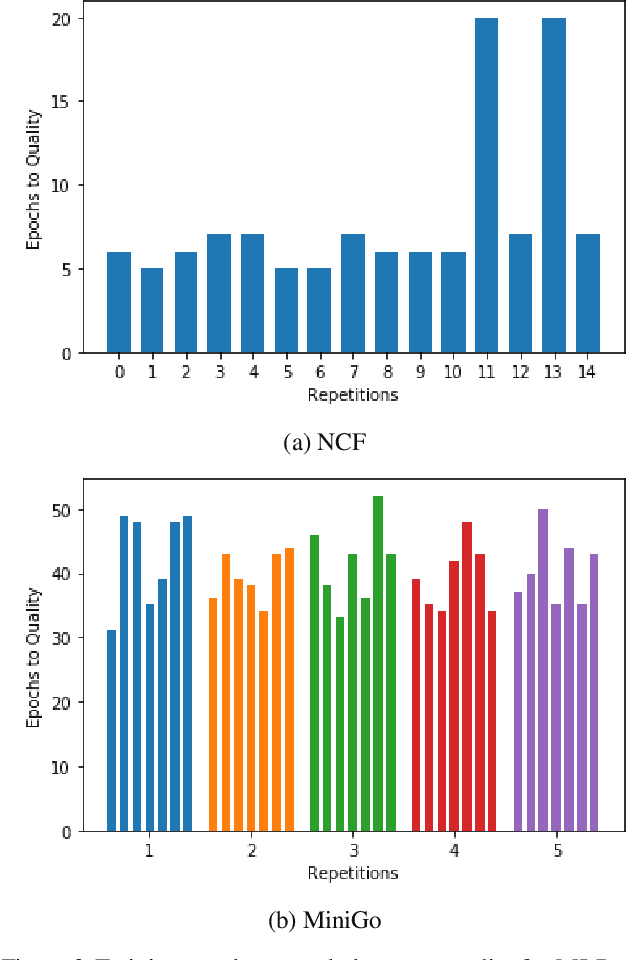
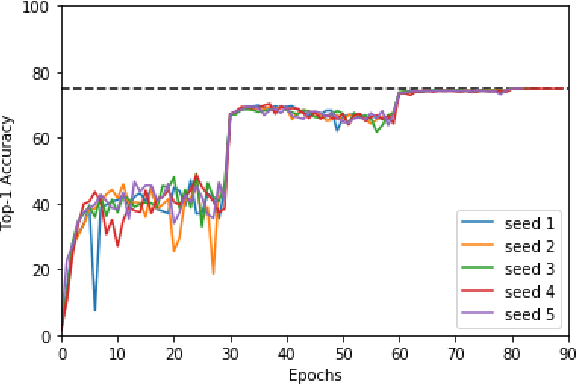
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.