 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScorch: A Library for Sparse Deep Learning
May 27, 2024



The rapid growth in the size of deep learning models strains the capabilities of traditional dense computation paradigms. Leveraging sparse computation has become increasingly popular for training and deploying large-scale models, but existing deep learning frameworks lack extensive support for sparse operations. To bridge this gap, we introduce Scorch, a library that seamlessly integrates efficient sparse tensor computation into the PyTorch ecosystem, with an initial focus on inference workloads on CPUs. Scorch provides a flexible and intuitive interface for sparse tensors, supporting diverse sparse data structures. Scorch introduces a compiler stack that automates key optimizations, including automatic loop ordering, tiling, and format inference. Combined with a runtime that adapts its execution to both dense and sparse data, Scorch delivers substantial speedups over hand-written PyTorch Sparse (torch.sparse) operations without sacrificing usability. More importantly, Scorch enables efficient computation of complex sparse operations that lack hand-optimized PyTorch implementations. This flexibility is crucial for exploring novel sparse architectures. We demonstrate Scorch's ease of use and performance gains on diverse deep learning models across multiple domains. With only minimal code changes, Scorch achieves 1.05-5.78x speedups over PyTorch Sparse on end-to-end tasks. Scorch's seamless integration and performance gains make it a valuable addition to the PyTorch ecosystem. We believe Scorch will enable wider exploration of sparsity as a tool for scaling deep learning and inform the development of other sparse libraries.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts
Nov 29, 2022



We present MegaBlocks, a system for efficient Mixture-of-Experts (MoE) training on GPUs. Our system is motivated by the limitations of current frameworks, which restrict the dynamic routing in MoE layers to satisfy the constraints of existing software and hardware. These formulations force a tradeoff between model quality and hardware efficiency, as users must choose between dropping tokens from the computation or wasting computation and memory on padding. To address these limitations, we reformulate MoE computation in terms of block-sparse operations and develop new block-sparse GPU kernels that efficiently handle the dynamism present in MoEs. Our approach never drops tokens and maps efficiently to modern hardware, enabling end-to-end training speedups of up to 40% over MoEs trained with the state-of-the-art Tutel library and 2.4x over DNNs trained with the highly-optimized Megatron-LM framework.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Sparse GPU Kernels for Deep Learning
Jun 18, 2020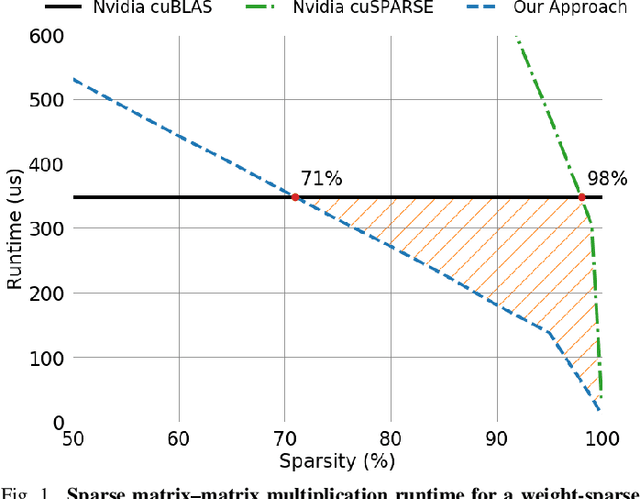
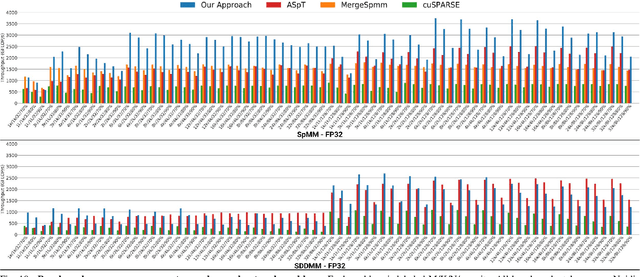
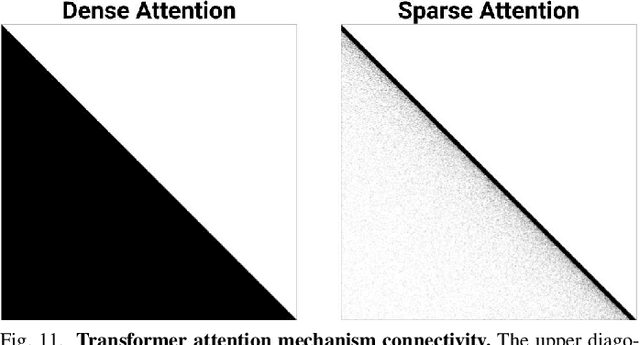
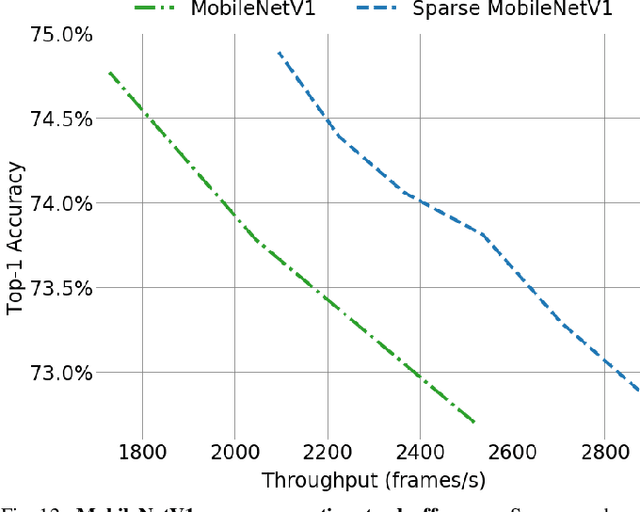
Scientific workloads have traditionally exploited high levels of sparsity to accelerate computation and reduce memory requirements. While deep neural networks can be made sparse, achieving practical speedups on GPUs is difficult because these applications have relatively moderate levels of sparsity that are not sufficient for existing sparse kernels to outperform their dense counterparts. In this work, we study sparse matrices from deep learning applications and identify favorable properties that can be exploited to accelerate computation. Based on these insights, we develop high-performance GPU kernels for two sparse matrix operations widely applicable in neural networks: sparse matrix-dense matrix multiplication and sampled dense-dense matrix multiplication. Our kernels reach 27% of single-precision peak on Nvidia V100 GPUs. Using our kernels, we demonstrate sparse Transformer and MobileNet models that achieve 1.2-2.1x speedups and up to 12.8x memory savings without sacrificing accuracy.
Rigging the Lottery: Making All Tickets Winners
Nov 25, 2019
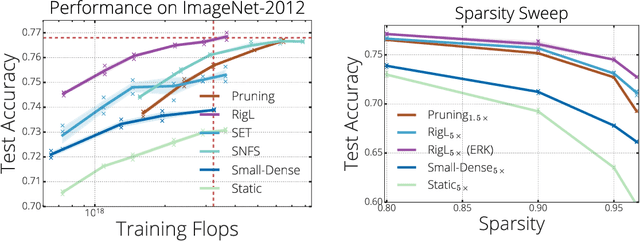
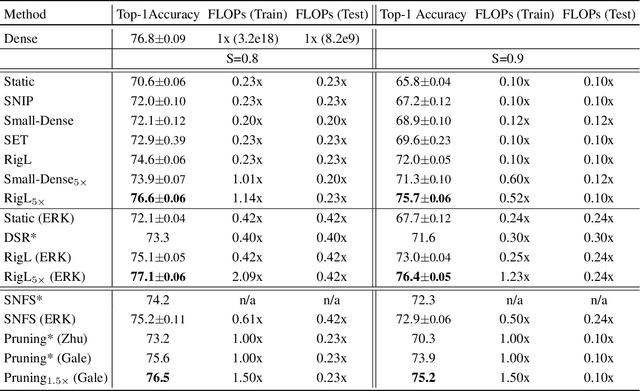
Sparse neural networks have been shown to be more parameter and compute efficient compared to dense networks and in some cases are used to decrease wall clock inference times. There is a large body of work on training dense networks to yield sparse networks for inference. This limits the size of the largest trainable sparse model to that of the largest trainable dense model. In this paper we introduce a method to train sparse neural networks with a fixed parameter count and a fixed computational cost throughout training, without sacrificing accuracy relative to existing dense-to-sparse training methods. Our method updates the topology of the network during training by using parameter magnitudes and infrequent gradient calculations. We show that this approach requires fewer floating-point operations (FLOPs) to achieve a given level of accuracy compared to prior techniques. Importantly, by adjusting the topology it can start from any initialization - not just "lucky" ones. We demonstrate state-of-the-art sparse training results with ResNet-50, MobileNet v1 and MobileNet v2 on the ImageNet-2012 dataset, WideResNets on the CIFAR-10 dataset and RNNs on the WikiText-103 dataset. Finally, we provide some insights into why allowing the topology to change during the optimization can overcome local minima encountered when the topology remains static.
Fast Sparse ConvNets
Nov 21, 2019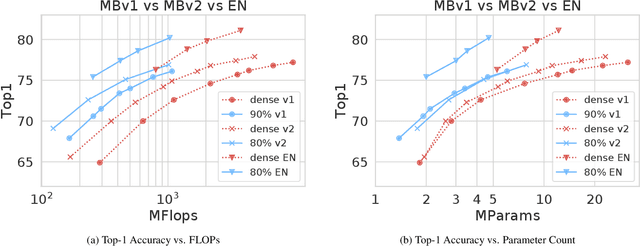
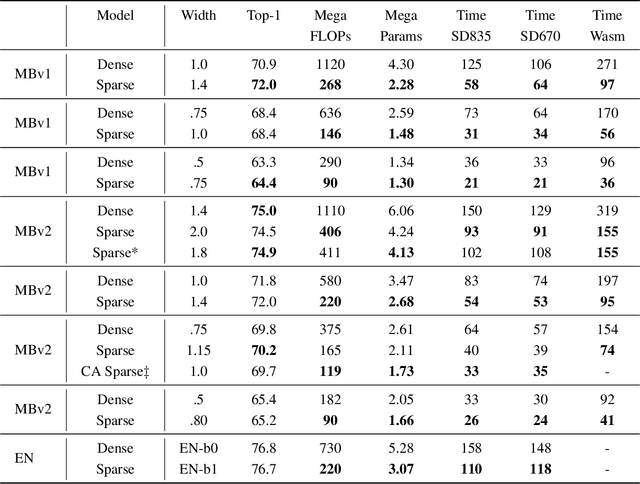

Historically, the pursuit of efficient inference has been one of the driving forces behind research into new deep learning architectures and building blocks. Some recent examples include: the squeeze-and-excitation module, depthwise separable convolutions in Xception, and the inverted bottleneck in MobileNet v2. Notably, in all of these cases, the resulting building blocks enabled not only higher efficiency, but also higher accuracy, and found wide adoption in the field. In this work, we further expand the arsenal of efficient building blocks for neural network architectures; but instead of combining standard primitives (such as convolution), we advocate for the replacement of these dense primitives with their sparse counterparts. While the idea of using sparsity to decrease the parameter count is not new, the conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly, which we open-source for the benefit of the community as part of the XNNPACK library. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet v1, MobileNet v2 and EfficientNet architectures substantially outperform strong dense baselines on the efficiency-accuracy curve. On Snapdragon 835 our sparse networks outperform their dense equivalents by $1.3-2.4\times$ -- equivalent to approximately one entire generation of MobileNet-family improvement. We hope that our findings will facilitate wider adoption of sparsity as a tool for creating efficient and accurate deep learning architectures.
The State of Sparsity in Deep Neural Networks
Feb 25, 2019
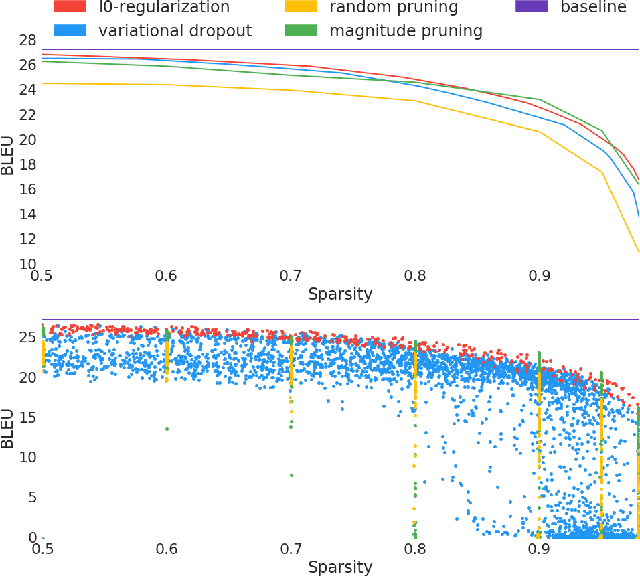
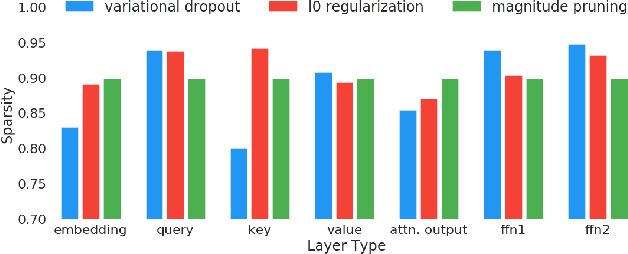
We rigorously evaluate three state-of-the-art techniques for inducing sparsity in deep neural networks on two large-scale learning tasks: Transformer trained on WMT 2014 English-to-German, and ResNet-50 trained on ImageNet. Across thousands of experiments, we demonstrate that complex techniques (Molchanov et al., 2017; Louizos et al., 2017b) shown to yield high compression rates on smaller datasets perform inconsistently, and that simple magnitude pruning approaches achieve comparable or better results. Additionally, we replicate the experiments performed by (Frankle & Carbin, 2018) and (Liu et al., 2018) at scale and show that unstructured sparse architectures learned through pruning cannot be trained from scratch to the same test set performance as a model trained with joint sparsification and optimization. Together, these results highlight the need for large-scale benchmarks in the field of model compression. We open-source our code, top performing model checkpoints, and results of all hyperparameter configurations to establish rigorous baselines for future work on compression and sparsification.
dMath: Distributed Linear Algebra for DL
Nov 19, 2016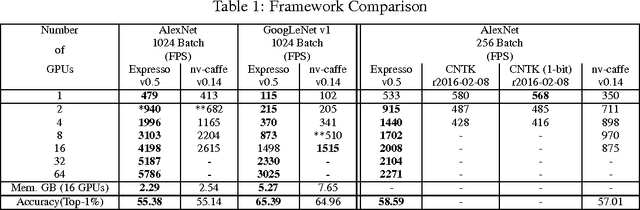
The paper presents a parallel math library, dMath, that demonstrates leading scaling when using intranode, internode, and hybrid-parallelism for deep learning (DL). dMath provides easy-to-use distributed primitives and a variety of domain-specific algorithms including matrix multiplication, convolutions, and others allowing for rapid development of scalable applications like deep neural networks (DNNs). Persistent data stored in GPU memory and advanced memory management techniques avoid costly transfers between host and device. dMath delivers performance, portability, and productivity to its specific domain of support.