 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
ColBERT-serve: Efficient Multi-Stage Memory-Mapped Scoring
Apr 21, 2025We study serving retrieval models, specifically late interaction models like ColBERT, to many concurrent users at once and under a small budget, in which the index may not fit in memory. We present ColBERT-serve, a novel serving system that applies a memory-mapping strategy to the ColBERT index, reducing RAM usage by 90% and permitting its deployment on cheap servers, and incorporates a multi-stage architecture with hybrid scoring, reducing ColBERT's query latency and supporting many concurrent queries in parallel.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
ALTO: An Efficient Network Orchestrator for Compound AI Systems
Mar 07, 2024We present ALTO, a network orchestrator for efficiently serving compound AI systems such as pipelines of language models. ALTO achieves high throughput and low latency by taking advantage of an optimization opportunity specific to generative language models: streaming intermediate outputs. As language models produce outputs token by token, ALTO exposes opportunities to stream intermediate outputs between stages when possible. We highlight two new challenges of correctness and load balancing which emerge when streaming intermediate data across distributed pipeline stage instances. We also motivate the need for an aggregation-aware routing interface and distributed prompt-aware scheduling to address these challenges. We demonstrate the impact of ALTO's partial output streaming on a complex chatbot verification pipeline, increasing throughput by up to 3x for a fixed latency target of 4 seconds / request while also reducing tail latency by 1.8x compared to a baseline serving approach.
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Oct 05, 2023



The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately, existing LM pipelines are typically implemented using hard-coded "prompt templates", i.e. lengthy strings discovered via trial and error. Toward a more systematic approach for developing and optimizing LM pipelines, we introduce DSPy, a programming model that abstracts LM pipelines as text transformation graphs, i.e. imperative computational graphs where LMs are invoked through declarative modules. DSPy modules are parameterized, meaning they can learn (by creating and collecting demonstrations) how to apply compositions of prompting, finetuning, augmentation, and reasoning techniques. We design a compiler that will optimize any DSPy pipeline to maximize a given metric. We conduct two case studies, showing that succinct DSPy programs can express and optimize sophisticated LM pipelines that reason about math word problems, tackle multi-hop retrieval, answer complex questions, and control agent loops. Within minutes of compiling, a few lines of DSPy allow GPT-3.5 and llama2-13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting (generally by over 25% and 65%, respectively) and pipelines with expert-created demonstrations (by up to 5-46% and 16-40%, respectively). On top of that, DSPy programs compiled to open and relatively small LMs like 770M-parameter T5 and llama2-13b-chat are competitive with approaches that rely on expert-written prompt chains for proprietary GPT-3.5. DSPy is available at https://github.com/stanfordnlp/dspy
Cheaply Evaluating Inference Efficiency Metrics for Autoregressive Transformer APIs
May 03, 2023
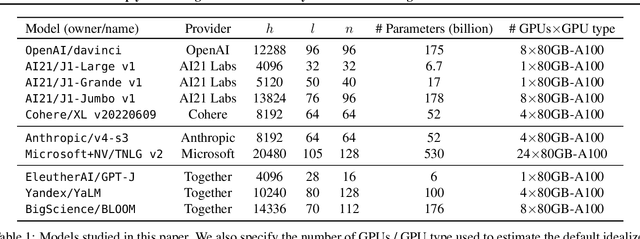
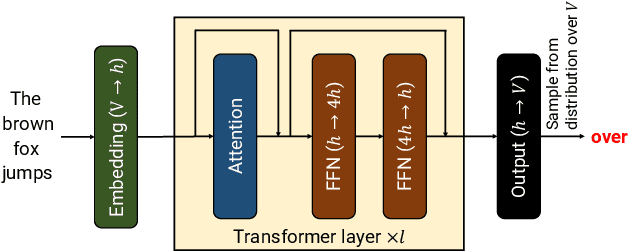

Large language models (LLMs) power many state-of-the-art systems in natural language processing. However, these models are extremely computationally expensive, even at inference time, raising the natural question: when is the extra cost of deploying a larger model worth the anticipated boost in capabilities? Better understanding this tradeoff fundamentally could benefit from an inference efficiency metric that is both (i) easily comparable across models from different providers, and (ii) representative of the true cost of running queries in an isolated performance environment. Unfortunately, access to LLMs today is largely restricted to black-box text generation APIs and raw runtimes measured through this interface do not satisfy these desiderata: model providers can apply various software and hardware optimizations orthogonal to the model, and models served on shared infrastructure are susceptible to performance contention. To circumvent these problems, we propose a new metric for comparing inference efficiency across models. This metric puts models on equal footing as though they were served (i) on uniform hardware and software, and (ii) without performance contention. We call this metric the \emph{idealized runtime}, and we propose a methodology to efficiently estimate this metric for autoregressive Transformer models. We also propose cost-aware variants that incorporate the number of accelerators needed to serve the model. Using these metrics, we compare ten state-of-the-art LLMs to provide the first analysis of inference efficiency-capability tradeoffs; we make several observations from this analysis, including the fact that the superior inference runtime performance of certain APIs is often a byproduct of optimizations within the API rather than the underlying model. Our methodology also facilitates the efficient comparison of different software and hardware stacks.
UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers
Mar 01, 2023



Many information retrieval tasks require large labeled datasets for fine-tuning. However, such datasets are often unavailable, and their utility for real-world applications can diminish quickly due to domain shifts. To address this challenge, we develop and motivate a method for using large language models (LLMs) to generate large numbers of synthetic queries cheaply. The method begins by generating a small number of synthetic queries using an expensive LLM. After that, a much less expensive one is used to create large numbers of synthetic queries, which are used to fine-tune a family of reranker models. These rerankers are then distilled into a single efficient retriever for use in the target domain. We show that this technique boosts zero-shot accuracy in long-tail domains, even where only 2K synthetic queries are used for fine-tuning, and that it achieves substantially lower latency than standard reranking methods. We make our end-to-end approach, including our synthetic datasets and replication code, publicly available on Github.
Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP
Dec 28, 2022


Retrieval-augmented in-context learning has emerged as a powerful approach for addressing knowledge-intensive tasks using frozen language models (LM) and retrieval models (RM). Existing work has combined these in simple "retrieve-then-read" pipelines in which the RM retrieves passages that are inserted into the LM prompt. To begin to fully realize the potential of frozen LMs and RMs, we propose Demonstrate-Search-Predict (DSP), a framework that relies on passing natural language texts in sophisticated pipelines between an LM and an RM. DSP can express high-level programs that bootstrap pipeline-aware demonstrations, search for relevant passages, and generate grounded predictions, systematically breaking down problems into small transformations that the LM and RM can handle more reliably. We have written novel DSP programs for answering questions in open-domain, multi-hop, and conversational settings, establishing in early evaluations new state-of-the-art in-context learning results and delivering 37-200%, 8-40%, and 80-290% relative gains against vanilla LMs, a standard retrieve-then-read pipeline, and a contemporaneous self-ask pipeline, respectively.