 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"On the goals of linguistic theory": Revisiting Chomskyan theories in the era of AI
Nov 15, 2024



Theoretical linguistics seeks to explain what human language is, and why. Linguists and cognitive scientists have proposed different theoretical models of what language is, as well as cognitive factors that shape it, and allow humans to 'produce', 'understand', and 'acquire' natural languages. However, humans may no longer be the only ones learning to 'generate', 'parse', and 'learn' natural language: artificial intelligence (AI) models such as large language models are proving to have impressive linguistic capabilities. Many are thus questioning what role, if any, such models should play in helping theoretical linguistics reach its ultimate research goals? In this paper, we propose to answer this question, by reiterating the tenets of generative linguistics, a leading school of thought in the field, and by considering how AI models as theories of language relate to each of these important concepts. Specifically, we consider three foundational principles, finding roots in the early works of Noam Chomsky: (1) levels of theoretical adequacy; (2) procedures for linguistic theory development; (3) language learnability and Universal Grammar. In our discussions of each principle, we give special attention to two types of AI models: neural language models and neural grammar induction models. We will argue that such models, in particular neural grammar induction models, do have a role to play, but that this role is largely modulated by the stance one takes regarding each of these three guiding principles.
VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment
Oct 02, 2024



Large language models (LLMs) are increasingly applied to complex reasoning tasks that require executing several complex steps before receiving any reward. Properly assigning credit to these steps is essential for enhancing model performance. Proximal Policy Optimization (PPO), a state-of-the-art reinforcement learning (RL) algorithm used for LLM finetuning, employs value networks to tackle credit assignment. However, value networks face challenges in predicting the expected cumulative rewards accurately in complex reasoning tasks, often leading to high-variance updates and suboptimal performance. In this work, we systematically evaluate the efficacy of value networks and reveal their significant shortcomings in reasoning-heavy LLM tasks, showing that they barely outperform a random baseline when comparing alternative steps. To address this, we propose VinePPO, a straightforward approach that leverages the flexibility of language environments to compute unbiased Monte Carlo-based estimates, bypassing the need for large value networks. Our method consistently outperforms PPO and other RL-free baselines across MATH and GSM8K datasets with fewer gradient updates (up to 9x), less wall-clock time (up to 3.0x). These results emphasize the importance of accurate credit assignment in RL finetuning of LLM and demonstrate VinePPO's potential as a superior alternative.
Learning Action and Reasoning-Centric Image Editing from Videos and Simulations
Jul 03, 2024



An image editing model should be able to perform diverse edits, ranging from object replacement, changing attributes or style, to performing actions or movement, which require many forms of reasoning. Current general instruction-guided editing models have significant shortcomings with action and reasoning-centric edits. Object, attribute or stylistic changes can be learned from visually static datasets. On the other hand, high-quality data for action and reasoning-centric edits is scarce and has to come from entirely different sources that cover e.g. physical dynamics, temporality and spatial reasoning. To this end, we meticulously curate the AURORA Dataset (Action-Reasoning-Object-Attribute), a collection of high-quality training data, human-annotated and curated from videos and simulation engines. We focus on a key aspect of quality training data: triplets (source image, prompt, target image) contain a single meaningful visual change described by the prompt, i.e., truly minimal changes between source and target images. To demonstrate the value of our dataset, we evaluate an AURORA-finetuned model on a new expert-curated benchmark (AURORA-Bench) covering 8 diverse editing tasks. Our model significantly outperforms previous editing models as judged by human raters. For automatic evaluations, we find important flaws in previous metrics and caution their use for semantically hard editing tasks. Instead, we propose a new automatic metric that focuses on discriminative understanding. We hope that our efforts : (1) curating a quality training dataset and an evaluation benchmark, (2) developing critical evaluations, and (3) releasing a state-of-the-art model, will fuel further progress on general image editing.
Reframing linguistic bootstrapping as joint inference using visually-grounded grammar induction models
Jun 17, 2024



Semantic and syntactic bootstrapping posit that children use their prior knowledge of one linguistic domain, say syntactic relations, to help later acquire another, such as the meanings of new words. Empirical results supporting both theories may tempt us to believe that these are different learning strategies, where one may precede the other. Here, we argue that they are instead both contingent on a more general learning strategy for language acquisition: joint learning. Using a series of neural visually-grounded grammar induction models, we demonstrate that both syntactic and semantic bootstrapping effects are strongest when syntax and semantics are learnt simultaneously. Joint learning results in better grammar induction, realistic lexical category learning, and better interpretations of novel sentence and verb meanings. Joint learning makes language acquisition easier for learners by mutually constraining the hypotheses spaces for both syntax and semantics. Studying the dynamics of joint inference over many input sources and modalities represents an important new direction for language modeling and learning research in both cognitive sciences and AI, as it may help us explain how language can be acquired in more constrained learning settings.
Learning the meanings of function words from grounded language using a visual question answering model
Aug 16, 2023



Interpreting a seemingly-simple function word like "or", "behind", or "more" can require logical, numerical, and relational reasoning. How are such words learned by children? Prior acquisition theories have often relied on positing a foundation of innate knowledge. Yet recent neural-network based visual question answering models apparently can learn to use function words as part of answering questions about complex visual scenes. In this paper, we study what these models learn about function words, in the hope of better understanding how the meanings of these words can be learnt by both models and children. We show that recurrent models trained on visually grounded language learn gradient semantics for function words requiring spacial and numerical reasoning. Furthermore, we find that these models can learn the meanings of logical connectives "and" and "or" without any prior knowledge of logical reasoning, as well as early evidence that they can develop the ability to reason about alternative expressions when interpreting language. Finally, we show that word learning difficulty is dependent on frequency in models' input. Our findings offer evidence that it is possible to learn the meanings of function words in visually grounded context by using non-symbolic general statistical learning algorithms, without any prior knowledge of linguistic meaning.
The Emergence of the Shape Bias Results from Communicative Efficiency
Sep 15, 2021
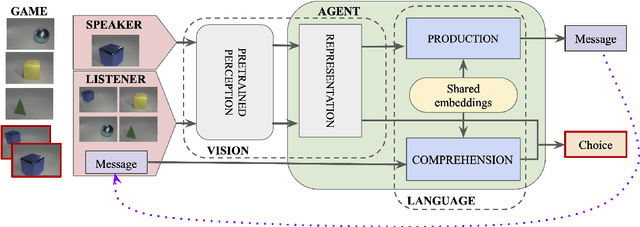
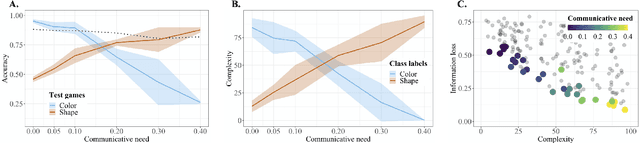
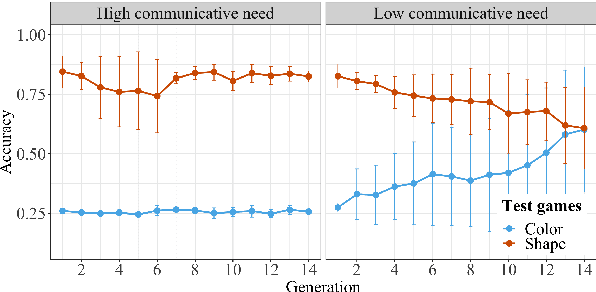
By the age of two, children tend to assume that new word categories are based on objects' shape, rather than their color or texture; this assumption is called the shape bias. They are thought to learn this bias by observing that their caregiver's language is biased towards shape based categories. This presents a chicken and egg problem: if the shape bias must be present in the language in order for children to learn it, how did it arise in language in the first place? In this paper, we propose that communicative efficiency explains both how the shape bias emerged and why it persists across generations. We model this process with neural emergent language agents that learn to communicate about raw pixelated images. First, we show that the shape bias emerges as a result of efficient communication strategies employed by agents. Second, we show that pressure brought on by communicative need is also necessary for it to persist across generations; simply having a shape bias in an agent's input language is insufficient. These results suggest that, over and above the operation of other learning strategies, the shape bias in human learners may emerge and be sustained by communicative pressures.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
A generalized parsing framework for Abstract Grammars
Jan 19, 2018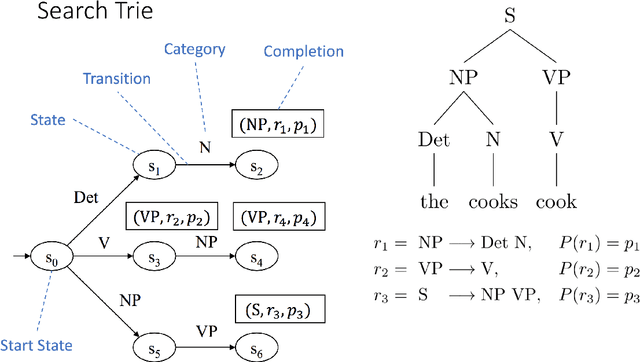
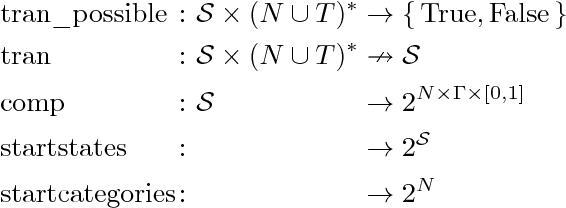
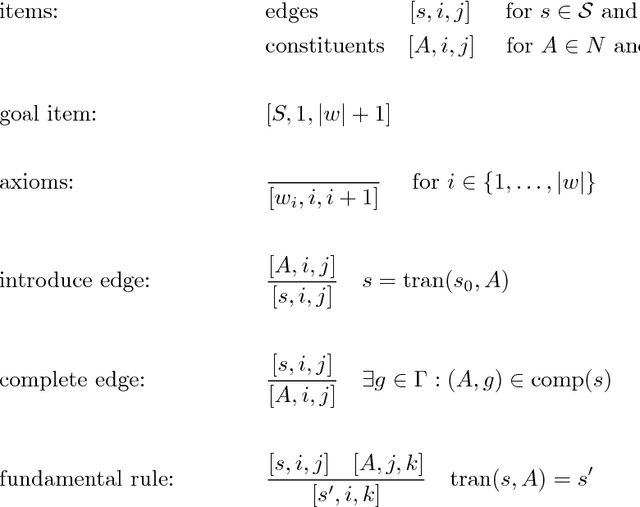

This technical report presents a general framework for parsing a variety of grammar formalisms. We develop a grammar formalism, called an Abstract Grammar, which is general enough to represent grammars at many levels of the hierarchy, including Context Free Grammars, Minimalist Grammars, and Generalized Context-free Grammars. We then develop a single parsing framework which is capable of parsing grammars which are at least up to GCFGs on the hierarchy. Our parsing framework exposes a grammar interface, so that it can parse any particular grammar formalism that can be reduced to an Abstract Grammar.
Grammar induction for mildly context sensitive languages using variational Bayesian inference
Jan 18, 2018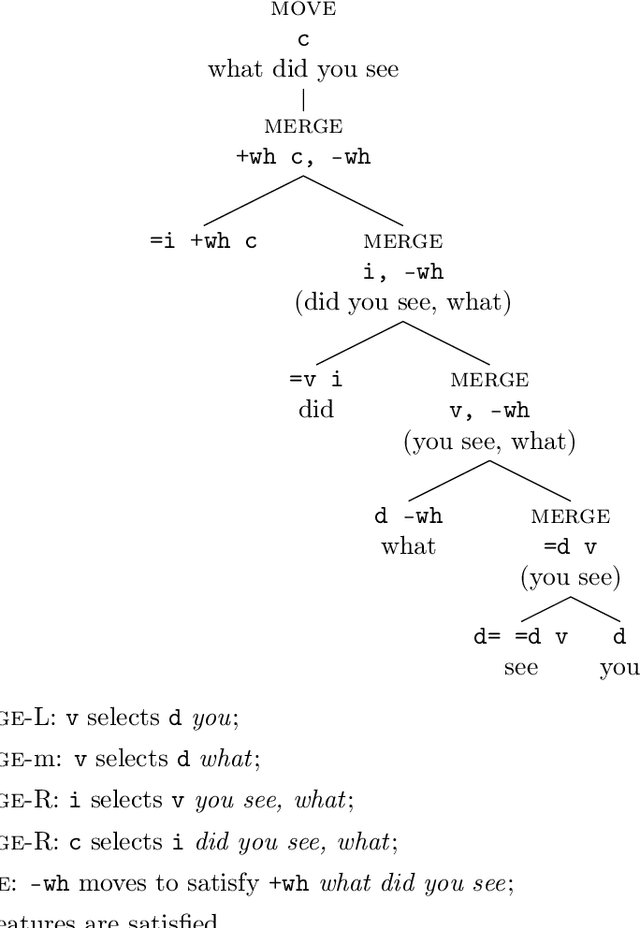
The following technical report presents a formal approach to probabilistic minimalist grammar induction. We describe a formalization of a minimalist grammar. Based on this grammar, we define a generative model for minimalist derivations. We then present a generalized algorithm for the application of variational Bayesian inference to lexicalized mildly context sensitive language grammars which in this paper is applied to the previously defined minimalist grammar.