 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When Not to Decide: A Framework for Overcoming Factual Presumptuousness in AI Adjudication
Apr 21, 2026A well-known limitation of AI systems is presumptuousness: the tendency of AI systems to provide confident answers when information may be lacking. This challenge is particularly acute in legal applications, where a core task for attorneys, judges, and administrators is to determine whether evidence is sufficient to reach a conclusion. We study this problem in the important setting of unemployment insurance adjudication, which has seen rapid integration of AI systems and where the question of additional fact-finding poses the most significant bottleneck for a system that affects millions of applicants annually. First, through a collaboration with the Colorado Department of Labor and Employment, we secure rare access to official training materials and guidance to design a novel benchmark that systematically varies in information completeness. Second, we evaluate four leading AI platforms and show that standard RAG-based approaches achieve an average of only 15% accuracy when information is insufficient. Third, advanced prompting methods improve accuracy on inconclusive cases but over-correct, withholding decisions even on clear cases. Fourth, we introduce a structured framework requiring explicit identification of missing information before any determination (SPEC, Structured Prompting for Evidence Checklists). SPEC achieves 89% overall accuracy, while appropriately deferring when evidence is insufficient -- demonstrating that presumptuousness in legal AI is systematic but addressable, and that doing so is a necessary step towards systems that reliably support, rather than supplant, human judgment wherever decisions must await sufficient evidence.
Estimating near-verbatim extraction risk in language models with decoding-constrained beam search
Mar 26, 2026Recent work shows that standard greedy-decoding extraction methods for quantifying memorization in LLMs miss how extraction risk varies across sequences. Probabilistic extraction -- computing the probability of generating a target suffix given a prefix under a decoding scheme -- addresses this, but is tractable only for verbatim memorization, missing near-verbatim instances that pose similar privacy and copyright risks. Quantifying near-verbatim extraction risk is expensive: the set of near-verbatim suffixes is combinatorially large, and reliable Monte Carlo (MC) estimation can require ~100,000 samples per sequence. To mitigate this cost, we introduce decoding-constrained beam search, which yields deterministic lower bounds on near-verbatim extraction risk at a cost comparable to ~20 MC samples per sequence. Across experiments, our approach surfaces information invisible to verbatim methods: many more extractable sequences, substantially larger per-sequence extraction mass, and patterns in how near-verbatim extraction risk manifests across model sizes and types of text.
The Limits of AI Data Transparency Policy: Three Disclosure Fallacies
Jan 26, 2026Data transparency has emerged as a rallying cry for addressing concerns about AI: data quality, privacy, and copyright chief among them. Yet while these calls are crucial for accountability, current transparency policies often fall short of their intended aims. Similar to nutrition facts for food, policies aimed at nutrition facts for AI currently suffer from a limited consideration of research on effective disclosures. We offer an institutional perspective and identify three common fallacies in policy implementations of data disclosures for AI. First, many data transparency proposals exhibit a specification gap between the stated goals of data transparency and the actual disclosures necessary to achieve such goals. Second, reform attempts exhibit an enforcement gap between required disclosures on paper and enforcement to ensure compliance in fact. Third, policy proposals manifest an impact gap between disclosed information and meaningful changes in developer practices and public understanding. Informed by the social science on transparency, our analysis identifies affirmative paths for transparency that are effective rather than merely symbolic.
Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
Dec 10, 2025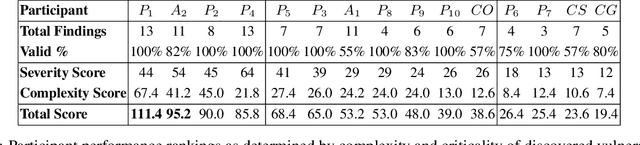
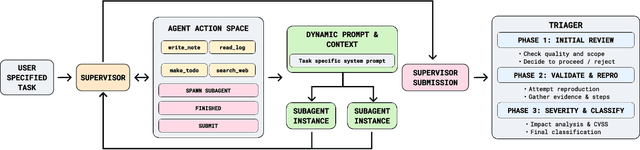
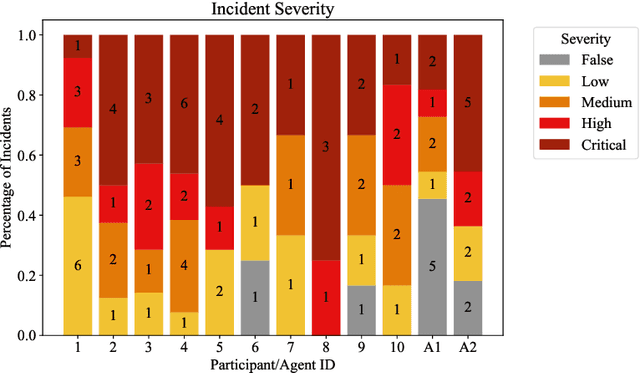
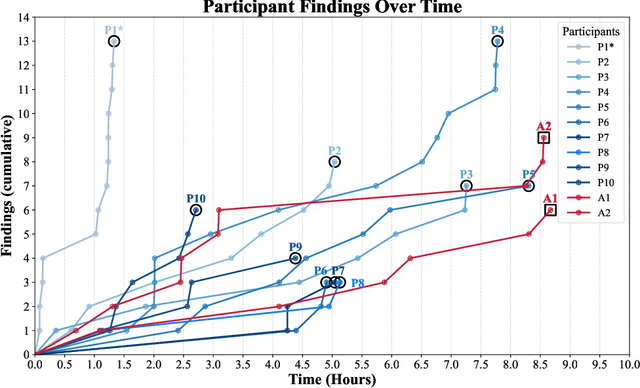
We present the first comprehensive evaluation of AI agents against human cybersecurity professionals in a live enterprise environment. We evaluate ten cybersecurity professionals alongside six existing AI agents and ARTEMIS, our new agent scaffold, on a large university network consisting of ~8,000 hosts across 12 subnets. ARTEMIS is a multi-agent framework featuring dynamic prompt generation, arbitrary sub-agents, and automatic vulnerability triaging. In our comparative study, ARTEMIS placed second overall, discovering 9 valid vulnerabilities with an 82% valid submission rate and outperforming 9 of 10 human participants. While existing scaffolds such as Codex and CyAgent underperformed relative to most human participants, ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants. We observe that AI agents offer advantages in systematic enumeration, parallel exploitation, and cost -- certain ARTEMIS variants cost $18/hour versus $60/hour for professional penetration testers. We also identify key capability gaps: AI agents exhibit higher false-positive rates and struggle with GUI-based tasks.
Near-Exponential Savings for Mean Estimation with Active Learning
Nov 07, 2025We study the problem of efficiently estimating the mean of a $k$-class random variable, $Y$, using a limited number of labels, $N$, in settings where the analyst has access to auxiliary information (i.e.: covariates) $X$ that may be informative about $Y$. We propose an active learning algorithm ("PartiBandits") to estimate $\mathbb{E}[Y]$. The algorithm yields an estimate, $\widehatμ_{\text{PB}}$, such that $\left( \widehatμ_{\text{PB}} - \mathbb{E}[Y]\right)^2$ is $\tilde{\mathcal{O}}\left( \frac{ν+ \exp(c \cdot (-N/\log(N))) }{N} \right)$, where $c > 0$ is a constant and $ν$ is the risk of the Bayes-optimal classifier. PartiBandits is essentially a two-stage algorithm. In the first stage, it learns a partition of the unlabeled data that shrinks the average conditional variance of $Y$. In the second stage it uses a UCB-style subroutine ("WarmStart-UCB") to request labels from each stratum round-by-round. Both the main algorithm's and the subroutine's convergence rates are minimax optimal in classical settings. PartiBandits bridges the UCB and disagreement-based approaches to active learning despite these two approaches being designed to tackle very different tasks. We illustrate our methods through simulation using nationwide electronic health records. Our methods can be implemented using the PartiBandits package in R.
AI for Statutory Simplification: A Comprehensive State Legal Corpus and Labor Benchmark
Aug 26, 2025One of the emerging use cases of AI in law is for code simplification: streamlining, distilling, and simplifying complex statutory or regulatory language. One U.S. state has claimed to eliminate one third of its state code using AI. Yet we lack systematic evaluations of the accuracy, reliability, and risks of such approaches. We introduce LaborBench, a question-and-answer benchmark dataset designed to evaluate AI capabilities in this domain. We leverage a unique data source to create LaborBench: a dataset updated annually by teams of lawyers at the U.S. Department of Labor, who compile differences in unemployment insurance laws across 50 states for over 101 dimensions in a six-month process, culminating in a 200-page publication of tables. Inspired by our collaboration with one U.S. state to explore using large language models (LLMs) to simplify codes in this domain, where complexity is particularly acute, we transform the DOL publication into LaborBench. This provides a unique benchmark for AI capacity to conduct, distill, and extract realistic statutory and regulatory information. To assess the performance of retrieval augmented generation (RAG) approaches, we also compile StateCodes, a novel and comprehensive state statute and regulatory corpus of 8.7 GB, enabling much more systematic research into state codes. We then benchmark the performance of information retrieval and state-of-the-art large LLMs on this data and show that while these models are helpful as preliminary research for code simplification, the overall accuracy is far below the touted promises for LLMs as end-to-end pipelines for regulatory simplification.
BountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems
May 21, 2025AI agents have the potential to significantly alter the cybersecurity landscape. To help us understand this change, we introduce the first framework to capture offensive and defensive cyber-capabilities in evolving real-world systems. Instantiating this framework with BountyBench, we set up 25 systems with complex, real-world codebases. To capture the vulnerability lifecycle, we define three task types: Detect (detecting a new vulnerability), Exploit (exploiting a specific vulnerability), and Patch (patching a specific vulnerability). For Detect, we construct a new success indicator, which is general across vulnerability types and provides localized evaluation. We manually set up the environment for each system, including installing packages, setting up server(s), and hydrating database(s). We add 40 bug bounties, which are vulnerabilities with monetary awards from \$10 to \$30,485, and cover 9 of the OWASP Top 10 Risks. To modulate task difficulty, we devise a new strategy based on information to guide detection, interpolating from identifying a zero day to exploiting a specific vulnerability. We evaluate 5 agents: Claude Code, OpenAI Codex CLI, and custom agents with GPT-4.1, Gemini 2.5 Pro Preview, and Claude 3.7 Sonnet Thinking. Given up to three attempts, the top-performing agents are Claude Code (5% on Detect, mapping to \$1,350), Custom Agent with Claude 3.7 Sonnet Thinking (5% on Detect, mapping to \$1,025; 67.5% on Exploit), and OpenAI Codex CLI (5% on Detect, mapping to \$2,400; 90% on Patch, mapping to \$14,422). OpenAI Codex CLI and Claude Code are more capable at defense, achieving higher Patch scores of 90% and 87.5%, compared to Exploit scores of 32.5% and 57.5% respectively; in contrast, the custom agents are relatively balanced between offense and defense, achieving Exploit scores of 40-67.5% and Patch scores of 45-60%.
Extracting memorized pieces of (copyrighted) books from open-weight language models
May 18, 2025Plaintiffs and defendants in copyright lawsuits over generative AI often make sweeping, opposing claims about the extent to which large language models (LLMs) have memorized plaintiffs' protected expression. Drawing on adversarial ML and copyright law, we show that these polarized positions dramatically oversimplify the relationship between memorization and copyright. To do so, we leverage a recent probabilistic extraction technique to extract pieces of the Books3 dataset from 13 open-weight LLMs. Through numerous experiments, we show that it's possible to extract substantial parts of at least some books from different LLMs. This is evidence that the LLMs have memorized the extracted text; this memorized content is copied inside the model parameters. But the results are complicated: the extent of memorization varies both by model and by book. With our specific experiments, we find that the largest LLMs don't memorize most books -- either in whole or in part. However, we also find that Llama 3.1 70B memorizes some books, like Harry Potter and 1984, almost entirely. We discuss why our results have significant implications for copyright cases, though not ones that unambiguously favor either side.
A Reasoning-Focused Legal Retrieval Benchmark
May 06, 2025As the legal community increasingly examines the use of large language models (LLMs) for various legal applications, legal AI developers have turned to retrieval-augmented LLMs ("RAG" systems) to improve system performance and robustness. An obstacle to the development of specialized RAG systems is the lack of realistic legal RAG benchmarks which capture the complexity of both legal retrieval and downstream legal question-answering. To address this, we introduce two novel legal RAG benchmarks: Bar Exam QA and Housing Statute QA. Our tasks correspond to real-world legal research tasks, and were produced through annotation processes which resemble legal research. We describe the construction of these benchmarks and the performance of existing retriever pipelines. Our results suggest that legal RAG remains a challenging application, thus motivating future research.
Fairness through Difference Awareness: Measuring Desired Group Discrimination in LLMs
Feb 04, 2025



Algorithmic fairness has conventionally adopted a perspective of racial color-blindness (i.e., difference unaware treatment). We contend that in a range of important settings, group difference awareness matters. For example, differentiating between groups may be necessary in legal contexts (e.g., the U.S. compulsory draft applies to men but not women) and harm assessments (e.g., calling a girl a terrorist may be less harmful than calling a Muslim person one). In our work we first introduce an important distinction between descriptive (fact-based), normative (value-based), and correlation (association-based) benchmarks. This distinction is significant because each category requires distinct interpretation and mitigation tailored to its specific characteristics. Then, we present a benchmark suite composed of eight different scenarios for a total of 16k questions that enables us to assess difference awareness. Finally, we show results across ten models that demonstrate difference awareness is a distinct dimension of fairness where existing bias mitigation strategies may backfire.