 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Scaling Video VLMs for Long Video Understanding
May 29, 2026Video vision-language models (VLMs) are increasingly used in long-horizon and streaming settings, yet most video encoders still rely on spatiotemporal self-attention, causing compute and latency to grow quadratically with the number of frames. Existing efficiency methods improve scalability but often lose accuracy relative to full self-attention, for example through aggressive frame/token dropping or coarse attention approximations. We introduce StateKV, an inference-time method that adapts pretrained long-video VLMs to linear-time video prefill by carrying cross-frame context in a fixed-capacity, importance-based recurrent state, paired with a second full per-frame cache used for decoding. Across three long-video benchmarks and seven models spanning three families and multiple scales, StateKV remains close to full self-attention and consistently outperforms dominant sliding-window / recency-based streaming approximations, without fine-tuning or architectural changes. StateKV also reduces video-prefill cost measured FLOPs, enabling stronger accuracy at a fixed compute budget by running larger models. These results suggest a practical step toward scalable long-video understanding.
GPIC: A Giant Permissive Image Corpus for Visual Generation
May 28, 2026Studying scalable methods for visual generative modeling requires large, accessible, and stable datasets. We introduce GPIC, a Giant Permissive Image Corpus of approximately 28 trillion pixels. GPIC comprises diverse internet images captioned by a state-of-the-art vision-language model, including 100M training, 200K validation, and 1M test examples. Moreover, all GPIC images are permissively licensed for both research and commercial use. GPIC is safety-filtered, deduplicated, and centrally hosted on Hugging Face. We provide a benchmarking protocol for generative modeling on GPIC. Finally, we provide a reference baseline for pixel-space flow matching on GPIC. Our dataset, benchmark, and models are available at https://huggingface.co/datasets/stanford-vision-lab/gpic. Evaluation toolkit and code are available at https://gpic.stanford.edu
SurfPhase: 3D Interfacial Dynamics in Two-Phase Flows from Sparse Videos
Feb 11, 2026Interfacial dynamics in two-phase flows govern momentum, heat, and mass transfer, yet remain difficult to measure experimentally. Classical techniques face intrinsic limitations near moving interfaces, while existing neural rendering methods target single-phase flows with diffuse boundaries and cannot handle sharp, deformable liquid-vapor interfaces. We propose SurfPhase, a novel model for reconstructing 3D interfacial dynamics from sparse camera views. Our approach integrates dynamic Gaussian surfels with a signed distance function formulation for geometric consistency, and leverages a video diffusion model to synthesize novel-view videos to refine reconstruction from sparse observations. We evaluate on a new dataset of high-speed pool boiling videos, demonstrating high-quality view synthesis and velocity estimation from only two camera views. Project website: https://yuegao.me/SurfPhase.
Future Optical Flow Prediction Improves Robot Control & Video Generation
Jan 15, 2026Future motion representations, such as optical flow, offer immense value for control and generative tasks. However, forecasting generalizable spatially dense motion representations remains a key challenge, and learning such forecasting from noisy, real-world data remains relatively unexplored. We introduce FOFPred, a novel language-conditioned optical flow forecasting model featuring a unified Vision-Language Model (VLM) and Diffusion architecture. This unique combination enables strong multimodal reasoning with pixel-level generative fidelity for future motion prediction. Our model is trained on web-scale human activity data-a highly scalable but unstructured source. To extract meaningful signals from this noisy video-caption data, we employ crucial data preprocessing techniques and our unified architecture with strong image pretraining. The resulting trained model is then extended to tackle two distinct downstream tasks in control and generation. Evaluations across robotic manipulation and video generation under language-driven settings establish the cross-domain versatility of FOFPred, confirming the value of a unified VLM-Diffusion architecture and scalable learning from diverse web data for future optical flow prediction.
Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
Dec 19, 2025Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.
Strefer: Empowering Video LLMs with Space-Time Referring and Reasoning via Synthetic Instruction Data
Sep 03, 2025

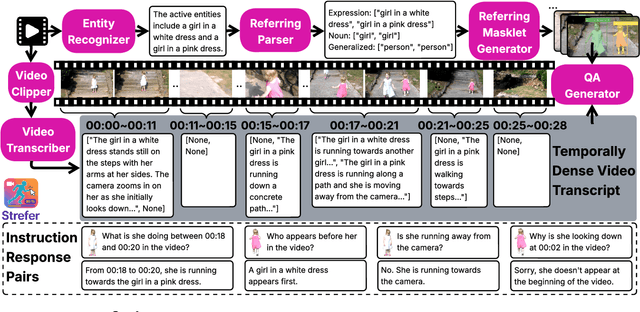
Next-generation AI companions must go beyond general video understanding to resolve spatial and temporal references in dynamic, real-world environments. Existing Video Large Language Models (Video LLMs), while capable of coarse-level comprehension, struggle with fine-grained, spatiotemporal reasoning, especially when user queries rely on time-based event references for temporal anchoring, or gestural cues for spatial anchoring to clarify object references and positions. To bridge this critical gap, we introduce Strefer, a synthetic instruction data generation framework designed to equip Video LLMs with spatiotemporal referring and reasoning capabilities. Strefer produces diverse instruction-tuning data using a data engine that pseudo-annotates temporally dense, fine-grained video metadata, capturing rich spatial and temporal information in a structured manner, including subjects, objects, their locations as masklets, and their action descriptions and timelines. Our approach enhances the ability of Video LLMs to interpret spatial and temporal references, fostering more versatile, space-time-aware reasoning essential for real-world AI companions. Without using proprietary models, costly human annotation, or the need to annotate large volumes of new videos, experimental evaluations show that models trained with data produced by Strefer outperform baselines on tasks requiring spatial and temporal disambiguation. Additionally, these models exhibit enhanced space-time-aware reasoning, establishing a new foundation for perceptually grounded, instruction-tuned Video LLMs.
Exploring Diffusion Transformer Designs via Grafting
Jun 06, 2025Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
Understanding Complexity in VideoQA via Visual Program Generation
May 19, 2025We propose a data-driven approach to analyzing query complexity in Video Question Answering (VideoQA). Previous efforts in benchmark design have relied on human expertise to design challenging questions, yet we experimentally show that humans struggle to predict which questions are difficult for machine learning models. Our automatic approach leverages recent advances in code generation for visual question answering, using the complexity of generated code as a proxy for question difficulty. We demonstrate that this measure correlates significantly better with model performance than human estimates. To operationalize this insight, we propose an algorithm for estimating question complexity from code. It identifies fine-grained primitives that correlate with the hardest questions for any given set of models, making it easy to scale to new approaches in the future. Finally, to further illustrate the utility of our method, we extend it to automatically generate complex questions, constructing a new benchmark that is 1.9 times harder than the popular NExT-QA.
VLM Q-Learning: Aligning Vision-Language Models for Interactive Decision-Making
May 06, 2025Recent research looks to harness the general knowledge and reasoning of large language models (LLMs) into agents that accomplish user-specified goals in interactive environments. Vision-language models (VLMs) extend LLMs to multi-modal data and provide agents with the visual reasoning necessary for new applications in areas such as computer automation. However, agent tasks emphasize skills where accessible open-weight VLMs lag behind their LLM equivalents. For example, VLMs are less capable of following an environment's strict output syntax requirements and are more focused on open-ended question answering. Overcoming these limitations requires supervised fine-tuning (SFT) on task-specific expert demonstrations. Our work approaches these challenges from an offline-to-online reinforcement learning (RL) perspective. RL lets us fine-tune VLMs to agent tasks while learning from the unsuccessful decisions of our own model or more capable (larger) models. We explore an off-policy RL solution that retains the stability and simplicity of the widely used SFT workflow while allowing our agent to self-improve and learn from low-quality datasets. We demonstrate this technique with two open-weight VLMs across three multi-modal agent domains.
AdaVid: Adaptive Video-Language Pretraining
Apr 16, 2025Contrastive video-language pretraining has demonstrated great success in learning rich and robust video representations. However, deploying such video encoders on compute-constrained edge devices remains challenging due to their high computational demands. Additionally, existing models are typically trained to process only short video clips, often limited to 4 to 64 frames. In this paper, we introduce AdaVid, a flexible architectural framework designed to learn efficient video encoders that can dynamically adapt their computational footprint based on available resources. At the heart of AdaVid is an adaptive transformer block, inspired by Matryoshka Representation Learning, which allows the model to adjust its hidden embedding dimension at inference time. We show that AdaVid-EgoVLP, trained on video-narration pairs from the large-scale Ego4D dataset, matches the performance of the standard EgoVLP on short video-language benchmarks using only half the compute, and even outperforms EgoVLP when given equal computational resources. We further explore the trade-off between frame count and compute on the challenging Diving48 classification benchmark, showing that AdaVid enables the use of more frames without exceeding computational limits. To handle longer videos, we also propose a lightweight hierarchical network that aggregates short clip features, achieving a strong balance between compute efficiency and accuracy across several long video benchmarks.