 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreater accessibility can amplify discrimination in generative AI
Mar 23, 2026Hundreds of millions of people rely on large language models (LLMs) for education, work, and even healthcare. Yet these models are known to reproduce and amplify social biases present in their training data. Moreover, text-based interfaces remain a barrier for many, for example, users with limited literacy, motor impairments, or mobile-only devices. Voice interaction promises to expand accessibility, but unlike text, speech carries identity cues that users cannot easily mask, raising concerns about whether accessibility gains may come at the cost of equitable treatment. Here we show that audio-enabled LLMs exhibit systematic gender discrimination, shifting responses toward gender-stereotyped adjectives and occupations solely on the basis of speaker voice, and amplifying bias beyond that observed in text-based interaction. Thus, voice interfaces do not merely extend text models to a new modality but introduce distinct bias mechanisms tied to paralinguistic cues. Complementary survey evidence ($n=1,000$) shows that infrequent chatbot users are most hesitant to undisclosed attribute inference and most likely to disengage when such practices are revealed. To demonstrate a potential mitigation strategy, we show that pitch manipulation can systematically regulate gender-discriminatory outputs. Overall, our findings reveal a critical tension in AI development: efforts to expand accessibility through voice interfaces simultaneously create new pathways for discrimination, demanding that fairness and accessibility be addressed in tandem.
"Sorry, I Didn't Catch That": How Speech Models Miss What Matters Most
Feb 16, 2026Despite speech recognition systems achieving low word error rates on standard benchmarks, they often fail on short, high-stakes utterances in real-world deployments. Here, we study this failure mode in a high-stakes task: the transcription of U.S. street names as spoken by U.S. participants. We evaluate 15 models from OpenAI, Deepgram, Google, and Microsoft on recordings from linguistically diverse U.S. speakers and find an average transcription error rate of 44%. We quantify the downstream impact of failed transcriptions by geographic locations and show that mis-transcriptions systematically cause errors for all speakers, but that routing distance errors are twice as large for non-English primary speakers compared to English primary speakers. To mitigate this harm, we introduce a synthetic data generation approach that produces diverse pronunciations of named entities using open-source text-to-speech models. Fine-tuning with less than 1,000 synthetic samples improves street name transcription accuracy by nearly 60% (relative to base models) for non-English primary speakers. Our results highlight a critical gap between benchmark performance and real-world reliability in speech systems and demonstrate a simple, scalable path to reducing high-stakes transcription errors.
Humans overrely on overconfident language models, across languages
Jul 08, 2025



As large language models (LLMs) are deployed globally, it is crucial that their responses are calibrated across languages to accurately convey uncertainty and limitations. Previous work has shown that LLMs are linguistically overconfident in English, leading users to overrely on confident generations. However, the usage and interpretation of epistemic markers (e.g., 'It's definitely,' 'I think') can differ sharply across languages. Here, we study the risks of multilingual linguistic (mis)calibration, overconfidence, and overreliance across five languages to evaluate the safety of LLMs in a global context. We find that overreliance risks are high across all languages. We first analyze the distribution of LLM-generated epistemic markers, and observe that while LLMs are cross-linguistically overconfident, they are also sensitive to documented linguistic variation. For example, models generate the most markers of uncertainty in Japanese and the most markers of certainty in German and Mandarin. We then measure human reliance rates across languages, finding that while users strongly rely on confident LLM generations in all languages, reliance behaviors differ cross-linguistically: for example, users rely significantly more on expressions of uncertainty in Japanese than in English. Taken together, these results indicate high risk of reliance on overconfident model generations across languages. Our findings highlight the challenges of multilingual linguistic calibration and stress the importance of culturally and linguistically contextualized model safety evaluations.
ELI-Why: Evaluating the Pedagogical Utility of Language Model Explanations
Jun 17, 2025



Language models today are widely used in education, yet their ability to tailor responses for learners with varied informational needs and knowledge backgrounds remains under-explored. To this end, we introduce ELI-Why, a benchmark of 13.4K "Why" questions to evaluate the pedagogical capabilities of language models. We then conduct two extensive human studies to assess the utility of language model-generated explanatory answers (explanations) on our benchmark, tailored to three distinct educational grades: elementary, high-school and graduate school. In our first study, human raters assume the role of an "educator" to assess model explanations' fit to different educational grades. We find that GPT-4-generated explanations match their intended educational background only 50% of the time, compared to 79% for lay human-curated explanations. In our second study, human raters assume the role of a learner to assess if an explanation fits their own informational needs. Across all educational backgrounds, users deemed GPT-4-generated explanations 20% less suited on average to their informational needs, when compared to explanations curated by lay people. Additionally, automated evaluation metrics reveal that explanations generated across different language model families for different informational needs remain indistinguishable in their grade-level, limiting their pedagogical effectiveness.
Rethinking Word Similarity: Semantic Similarity through Classification Confusion
Feb 08, 2025Word similarity has many applications to social science and cultural analytics tasks like measuring meaning change over time and making sense of contested terms. Yet traditional similarity methods based on cosine similarity between word embeddings cannot capture the context-dependent, asymmetrical, polysemous nature of semantic similarity. We propose a new measure of similarity, Word Confusion, that reframes semantic similarity in terms of feature-based classification confusion. Word Confusion is inspired by Tversky's suggestion that similarity features be chosen dynamically. Here we train a classifier to map contextual embeddings to word identities and use the classifier confusion (the probability of choosing a confounding word c instead of the correct target word t) as a measure of the similarity of c and t. The set of potential confounding words acts as the chosen features. Our method is comparable to cosine similarity in matching human similarity judgments across several datasets (MEN, WirdSim353, and SimLex), and can measure similarity using predetermined features of interest. We demonstrate our model's ability to make use of dynamic features by applying it to test a hypothesis about changes in the 18th C. meaning of the French word "revolution" from popular to state action during the French Revolution. We hope this reimagining of semantic similarity will inspire the development of new tools that better capture the multi-faceted and dynamic nature of language, advancing the fields of computational social science and cultural analytics and beyond.
Rel-A.I.: An Interaction-Centered Approach To Measuring Human-LM Reliance
Jul 10, 2024The reconfiguration of human-LM interactions from simple sentence completions to complex, multi-domain, humanlike engagements necessitates new methodologies to understand how humans choose to rely on LMs. In our work, we contend that reliance is influenced by numerous factors within the interactional context of a generation, a departure from prior work that used verbalized confidence (e.g., "I'm certain the answer is...") as the key determinant of reliance. Here, we introduce Rel-A.I., an in situ, system-level evaluation approach to measure human reliance on LM-generated epistemic markers (e.g., "I think it's..", "Undoubtedly it's..."). Using this methodology, we measure reliance rates in three emergent human-LM interaction settings: long-term interactions, anthropomorphic generations, and variable subject matter. Our findings reveal that reliance is not solely based on verbalized confidence but is significantly affected by other features of the interaction context. Prior interactions, anthropomorphic cues, and subject domain all contribute to reliance variability. An expression such as, "I'm pretty sure it's...", can vary up to 20% in reliance frequency depending on its interactional context. Our work underscores the importance of context in understanding human reliance and offers future designers and researchers with a methodology to conduct such measurements.
Relying on the Unreliable: The Impact of Language Models' Reluctance to Express Uncertainty
Jan 12, 2024As natural language becomes the default interface for human-AI interaction, there is a critical need for LMs to appropriately communicate uncertainties in downstream applications. In this work, we investigate how LMs incorporate confidence about their responses via natural language and how downstream users behave in response to LM-articulated uncertainties. We examine publicly deployed models and find that LMs are unable to express uncertainties when answering questions even when they produce incorrect responses. LMs can be explicitly prompted to express confidences, but tend to be overconfident, resulting in high error rates (on average 47%) among confident responses. We test the risks of LM overconfidence by running human experiments and show that users rely heavily on LM generations, whether or not they are marked by certainty. Lastly, we investigate the preference-annotated datasets used in RLHF alignment and find that humans have a bias against texts with uncertainty. Our work highlights a new set of safety harms facing human-LM interactions and proposes design recommendations and mitigating strategies moving forward.
Navigating the Grey Area: Expressions of Overconfidence and Uncertainty in Language Models
Feb 26, 2023



Despite increasingly fluent, relevant, and coherent language generation, major gaps remain between how humans and machines use language. We argue that a key dimension that is missing from our understanding of language models (LMs) is the model's ability to interpret and generate expressions of uncertainty. Whether it be the weatherperson announcing a chance of rain or a doctor giving a diagnosis, information is often not black-and-white and expressions of uncertainty provide nuance to support human-decision making. The increasing deployment of LMs in the wild motivates us to investigate whether LMs are capable of interpreting expressions of uncertainty and how LMs' behaviors change when learning to emit their own expressions of uncertainty. When injecting expressions of uncertainty into prompts (e.g., "I think the answer is..."), we discover that GPT3's generations vary upwards of 80% in accuracy based on the expression used. We analyze the linguistic characteristics of these expressions and find a drop in accuracy when naturalistic expressions of certainty are present. We find similar effects when teaching models to emit their own expressions of uncertainty, where model calibration suffers when teaching models to emit certainty rather than uncertainty. Together, these results highlight the challenges of building LMs that interpret and generate trustworthy expressions of uncertainty.
Deconstructing NLG Evaluation: Evaluation Practices, Assumptions, and Their Implications
May 13, 2022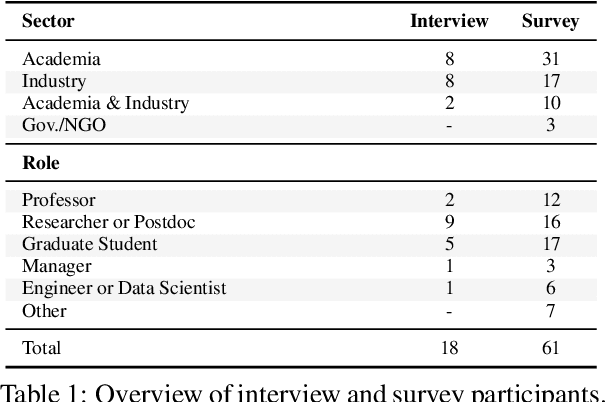
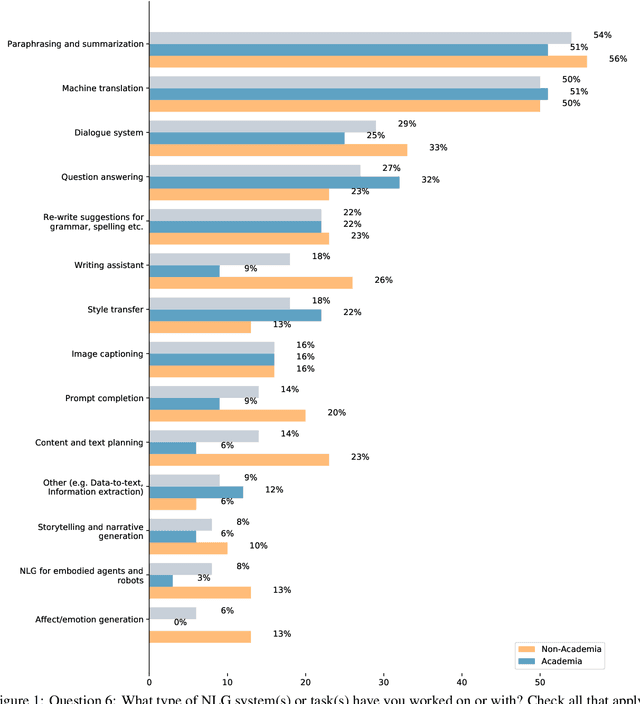
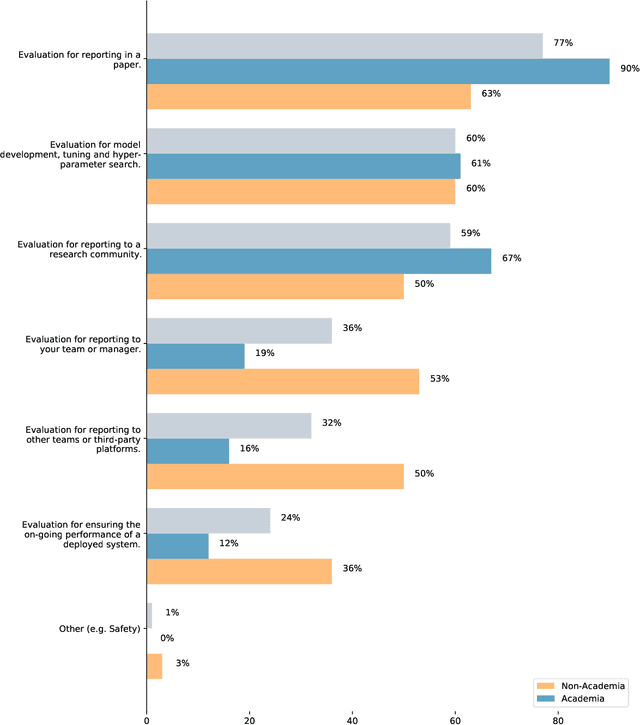
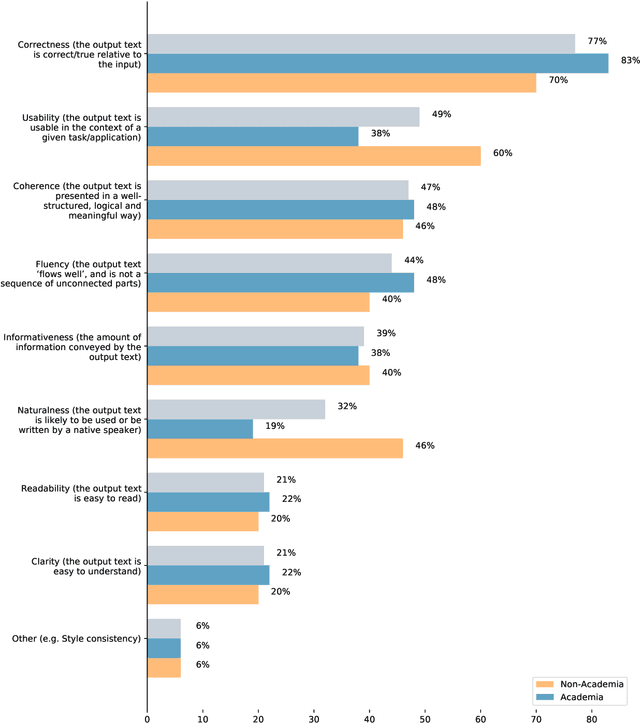
There are many ways to express similar things in text, which makes evaluating natural language generation (NLG) systems difficult. Compounding this difficulty is the need to assess varying quality criteria depending on the deployment setting. While the landscape of NLG evaluation has been well-mapped, practitioners' goals, assumptions, and constraints -- which inform decisions about what, when, and how to evaluate -- are often partially or implicitly stated, or not stated at all. Combining a formative semi-structured interview study of NLG practitioners (N=18) with a survey study of a broader sample of practitioners (N=61), we surface goals, community practices, assumptions, and constraints that shape NLG evaluations, examining their implications and how they embody ethical considerations.
Richer Countries and Richer Representations
May 10, 2022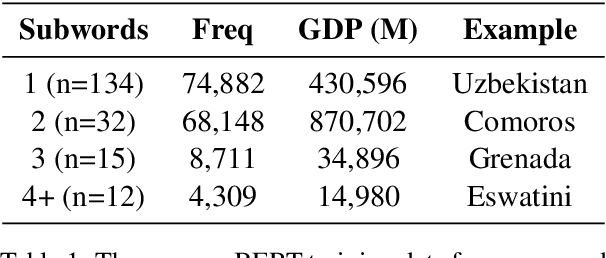
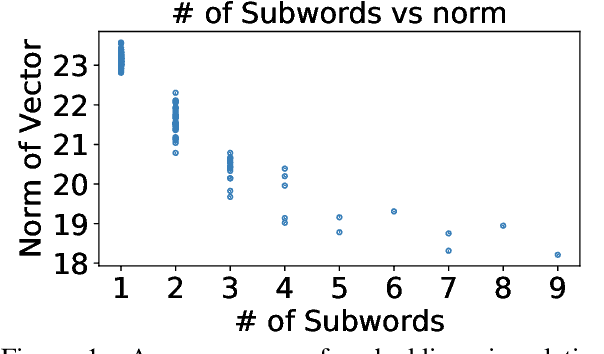
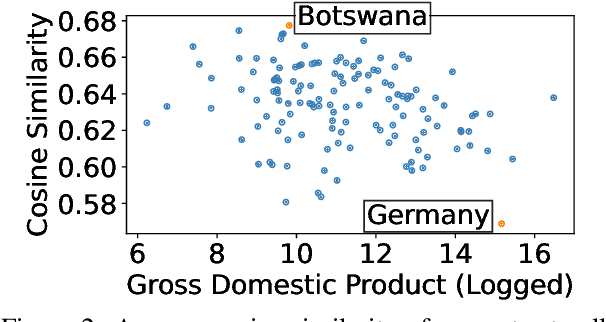
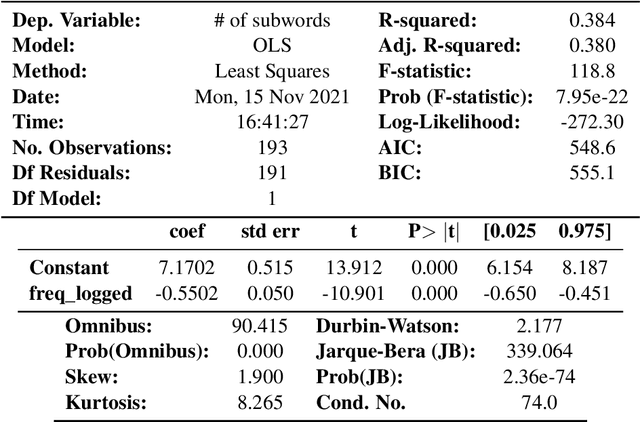
We examine whether some countries are more richly represented in embedding space than others. We find that countries whose names occur with low frequency in training corpora are more likely to be tokenized into subwords, are less semantically distinct in embedding space, and are less likely to be correctly predicted: e.g., Ghana (the correct answer and in-vocabulary) is not predicted for, "The country producing the most cocoa is [MASK].". Although these performance discrepancies and representational harms are due to frequency, we find that frequency is highly correlated with a country's GDP; thus perpetuating historic power and wealth inequalities. We analyze the effectiveness of mitigation strategies; recommend that researchers report training word frequencies; and recommend future work for the community to define and design representational guarantees.