 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWillump: A Statistically-Aware End-to-end Optimizer for Machine Learning Inference
Paper and Code
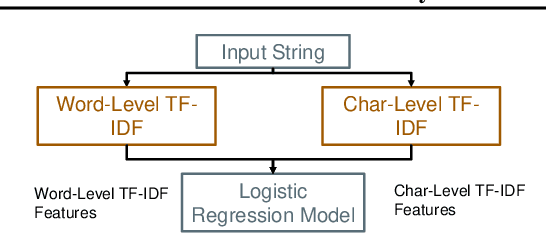

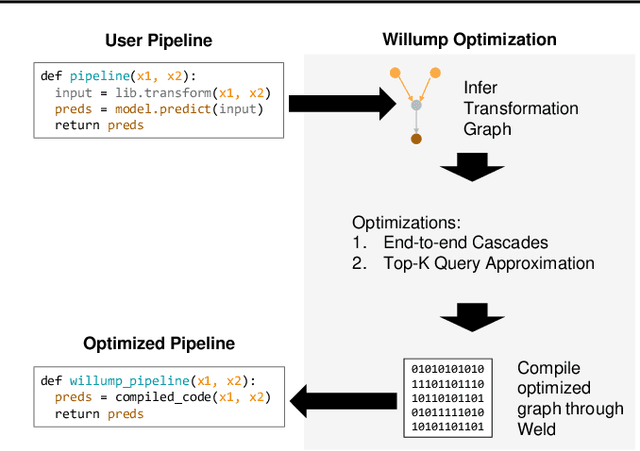
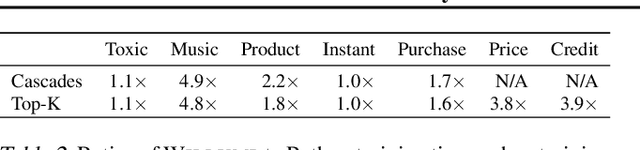
Machine learning (ML) has become increasingly important and performance-critical in modern data centers. This has led to interest in model serving systems, which perform ML inference and serve predictions to end-user applications. However, most existing model serving systems approach ML inference as an extension of conventional data serving workloads and miss critical opportunities for performance. In this paper, we present Willump, a statistically-aware optimizer for ML inference that takes advantage of key properties of ML inference not shared by traditional workloads. First, ML models can often be approximated efficiently on many "easy" inputs by judiciously using a less expensive model for these inputs (e.g., not computing all the input features). Willump automatically generates such approximations from an ML inference pipeline, providing up to 4.1$\times$ speedup without statistically significant accuracy loss. Second, ML models are often used in higher-level end-to-end queries in an ML application, such as computing the top K predictions for a recommendation model. Willump optimizes inference based on these higher-level queries by up to 5.7$\times$ over na\"ive batch inference. Willump combines these novel optimizations with standard compiler optimizations and a computation graph-aware feature caching scheme to automatically generate fast inference code for ML pipelines. We show that Willump improves performance of real-world ML inference pipelines by up to 23$\times$, with its novel optimizations giving 3.6-5.7$\times$ speedups over compilation. We also show that Willump integrates easily with existing model serving systems, such as Clipper.