 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReViSQL: Achieving Human-Level Text-to-SQL
Mar 20, 2026Translating natural language to SQL (Text-to-SQL) is a critical challenge in both database research and data analytics applications. Recent efforts have focused on enhancing SQL reasoning by developing large language models and AI agents that decompose Text-to-SQL tasks into manually designed, step-by-step pipelines. However, despite these extensive architectural engineering efforts, a significant gap remains: even state-of-the-art (SOTA) AI agents have not yet achieved the human-level accuracy on the BIRD benchmark. In this paper, we show that closing this gap does not require further architectural complexity, but rather clean training data to improve SQL reasoning of the underlying models. We introduce ReViSQL, a streamlined framework that achieves human-level accuracy on BIRD for the first time. Instead of complex AI agents, ReViSQL leverages reinforcement learning with verifiable rewards (RLVR) on BIRD-Verified, a dataset we curated comprising 2.5k verified Text-to-SQL instances based on the BIRD Train set. To construct BIRD-Verified, we design a data correction and verification workflow involving SQL experts. We identified and corrected data errors in 61.1% of a subset of BIRD Train. By training on BIRD-Verified, we show that improving data quality alone boosts the single-generation accuracy by 8.2-13.9% under the same RLVR algorithm. To further enhance performance, ReViSQL performs inference-time scaling via execution-based reconciliation and majority voting. Empirically, we demonstrate the superiority of our framework with two model scales: ReViSQL-235B-A22B and ReViSQL-30B-A3B. On an expert-verified BIRD Mini-Dev set, ReViSQL-235B-A22B achieves 93.2% execution accuracy, exceeding the proxy human-level accuracy (92.96%) and outperforming the prior open-source SOTA method by 9.8%. Our lightweight ReViSQL-30B-A3B matches the prior SOTA at a 7.5$\times$ lower per-query cost.
Behavioral Fingerprints for LLM Endpoint Stability and Identity
Mar 19, 2026The consistency of AI-native applications depends on the behavioral consistency of the model endpoints that power them. Traditional reliability metrics such as uptime, latency and throughput do not capture behavioral change, and an endpoint can remain "healthy" while its effective model identity changes due to updates to weights, tokenizers, quantization, inference engines, kernels, caching, routing, or hardware. We introduce Stability Monitor, a black-box stability monitoring system that periodically fingerprints an endpoint by sampling outputs from a fixed prompt set and comparing the resulting output distributions over time. Fingerprints are compared using a summed energy distance statistic across prompts, with permutation-test p-values as evidence of distribution shift aggregated sequentially to detect change events and define stability periods. In controlled validation, Stability Monitor detects changes to model family, version, inference stack, quantization, and behavioral parameters. In real-world monitoring of the same model hosted by multiple providers, we observe substantial provider-to-provider and within-provider stability differences.
SODIUM: From Open Web Data to Queryable Databases
Mar 19, 2026During research, domain experts often ask analytical questions whose answers require integrating data from a wide range of web sources. Thus, they must spend substantial effort searching, extracting, and organizing raw data before analysis can begin. We formalize this process as the SODIUM task, where we conceptualize open domains such as the web as latent databases that must be systematically instantiated to support downstream querying. Solving SODIUM requires (1) conducting in-depth and specialized exploration of the open web, which is further strengthened by (2) exploiting structural correlations for systematic information extraction and (3) integrating collected information into coherent, queryable database instances. To quantify the challenges in automating SODIUM, we construct SODIUM-Bench, a benchmark of 105 tasks derived from published academic papers across 6 domains, where systems are tasked with exploring the open web to collect and aggregate data from diverse sources into structured tables. Existing systems struggle with SODIUM tasks: we evaluate 6 advanced AI agents on SODIUM-Bench, with the strongest baseline achieving only 46.5% accuracy. To bridge this gap, we develop SODIUM-Agent, a multi-agent system composed of a web explorer and a cache manager. Powered by our proposed ATP-BFS algorithm and optimized through principled management of cached sources and navigation paths, SODIUM-Agent conducts deep and comprehensive web exploration and performs structurally coherent information extraction. SODIUM-Agent achieves 91.1% accuracy on SODIUM-Bench, outperforming the strongest baseline by approximately 2 times and the weakest by up to 73 times.
Noisy Data is Destructive to Reinforcement Learning with Verifiable Rewards
Mar 17, 2026Reinforcement learning with verifiable rewards (RLVR) has driven recent capability advances of large language models across various domains. Recent studies suggest that improved RLVR algorithms allow models to learn effectively from incorrect annotations, achieving performance comparable to learning from clean data. In this work, we show that these findings are invalid because the claimed 100% noisy training data is "contaminated" with clean data. After rectifying the dataset with a rigorous re-verification pipeline, we demonstrate that noise is destructive to RLVR. We show that existing RLVR algorithm improvements fail to mitigate the impact of noise, achieving similar performance to that of the basic GRPO. Furthermore, we find that the model trained on truly incorrect annotations performs 8-10% worse than the model trained on clean data across mathematical reasoning benchmarks. Finally, we show that these findings hold for real-world noise in Text2SQL tasks, where training on real-world, human annotation errors cause 5-12% lower accuracy than clean data. Our results show that current RLVR methods cannot yet compensate for poor data quality. High-quality data remains essential.
Pervasive Annotation Errors Break Text-to-SQL Benchmarks and Leaderboards
Jan 13, 2026Researchers have proposed numerous text-to-SQL techniques to streamline data analytics and accelerate the development of database-driven applications. To compare these techniques and select the best one for deployment, the community depends on public benchmarks and their leaderboards. Since these benchmarks heavily rely on human annotations during question construction and answer evaluation, the validity of the annotations is crucial. In this paper, we conduct an empirical study that (i) benchmarks annotation error rates for two widely used text-to-SQL benchmarks, BIRD and Spider 2.0-Snow, and (ii) corrects a subset of the BIRD development (Dev) set to measure the impact of annotation errors on text-to-SQL agent performance and leaderboard rankings. Through expert analysis, we show that BIRD Mini-Dev and Spider 2.0-Snow have error rates of 52.8% and 62.8%, respectively. We re-evaluate all 16 open-source agents from the BIRD leaderboard on both the original and the corrected BIRD Dev subsets. We show that performance changes range from -7% to 31% (in relative terms) and rank changes range from $-9$ to $+9$ positions. We further assess whether these impacts generalize to the full BIRD Dev set. We find that the rankings of agents on the uncorrected subset correlate strongly with those on the full Dev set (Spearman's $r_s$=0.85, $p$=3.26e-5), whereas they correlate weakly with those on the corrected subset (Spearman's $r_s$=0.32, $p$=0.23). These findings show that annotation errors can significantly distort reported performance and rankings, potentially misguiding research directions or deployment choices. Our code and data are available at https://github.com/uiuc-kang-lab/text_to_sql_benchmarks.
AIA Forecaster: Technical Report
Nov 10, 2025This technical report describes the AIA Forecaster, a Large Language Model (LLM)-based system for judgmental forecasting using unstructured data. The AIA Forecaster approach combines three core elements: agentic search over high-quality news sources, a supervisor agent that reconciles disparate forecasts for the same event, and a set of statistical calibration techniques to counter behavioral biases in large language models. On the ForecastBench benchmark (Karger et al., 2024), the AIA Forecaster achieves performance equal to human superforecasters, surpassing prior LLM baselines. In addition to reporting on ForecastBench, we also introduce a more challenging forecasting benchmark sourced from liquid prediction markets. While the AIA Forecaster underperforms market consensus on this benchmark, an ensemble combining AIA Forecaster with market consensus outperforms consensus alone, demonstrating that our forecaster provides additive information. Our work establishes a new state of the art in AI forecasting and provides practical, transferable recommendations for future research. To the best of our knowledge, this is the first work that verifiably achieves expert-level forecasting at scale.
Visual Backdoor Attacks on MLLM Embodied Decision Making via Contrastive Trigger Learning
Oct 31, 2025Multimodal large language models (MLLMs) have advanced embodied agents by enabling direct perception, reasoning, and planning task-oriented actions from visual inputs. However, such vision driven embodied agents open a new attack surface: visual backdoor attacks, where the agent behaves normally until a visual trigger appears in the scene, then persistently executes an attacker-specified multi-step policy. We introduce BEAT, the first framework to inject such visual backdoors into MLLM-based embodied agents using objects in the environments as triggers. Unlike textual triggers, object triggers exhibit wide variation across viewpoints and lighting, making them difficult to implant reliably. BEAT addresses this challenge by (1) constructing a training set that spans diverse scenes, tasks, and trigger placements to expose agents to trigger variability, and (2) introducing a two-stage training scheme that first applies supervised fine-tuning (SFT) and then our novel Contrastive Trigger Learning (CTL). CTL formulates trigger discrimination as preference learning between trigger-present and trigger-free inputs, explicitly sharpening the decision boundaries to ensure precise backdoor activation. Across various embodied agent benchmarks and MLLMs, BEAT achieves attack success rates up to 80%, while maintaining strong benign task performance, and generalizes reliably to out-of-distribution trigger placements. Notably, compared to naive SFT, CTL boosts backdoor activation accuracy up to 39% under limited backdoor data. These findings expose a critical yet unexplored security risk in MLLM-based embodied agents, underscoring the need for robust defenses before real-world deployment.
DRAMA: Unifying Data Retrieval and Analysis for Open-Domain Analytic Queries
Oct 31, 2025Manually conducting real-world data analyses is labor-intensive and inefficient. Despite numerous attempts to automate data science workflows, none of the existing paradigms or systems fully demonstrate all three key capabilities required to support them effectively: (1) open-domain data collection, (2) structured data transformation, and (3) analytic reasoning. To overcome these limitations, we propose DRAMA, an end-to-end paradigm that answers users' analytic queries in natural language on large-scale open-domain data. DRAMA unifies data collection, transformation, and analysis as a single pipeline. To quantitatively evaluate system performance on tasks representative of DRAMA, we construct a benchmark, DRAMA-Bench, consisting of two categories of tasks: claim verification and question answering, each comprising 100 instances. These tasks are derived from real-world applications that have gained significant public attention and require the retrieval and analysis of open-domain data. We develop DRAMA-Bot, a multi-agent system designed following DRAMA. It comprises a data retriever that collects and transforms data by coordinating the execution of sub-agents, and a data analyzer that performs structured reasoning over the retrieved data. We evaluate DRAMA-Bot on DRAMA-Bench together with five state-of-the-art baseline agents. DRAMA-Bot achieves 86.5% task accuracy at a cost of $0.05, outperforming all baselines with up to 6.9 times the accuracy and less than 1/6 of the cost. DRAMA is publicly available at https://github.com/uiuc-kang-lab/drama.
ZKTorch: Compiling ML Inference to Zero-Knowledge Proofs via Parallel Proof Accumulation
Jul 09, 2025
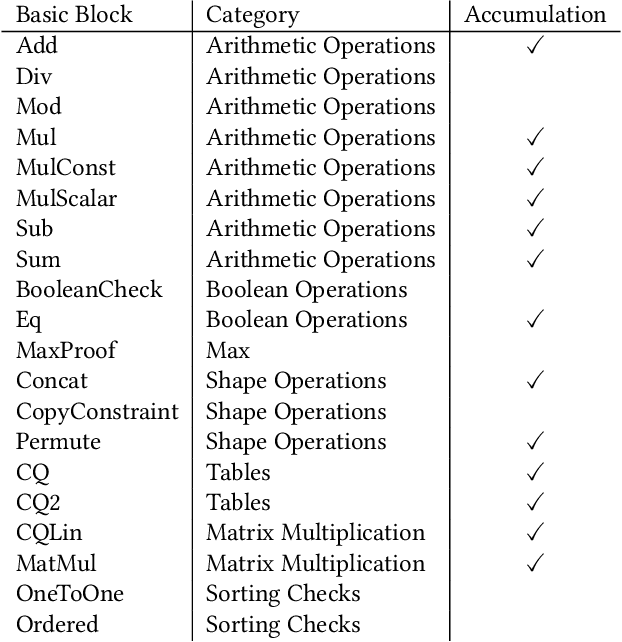


As AI models become ubiquitous in our daily lives, there has been an increasing demand for transparency in ML services. However, the model owner does not want to reveal the weights, as they are considered trade secrets. To solve this problem, researchers have turned to zero-knowledge proofs of ML model inference. These proofs convince the user that the ML model output is correct, without revealing the weights of the model to the user. Past work on these provers can be placed into two categories. The first method compiles the ML model into a low-level circuit, and proves the circuit using a ZK-SNARK. The second method uses custom cryptographic protocols designed only for a specific class of models. Unfortunately, the first method is highly inefficient, making it impractical for the large models used today, and the second method does not generalize well, making it difficult to update in the rapidly changing field of machine learning. To solve this, we propose ZKTorch, an open source end-to-end proving system that compiles ML models into base cryptographic operations called basic blocks, each proved using specialized protocols. ZKTorch is built on top of a novel parallel extension to the Mira accumulation scheme, enabling succinct proofs with minimal accumulation overhead. These contributions allow ZKTorch to achieve at least a $3\times$ reduction in the proof size compared to specialized protocols and up to a $6\times$ speedup in proving time over a general-purpose ZKML framework.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025



Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.