 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Research for Databases
Apr 08, 2026As the complexity of modern workloads and hardware increasingly outpaces human research and engineering capacity, existing methods for database performance optimization struggle to keep pace. To address this gap, a new class of techniques, termed AI-Driven Research for Systems (ADRS), uses large language models to automate solution discovery. This approach shifts optimization from manual system design to automated code generation. The key obstacle, however, in applying ADRS is the evaluation pipeline. Since these frameworks rapidly generate hundreds of candidates without human supervision, they depend on fast and accurate feedback from evaluators to converge on effective solutions. Building such evaluators is especially difficult for complex database systems. To enable the practical application of ADRS in this domain, we propose automating the design of evaluators by co-evolving them with the solutions. We demonstrate the effectiveness of this approach through three case studies optimizing buffer management, query rewriting, and index selection. Our automated evaluators enable the discovery of novel algorithms that outperform state-of-the-art baselines (e.g., a deterministic query rewrite policy that achieves up to 6.8x lower latency), demonstrating that addressing the evaluation bottleneck unlocks the potential of ADRS to generate highly optimized, deployable code for next-generation data systems.
Optimizing Model Selection for Compound AI Systems
Feb 20, 2025Compound AI systems that combine multiple LLM calls, such as self-refine and multi-agent-debate, achieve strong performance on many AI tasks. We address a core question in optimizing compound systems: for each LLM call or module in the system, how should one decide which LLM to use? We show that these LLM choices have a large effect on quality, but the search space is exponential. We propose LLMSelector, an efficient framework for model selection in compound systems, which leverages two key empirical insights: (i) end-to-end performance is often monotonic in how well each module performs, with all other modules held fixed, and (ii) per-module performance can be estimated accurately by an LLM. Building upon these insights, LLMSelector iteratively selects one module and allocates to it the model with the highest module-wise performance, as estimated by an LLM, until no further gain is possible. LLMSelector is applicable to any compound system with a bounded number of modules, and its number of API calls scales linearly with the number of modules, achieving high-quality model allocation both empirically and theoretically. Experiments with popular compound systems such as multi-agent debate and self-refine using LLMs such as GPT-4o, Claude 3.5 Sonnet and Gemini 1.5 show that LLMSelector confers 5%-70% accuracy gains compared to using the same LLM for all modules.
Networks of Networks: Complexity Class Principles Applied to Compound AI Systems Design
Jul 23, 2024



As practitioners seek to surpass the current reliability and quality frontier of monolithic models, Compound AI Systems consisting of many language model inference calls are increasingly employed. In this work, we construct systems, which we call Networks of Networks (NoNs) organized around the distinction between generating a proposed answer and verifying its correctness, a fundamental concept in complexity theory that we show empirically extends to Language Models (LMs). We introduce a verifier-based judge NoN with K generators, an instantiation of "best-of-K" or "judge-based" compound AI systems. Through experiments on synthetic tasks such as prime factorization, and core benchmarks such as the MMLU, we demonstrate notable performance gains. For instance, in factoring products of two 3-digit primes, a simple NoN improves accuracy from 3.7\% to 36.6\%. On MMLU, a verifier-based judge construction with only 3 generators boosts accuracy over individual GPT-4-Turbo calls by 2.8\%. Our analysis reveals that these gains are most pronounced in domains where verification is notably easier than generation--a characterization which we believe subsumes many reasoning and procedural knowledge tasks, but doesn't often hold for factual and declarative knowledge-based settings. For mathematical and formal logic reasoning-based subjects of MMLU, we observe a 5-8\% or higher gain, whilst no gain on others such as geography and religion. We provide key takeaways for ML practitioners, including the importance of considering verification complexity, the impact of witness format on verifiability, and a simple test to determine the potential benefit of this NoN approach for a given problem distribution. This work aims to inform future research and practice in the design of compound AI systems.
Are More LLM Calls All You Need? Towards Scaling Laws of Compound Inference Systems
Mar 04, 2024



Many recent state-of-the-art results in language tasks were achieved using compound systems that perform multiple Large Language Model (LLM) calls and aggregate their responses. However, there is little understanding of how the number of LLM calls -- e.g., when asking the LLM to answer each question multiple times and taking a consensus -- affects such a compound system's performance. In this paper, we initiate the study of scaling laws of compound inference systems. We analyze, theoretically and empirically, how the number of LLM calls affects the performance of one-layer Voting Inference Systems -- one of the simplest compound systems, which aggregates LLM responses via majority voting. We find empirically that across multiple language tasks, surprisingly, Voting Inference Systems' performance first increases but then decreases as a function of the number of LLM calls. Our theoretical results suggest that this non-monotonicity is due to the diversity of query difficulties within a task: more LLM calls lead to higher performance on "easy" queries, but lower performance on "hard" queries, and non-monotone behavior emerges when a task contains both types of queries. This insight then allows us to compute, from a small number of samples, the number of LLM calls that maximizes system performance, and define a scaling law of Voting Inference Systems. Experiments show that our scaling law can predict the performance of Voting Inference Systems and find the optimal number of LLM calls to make.
Break the Sequential Dependency of LLM Inference Using Lookahead Decoding
Feb 03, 2024Autoregressive decoding of large language models (LLMs) is memory bandwidth bounded, resulting in high latency and significant wastes of the parallel processing power of modern accelerators. Existing methods for accelerating LLM decoding often require a draft model (e.g., speculative decoding), which is nontrivial to obtain and unable to generalize. In this paper, we introduce Lookahead decoding, an exact, parallel decoding algorithm that accelerates LLM decoding without needing auxiliary models or data stores. It allows trading per-step log(FLOPs) to reduce the number of total decoding steps, is more parallelizable on single or multiple modern accelerators, and is compatible with concurrent memory-efficient attention (e.g., FlashAttention). Our implementation of Lookahead decoding can speed up autoregressive decoding by up to 1.8x on MT-bench and 4x with strong scaling on multiple GPUs in code completion tasks. Our code is avialable at https://github.com/hao-ai-lab/LookaheadDecoding
Online Speculative Decoding
Oct 17, 2023



Speculative decoding is a pivotal technique to accelerate the inference of large language models (LLMs) by employing a smaller draft model to predict the target model's outputs. However, its efficacy can be limited due to the low predictive accuracy of the draft model, particularly when faced with diverse text inputs and a significant capability gap between the draft and target models. We introduce online speculative decoding (OSD) to address this challenge. The main idea is to continually update (multiple) draft model(s) on observed user query data using the abundant excess computational power in an LLM serving cluster. Given that LLM inference is memory-bounded, the surplus computational power in a typical LLM serving cluster can be repurposed for online retraining of draft models, thereby making the training cost-neutral. Since the query distribution of an LLM service is relatively simple, retraining on query distribution enables the draft model to more accurately predict the target model's outputs, particularly on data originating from query distributions. As the draft model evolves online, it aligns with the query distribution in real time, mitigating distribution shifts. We develop a prototype of online speculative decoding based on online knowledge distillation and evaluate it using both synthetic and real query data on several popular LLMs. The results show a substantial increase in the token acceptance rate by 0.1 to 0.65, which translates into 1.22x to 3.06x latency reduction.
Proof: Accelerating Approximate Aggregation Queries with Expensive Predicates
Jul 28, 2021
Given a dataset $\mathcal{D}$, we are interested in computing the mean of a subset of $\mathcal{D}$ which matches a predicate. ABae leverages stratified sampling and proxy models to efficiently compute this statistic given a sampling budget $N$. In this document, we theoretically analyze ABae and show that the MSE of the estimate decays at rate $O(N_1^{-1} + N_2^{-1} + N_1^{1/2}N_2^{-3/2})$, where $N=K \cdot N_1+N_2$ for some integer constant $K$ and $K \cdot N_1$ and $N_2$ represent the number of samples used in Stage 1 and Stage 2 of ABae respectively. Hence, if a constant fraction of the total sample budget $N$ is allocated to each stage, we will achieve a mean squared error of $O(N^{-1})$ which matches the rate of mean squared error of the optimal stratified sampling algorithm given a priori knowledge of the predicate positive rate and standard deviation per stratum.
Sinkhorn Label Allocation: Semi-Supervised Classification via Annealed Self-Training
Feb 17, 2021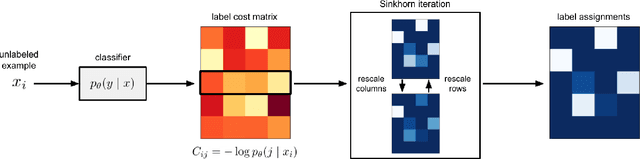

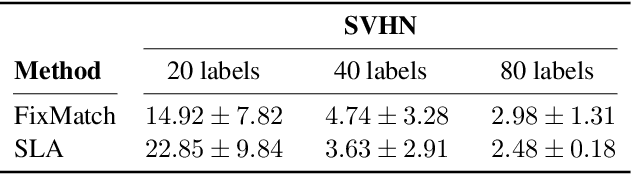
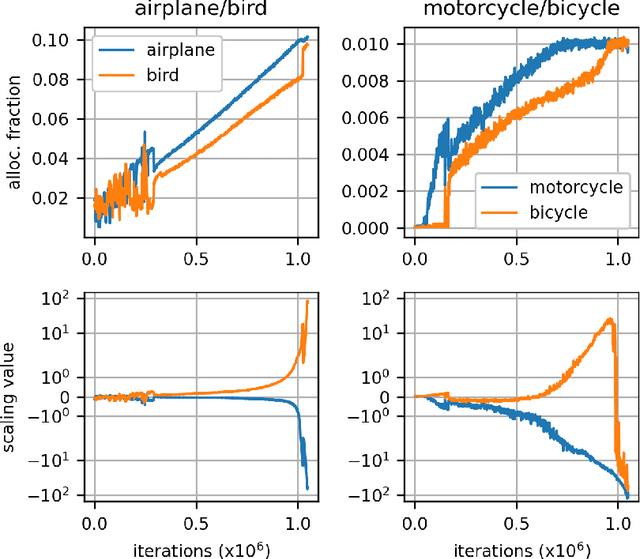
Self-training is a standard approach to semi-supervised learning where the learner's own predictions on unlabeled data are used as supervision during training. In this paper, we reinterpret this label assignment process as an optimal transportation problem between examples and classes, wherein the cost of assigning an example to a class is mediated by the current predictions of the classifier. This formulation facilitates a practical annealing strategy for label assignment and allows for the inclusion of prior knowledge on class proportions via flexible upper bound constraints. The solutions to these assignment problems can be efficiently approximated using Sinkhorn iteration, thus enabling their use in the inner loop of standard stochastic optimization algorithms. We demonstrate the effectiveness of our algorithm on the CIFAR-10, CIFAR-100, and SVHN datasets in comparison with FixMatch, a state-of-the-art self-training algorithm. Additionally, we elucidate connections between our proposed algorithm and existing confidence thresholded self-training approaches in the context of homotopy methods in optimization. Our code is available at https://github.com/stanford-futuredata/sinkhorn-label-allocation.
Leveraging Organizational Resources to Adapt Models to New Data Modalities
Aug 23, 2020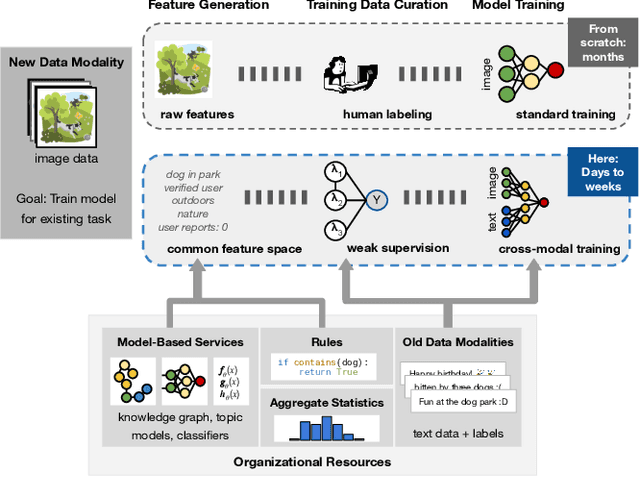

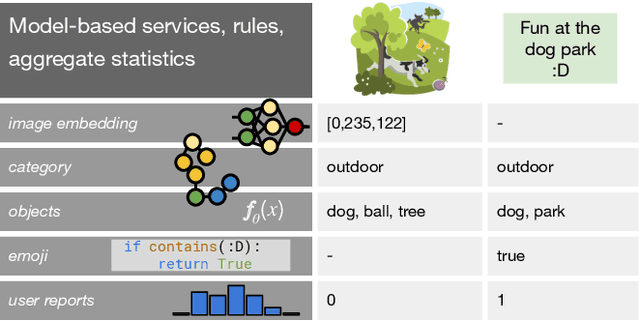
As applications in large organizations evolve, the machine learning (ML) models that power them must adapt the same predictive tasks to newly arising data modalities (e.g., a new video content launch in a social media application requires existing text or image models to extend to video). To solve this problem, organizations typically create ML pipelines from scratch. However, this fails to utilize the domain expertise and data they have cultivated from developing tasks for existing modalities. We demonstrate how organizational resources, in the form of aggregate statistics, knowledge bases, and existing services that operate over related tasks, enable teams to construct a common feature space that connects new and existing data modalities. This allows teams to apply methods for training data curation (e.g., weak supervision and label propagation) and model training (e.g., forms of multi-modal learning) across these different data modalities. We study how this use of organizational resources composes at production scale in over 5 classification tasks at Google, and demonstrate how it reduces the time needed to develop models for new modalities from months to weeks to days.
Jointly Optimizing Preprocessing and Inference for DNN-based Visual Analytics
Jul 25, 2020
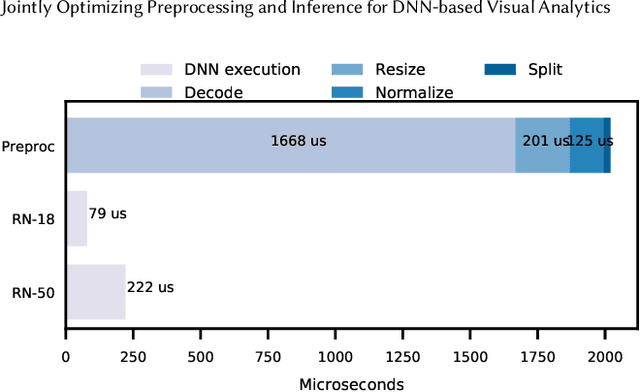


While deep neural networks (DNNs) are an increasingly popular way to query large corpora of data, their significant runtime remains an active area of research. As a result, researchers have proposed systems and optimizations to reduce these costs by allowing users to trade off accuracy and speed. In this work, we examine end-to-end DNN execution in visual analytics systems on modern accelerators. Through a novel measurement study, we show that the preprocessing of data (e.g., decoding, resizing) can be the bottleneck in many visual analytics systems on modern hardware. To address the bottleneck of preprocessing, we introduce two optimizations for end-to-end visual analytics systems. First, we introduce novel methods of achieving accuracy and throughput trade-offs by using natively present, low-resolution visual data. Second, we develop a runtime engine for efficient visual DNN inference. This runtime engine a) efficiently pipelines preprocessing and DNN execution for inference, b) places preprocessing operations on the CPU or GPU in a hardware- and input-aware manner, and c) efficiently manages memory and threading for high throughput execution. We implement these optimizations in a novel system, Smol, and evaluate Smol on eight visual datasets. We show that its optimizations can achieve up to 5.9x end-to-end throughput improvements at a fixed accuracy over recent work in visual analytics.