 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMecha-nudges for Machines
Mar 24, 2026Nudges are subtle changes to the way choices are presented to human decision-makers (e.g., opt-in vs. opt-out by default) that shift behavior without restricting options or changing incentives. As AI agents increasingly make decisions in the same environments as humans, the presentation of choices may be optimized for machines as well as people. We introduce mecha-nudges: changes to how choices are presented that systematically influence AI agents without degrading the decision environment for humans. To formalize mecha-nudges, we combine the Bayesian persuasion framework with V-usable information, a generalization of Shannon information that is observer-relative. This yields a common scale (bits of usable information) for comparing a wide range of interventions, contexts, and models. Applying our framework to product listings on Etsy -- a global marketplace for independent sellers -- we find that following ChatGPT's release, listings have significantly more machine-usable information about product selection, consistent with systematic mecha-nudging.
Data Checklist: On Unit-Testing Datasets with Usable Information
Aug 06, 2024



Model checklists (Ribeiro et al., 2020) have emerged as a useful tool for understanding the behavior of LLMs, analogous to unit-testing in software engineering. However, despite datasets being a key determinant of model behavior, evaluating datasets, e.g., for the existence of annotation artifacts, is largely done ad hoc, once a problem in model behavior has already been found downstream. In this work, we take a more principled approach to unit-testing datasets by proposing a taxonomy based on the V-information literature. We call a collection of such unit tests a data checklist. Using a checklist, not only are we able to recover known artifacts in well-known datasets such as SNLI, but we also discover previously unknown artifacts in preference datasets for LLM alignment. Data checklists further enable a new kind of data filtering, which we use to improve the efficacy and data efficiency of preference alignment.
KTO: Model Alignment as Prospect Theoretic Optimization
Feb 02, 2024



Kahneman & Tversky's $\textit{prospect theory}$ tells us that humans perceive random variables in a biased but well-defined manner; for example, humans are famously loss-averse. We show that objectives for aligning LLMs with human feedback implicitly incorporate many of these biases -- the success of these objectives (e.g., DPO) over cross-entropy minimization can partly be ascribed to them being $\textit{human-aware loss functions}$ (HALOs). However, the utility functions these methods attribute to humans still differ from those in the prospect theory literature. Using a Kahneman-Tversky model of human utility, we propose a HALO that directly maximizes the utility of generations instead of maximizing the log-likelihood of preferences, as current methods do. We call this approach Kahneman-Tversky Optimization (KTO), and it matches or exceeds the performance of preference-based methods at scales from 1B to 30B. Crucially, KTO does not need preferences -- only a binary signal of whether an output is desirable or undesirable for a given input. This makes it far easier to use in the real world, where preference data is scarce and expensive.
Anchor Points: Benchmarking Models with Much Fewer Examples
Sep 14, 2023



Modern language models often exhibit powerful but brittle behavior, leading to the development of larger and more diverse benchmarks to reliably assess their behavior. Here, we suggest that model performance can be benchmarked and elucidated with much smaller evaluation sets. We first show that in six popular language classification benchmarks, model confidence in the correct class on many pairs of points is strongly correlated across models. We build upon this phenomenon to propose Anchor Point Selection, a technique to select small subsets of datasets that capture model behavior across the entire dataset. Anchor points reliably rank models: across 87 diverse language model-prompt pairs, evaluating models using 1-30 anchor points outperforms uniform sampling and other baselines at accurately ranking models. Moreover, just several anchor points can be used to estimate model per-class predictions on all other points in a dataset with low mean absolute error, sufficient for gauging where the model is likely to fail. Lastly, we present Anchor Point Maps for visualizing these insights and facilitating comparisons of the performance of different models on various regions within the dataset distribution.
How Human is Human Evaluation? Improving the Gold Standard for NLG with Utility Theory
May 24, 2022
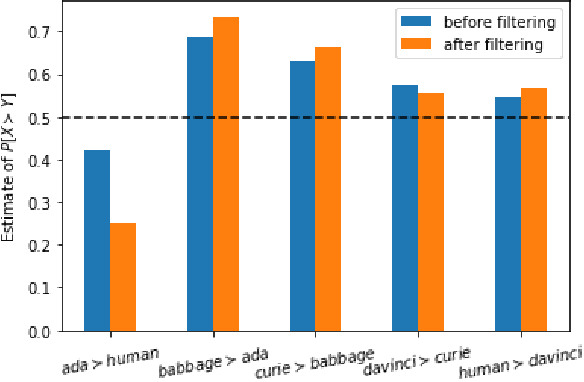

Human ratings are treated as the gold standard in NLG evaluation. The standard protocol is to collect ratings of generated text, average across annotators, and then rank NLG systems by their average scores. However, little consideration has been given as to whether this approach faithfully captures human preferences. In this work, we analyze this standard protocol through the lens of utility theory in economics. We first identify the implicit assumptions it makes about annotators and find that these assumptions are often violated in practice, in which case annotator ratings become an unfaithful reflection of their preferences. The most egregious violations come from using Likert scales, which provably reverse the direction of the true preference in certain cases. We suggest improvements to the standard protocol to make it more theoretically sound, but even in its improved form, it cannot be used to evaluate open-ended tasks like story generation. For the latter, we propose a new evaluation protocol called $\textit{system-level probabilistic assessment}$ (SPA). In our experiments, we find that according to SPA, annotators prefer larger GPT-3 variants to smaller ones -- as expected -- with all comparisons being statistically significant. In contrast, the standard protocol only yields significant results half the time.
Richer Countries and Richer Representations
May 10, 2022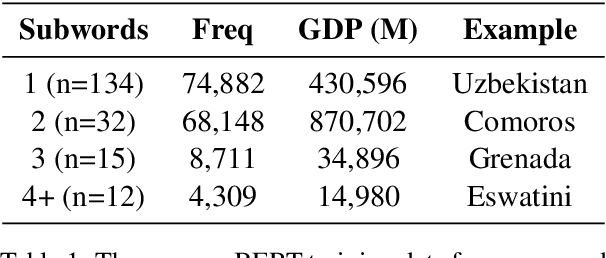
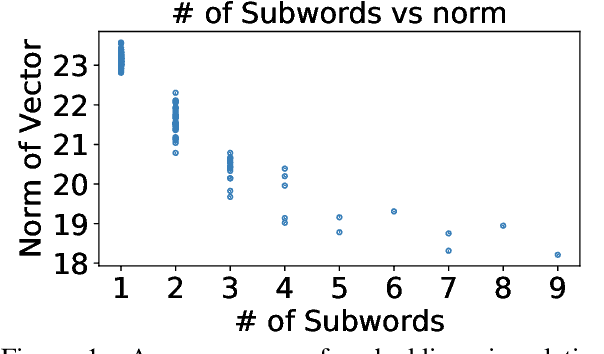
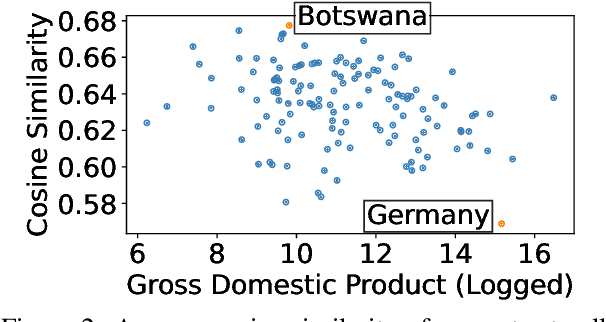
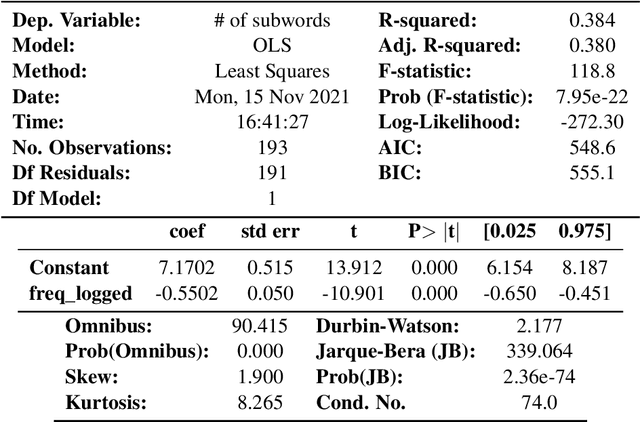
We examine whether some countries are more richly represented in embedding space than others. We find that countries whose names occur with low frequency in training corpora are more likely to be tokenized into subwords, are less semantically distinct in embedding space, and are less likely to be correctly predicted: e.g., Ghana (the correct answer and in-vocabulary) is not predicted for, "The country producing the most cocoa is [MASK].". Although these performance discrepancies and representational harms are due to frequency, we find that frequency is highly correlated with a country's GDP; thus perpetuating historic power and wealth inequalities. We analyze the effectiveness of mitigation strategies; recommend that researchers report training word frequencies; and recommend future work for the community to define and design representational guarantees.
Problems with Cosine as a Measure of Embedding Similarity for High Frequency Words
May 10, 2022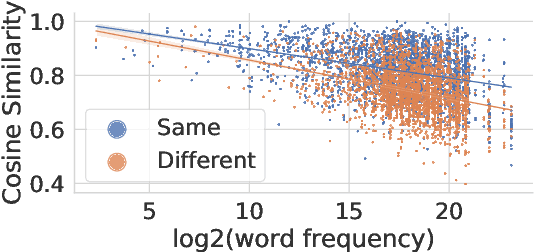
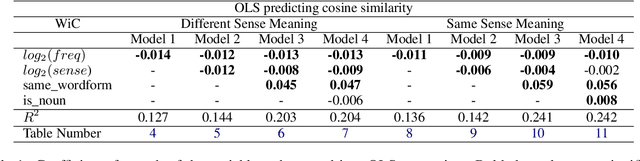
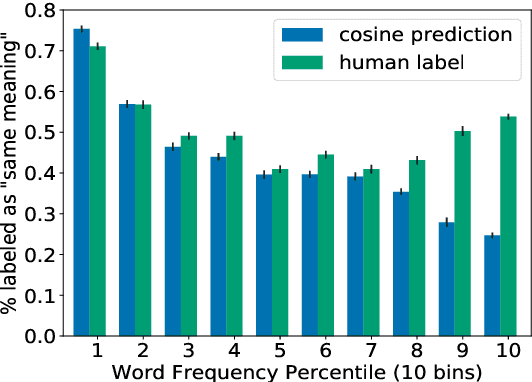

Cosine similarity of contextual embeddings is used in many NLP tasks (e.g., QA, IR, MT) and metrics (e.g., BERTScore). Here, we uncover systematic ways in which word similarities estimated by cosine over BERT embeddings are understated and trace this effect to training data frequency. We find that relative to human judgements, cosine similarity underestimates the similarity of frequent words with other instances of the same word or other words across contexts, even after controlling for polysemy and other factors. We conjecture that this underestimation of similarity for high frequency words is due to differences in the representational geometry of high and low frequency words and provide a formal argument for the two-dimensional case.
Information-Theoretic Measures of Dataset Difficulty
Oct 16, 2021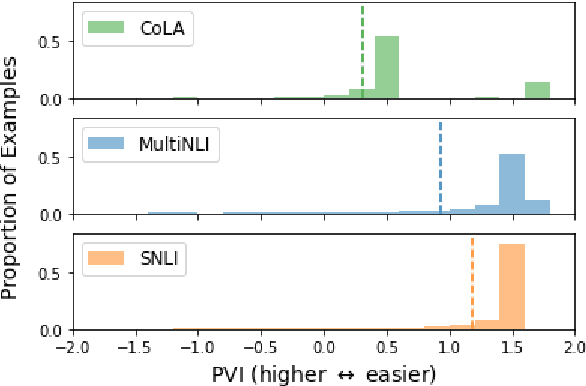
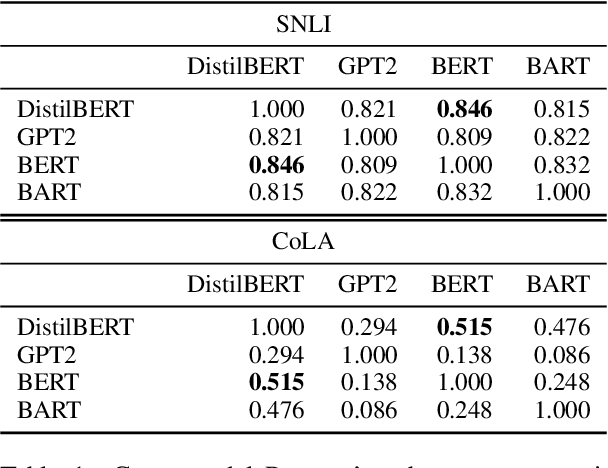
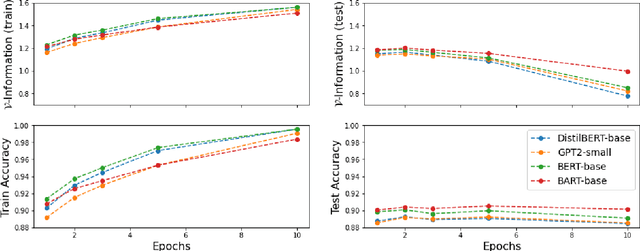
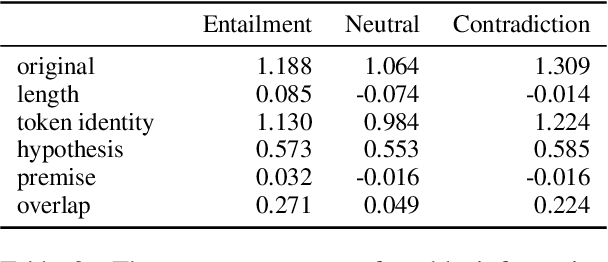
Estimating the difficulty of a dataset typically involves comparing state-of-the-art models to humans; the bigger the performance gap, the harder the dataset is said to be. Not only is this framework informal, but it also provides little understanding of how difficult each instance is, or what attributes make it difficult for a given model. To address these problems, we propose an information-theoretic perspective, framing dataset difficulty as the absence of $\textit{usable information}$. Measuring usable information is as easy as measuring performance, but has certain theoretical advantages. While the latter only allows us to compare different models w.r.t the same dataset, the former also allows us to compare different datasets w.r.t the same model. We then introduce $\textit{pointwise}$ $\mathcal{V}-$$\textit{information}$ (PVI) for measuring the difficulty of individual instances, where instances with higher PVI are easier for model $\mathcal{V}$. By manipulating the input before measuring usable information, we can understand $\textit{why}$ a dataset is easy or difficult for a given model, which we use to discover annotation artefacts in widely-used benchmarks.
Conditional probing: measuring usable information beyond a baseline
Sep 19, 2021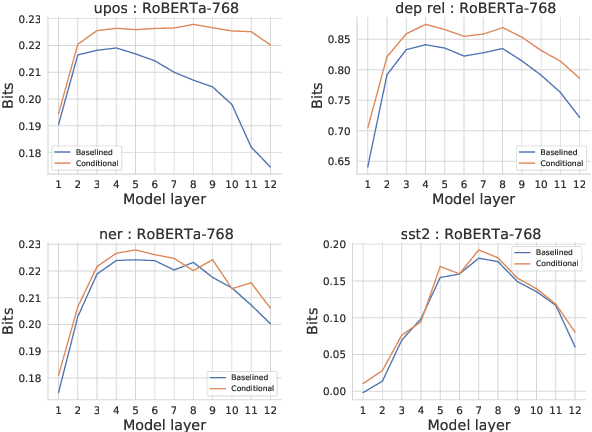
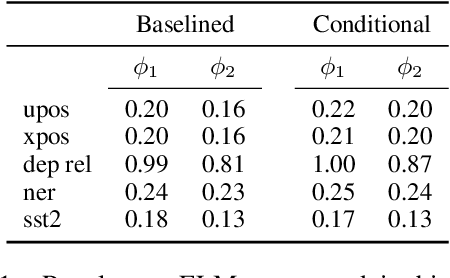
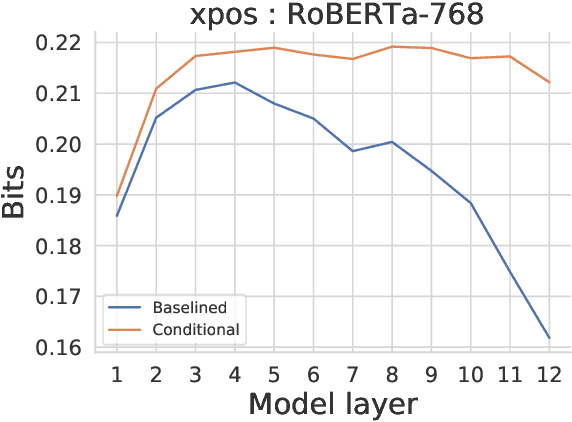
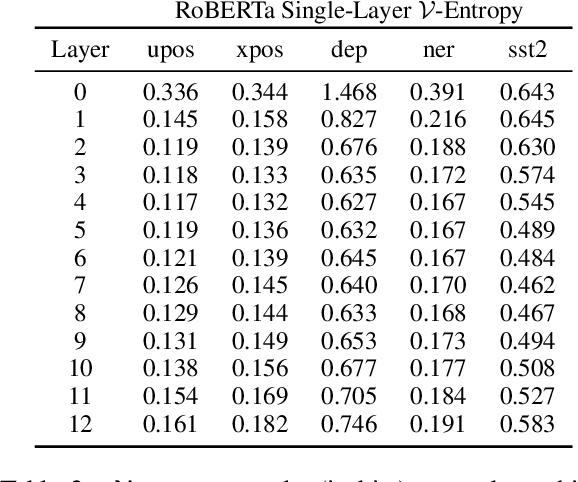
Probing experiments investigate the extent to which neural representations make properties -- like part-of-speech -- predictable. One suggests that a representation encodes a property if probing that representation produces higher accuracy than probing a baseline representation like non-contextual word embeddings. Instead of using baselines as a point of comparison, we're interested in measuring information that is contained in the representation but not in the baseline. For example, current methods can detect when a representation is more useful than the word identity (a baseline) for predicting part-of-speech; however, they cannot detect when the representation is predictive of just the aspects of part-of-speech not explainable by the word identity. In this work, we extend a theory of usable information called $\mathcal{V}$-information and propose conditional probing, which explicitly conditions on the information in the baseline. In a case study, we find that after conditioning on non-contextual word embeddings, properties like part-of-speech are accessible at deeper layers of a network than previously thought.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.