 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Prediction: Tail-Aware Scheduling for LLM Inference
Jun 16, 2026LLM serving exhibits extreme length variability, making size-based scheduling difficult in practice. Recent LLM schedulers approximate SJF/SRPT using predicted decode lengths or ranks and primarily report mean-centric metrics such as TTFT and TBT. We show that these prediction-driven policies can be fragile under distribution shifts, bursty arrivals, and GPU memory pressure, while offering limited control over the tail latency (P90-P99) that dominates user experience, even with perfect decode-length knowledge. We introduce a distribution-aware, prediction-free scheduling framework that replaces explicit length prediction with soft priority boosting driven by lightweight statistical signals. Our design co-optimizes scheduling and cache-aware preemption to account for memory-coupled decode dynamics across workload mixes. Evaluated on production and open-source traces, our method reduces P99 TTLT by up to 35-50% relative to SRPT with perfect length knowledge and reduces TTFT by 34-47% across workloads, including reasoning-heavy and chat-heavy tasks. These results demonstrate a robust alternative for optimizing tail latency in online LLM serving.
Accelerating Diffusion Language Model Inference via Efficient KV Caching and Guided Diffusion
May 27, 2025



Diffusion language models offer parallel token generation and inherent bidirectionality, promising more efficient and powerful sequence modeling compared to autoregressive approaches. However, state-of-the-art diffusion models (e.g., Dream 7B, LLaDA 8B) suffer from slow inference. While they match the quality of similarly sized Autoregressive (AR) Models (e.g., Qwen2.5 7B, Llama3 8B), their iterative denoising requires multiple full-sequence forward passes, resulting in high computational costs and latency, particularly for long input prompts and long-context scenarios. Furthermore, parallel token generation introduces token incoherence problems, and current sampling heuristics suffer from significant quality drops with decreasing denoising steps. We address these limitations with two training-free techniques. First, we propose FreeCache, a Key-Value (KV) approximation caching technique that reuses stable KV projections across denoising steps, effectively reducing the computational cost of DLM inference. Second, we introduce Guided Diffusion, a training-free method that uses a lightweight pretrained autoregressive model to supervise token unmasking, dramatically reducing the total number of denoising iterations without sacrificing quality. We conduct extensive evaluations on open-source reasoning benchmarks, and our combined methods deliver up to a 34x end-to-end speedup without compromising accuracy. For the first time, diffusion language models achieve a comparable and even faster latency as the widely adopted autoregressive models. Our work successfully paved the way for scaling up the diffusion language model to a broader scope of applications across different domains.
Carbon Connect: An Ecosystem for Sustainable Computing
May 22, 2024



Computing is at a moment of profound opportunity. Emerging applications -- such as capable artificial intelligence, immersive virtual realities, and pervasive sensor systems -- drive unprecedented demand for computer. Despite recent advances toward net zero carbon emissions, the computing industry's gross energy usage continues to rise at an alarming rate, outpacing the growth of new energy installations and renewable energy deployments. A shift towards sustainability is needed to spark a transformation in how computer systems are manufactured, allocated, and consumed. Carbon Connect envisions coordinated research thrusts that produce design and management strategies for sustainable, next-generation computer systems. These strategies must flatten and then reverse growth trajectories for computing power and carbon for society's most rapidly growing applications such as artificial intelligence and virtual spaces. We will require accurate models for carbon accounting in computing technology. For embodied carbon, we must re-think conventional design strategies -- over-provisioned monolithic servers, frequent hardware refresh cycles, custom silicon -- and adopt life-cycle design strategies that more effectively reduce, reuse and recycle hardware at scale. For operational carbon, we must not only embrace renewable energy but also design systems to use that energy more efficiently. Finally, new hardware design and management strategies must be cognizant of economic policy and regulatory landscape, aligning private initiatives with societal goals. Many of these broader goals will require computer scientists to develop deep, enduring collaborations with researchers in economics, law, and industrial ecology to spark change in broader practice.
Photonics for Sustainable Computing
Jan 10, 2024Photonic integrated circuits are finding use in a variety of applications including optical transceivers, LIDAR, bio-sensing, photonic quantum computing, and Machine Learning (ML). In particular, with the exponentially increasing sizes of ML models, photonics-based accelerators are getting special attention as a sustainable solution because they can perform ML inferences with multiple orders of magnitude higher energy efficiency than CMOS-based accelerators. However, recent studies have shown that hardware manufacturing and infrastructure contribute significantly to the carbon footprint of computing devices, even surpassing the emissions generated during their use. For example, the manufacturing process accounts for 74% of the total carbon emissions from Apple in 2019. This prompts us to ask -- if we consider both the embodied (manufacturing) and operational carbon cost of photonics, is it indeed a viable avenue for a sustainable future? So, in this paper, we build a carbon footprint model for photonic chips and investigate the sustainability of photonics-based accelerators by conducting a case study on ADEPT, a photonics-based accelerator for deep neural network inference. Our analysis shows that photonics can reduce both operational and embodied carbon footprints with its high energy efficiency and at least 4$\times$ less fabrication carbon cost per unit area than 28 nm CMOS.
GPT-InvestAR: Enhancing Stock Investment Strategies through Annual Report Analysis with Large Language Models
Sep 06, 2023



Annual Reports of publicly listed companies contain vital information about their financial health which can help assess the potential impact on Stock price of the firm. These reports are comprehensive in nature, going up to, and sometimes exceeding, 100 pages. Analysing these reports is cumbersome even for a single firm, let alone the whole universe of firms that exist. Over the years, financial experts have become proficient in extracting valuable information from these documents relatively quickly. However, this requires years of practice and experience. This paper aims to simplify the process of assessing Annual Reports of all the firms by leveraging the capabilities of Large Language Models (LLMs). The insights generated by the LLM are compiled in a Quant styled dataset and augmented by historical stock price data. A Machine Learning model is then trained with LLM outputs as features. The walkforward test results show promising outperformance wrt S&P500 returns. This paper intends to provide a framework for future work in this direction. To facilitate this, the code has been released as open source.
Information Flow Control in Machine Learning through Modular Model Architecture
Jun 05, 2023



In today's machine learning (ML) models, any part of the training data can affect its output. This lack of control for information flow from training data to model output is a major obstacle in training models on sensitive data when access control only allows individual users to access a subset of data. To enable secure machine learning for access controlled data, we propose the notion of information flow control for machine learning, and develop a secure Transformer-based language model based on the Mixture-of-Experts (MoE) architecture. The secure MoE architecture controls information flow by limiting the influence of training data from each security domain to a single expert module, and only enabling a subset of experts at inference time based on an access control policy. The evaluation using a large corpus of text data shows that the proposed MoE architecture has minimal (1.9%) performance overhead and can significantly improve model accuracy (up to 37%) by enabling training on access-controlled data.
MP-Rec: Hardware-Software Co-Design to Enable Multi-Path Recommendation
Feb 21, 2023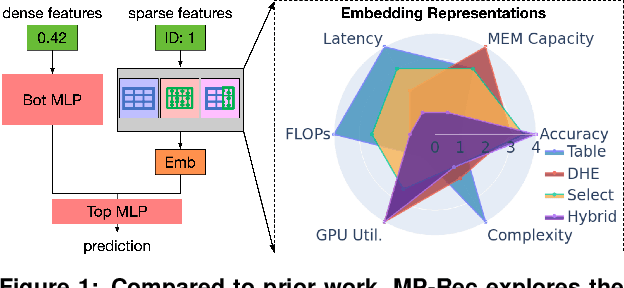

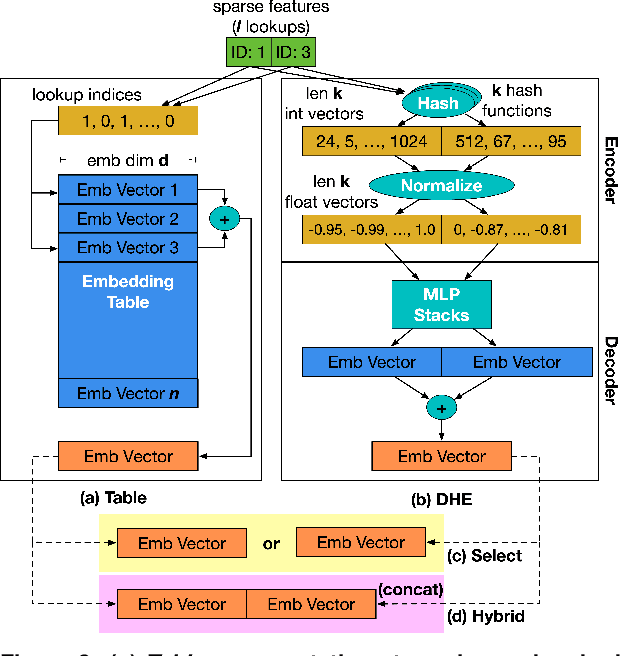
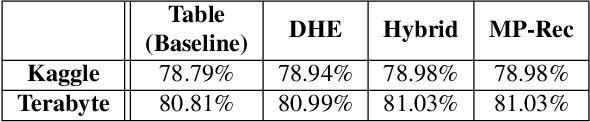
Deep learning recommendation systems serve personalized content under diverse tail-latency targets and input-query loads. In order to do so, state-of-the-art recommendation models rely on terabyte-scale embedding tables to learn user preferences over large bodies of contents. The reliance on a fixed embedding representation of embedding tables not only imposes significant memory capacity and bandwidth requirements but also limits the scope of compatible system solutions. This paper challenges the assumption of fixed embedding representations by showing how synergies between embedding representations and hardware platforms can lead to improvements in both algorithmic- and system performance. Based on our characterization of various embedding representations, we propose a hybrid embedding representation that achieves higher quality embeddings at the cost of increased memory and compute requirements. To address the system performance challenges of the hybrid representation, we propose MP-Rec -- a co-design technique that exploits heterogeneity and dynamic selection of embedding representations and underlying hardware platforms. On real system hardware, we demonstrate how matching custom accelerators, i.e., GPUs, TPUs, and IPUs, with compatible embedding representations can lead to 16.65x performance speedup. Additionally, in query-serving scenarios, MP-Rec achieves 2.49x and 3.76x higher correct prediction throughput and 0.19% and 0.22% better model quality on a CPU-GPU system for the Kaggle and Terabyte datasets, respectively.
GPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 27, 2023



On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
Sustainable AI: Environmental Implications, Challenges and Opportunities
Oct 30, 2021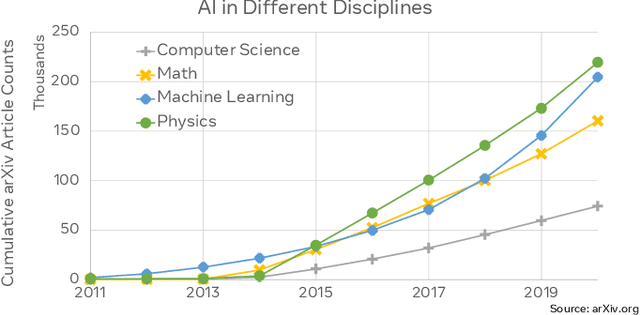
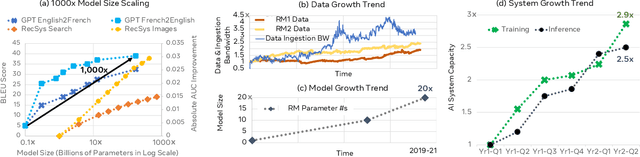
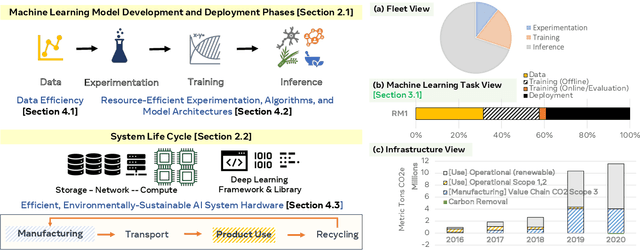
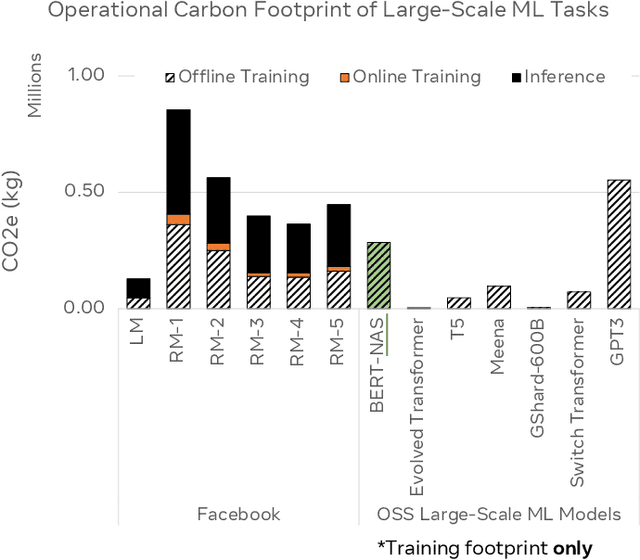
This paper explores the environmental impact of the super-linear growth trends for AI from a holistic perspective, spanning Data, Algorithms, and System Hardware. We characterize the carbon footprint of AI computing by examining the model development cycle across industry-scale machine learning use cases and, at the same time, considering the life cycle of system hardware. Taking a step further, we capture the operational and manufacturing carbon footprint of AI computing and present an end-to-end analysis for what and how hardware-software design and at-scale optimization can help reduce the overall carbon footprint of AI. Based on the industry experience and lessons learned, we share the key challenges and chart out important development directions across the many dimensions of AI. We hope the key messages and insights presented in this paper can inspire the community to advance the field of AI in an environmentally-responsible manner.
RecPipe: Co-designing Models and Hardware to Jointly Optimize Recommendation Quality and Performance
May 22, 2021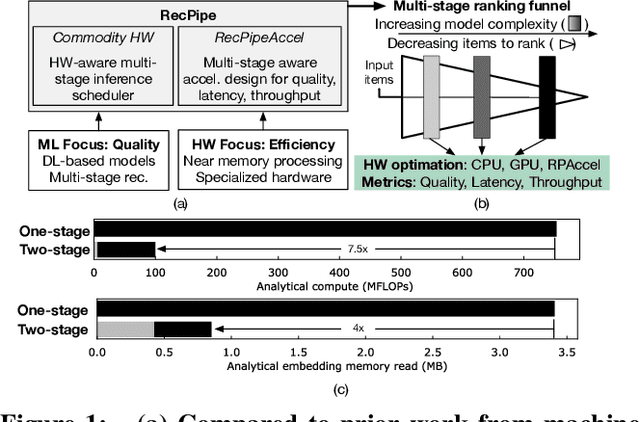

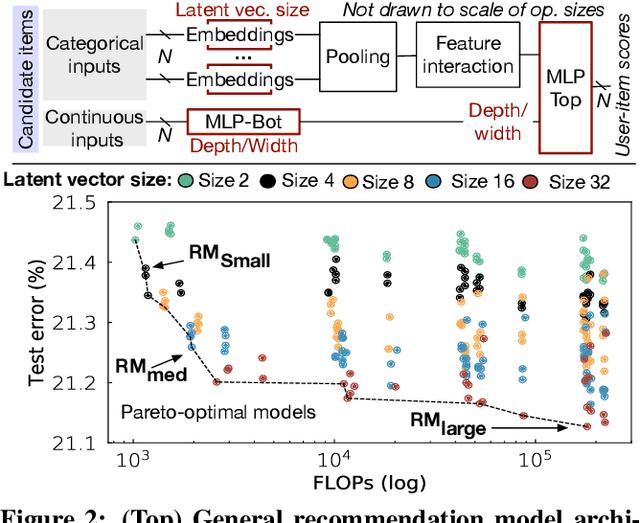
Deep learning recommendation systems must provide high quality, personalized content under strict tail-latency targets and high system loads. This paper presents RecPipe, a system to jointly optimize recommendation quality and inference performance. Central to RecPipe is decomposing recommendation models into multi-stage pipelines to maintain quality while reducing compute complexity and exposing distinct parallelism opportunities. RecPipe implements an inference scheduler to map multi-stage recommendation engines onto commodity, heterogeneous platforms (e.g., CPUs, GPUs).While the hardware-aware scheduling improves ranking efficiency, the commodity platforms suffer from many limitations requiring specialized hardware. Thus, we design RecPipeAccel (RPAccel), a custom accelerator that jointly optimizes quality, tail-latency, and system throughput. RPAc-cel is designed specifically to exploit the distinct design space opened via RecPipe. In particular, RPAccel processes queries in sub-batches to pipeline recommendation stages, implements dual static and dynamic embedding caches, a set of top-k filtering units, and a reconfigurable systolic array. Com-pared to prior-art and at iso-quality, we demonstrate that RPAccel improves latency and throughput by 3x and 6x.