 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-wise Adaptive Integration of Supervised Fine-tuning and Reinforcement Learning for Task-Specific LLMs
May 19, 2025Large language models (LLMs) excel at mathematical reasoning and logical problem-solving. The current popular training paradigms primarily use supervised fine-tuning (SFT) and reinforcement learning (RL) to enhance the models' reasoning abilities. However, when using SFT or RL alone, there are respective challenges: SFT may suffer from overfitting, while RL is prone to mode collapse. The state-of-the-art methods have proposed hybrid training schemes. However, static switching faces challenges such as poor generalization across different tasks and high dependence on data quality. In response to these challenges, inspired by the curriculum learning-quiz mechanism in human reasoning cultivation, We propose SASR, a step-wise adaptive hybrid training framework that theoretically unifies SFT and RL and dynamically balances the two throughout optimization. SASR uses SFT for initial warm-up to establish basic reasoning skills, and then uses an adaptive dynamic adjustment algorithm based on gradient norm and divergence relative to the original distribution to seamlessly integrate SFT with the online RL method GRPO. By monitoring the training status of LLMs and adjusting the training process in sequence, SASR ensures a smooth transition between training schemes, maintaining core reasoning abilities while exploring different paths. Experimental results demonstrate that SASR outperforms SFT, RL, and static hybrid training methods.
Dynamic Graph Induced Contour-aware Heat Conduction Network for Event-based Object Detection
May 19, 2025Event-based Vision Sensors (EVS) have demonstrated significant advantages over traditional RGB frame-based cameras in low-light conditions, high-speed motion capture, and low latency. Consequently, object detection based on EVS has attracted increasing attention from researchers. Current event stream object detection algorithms are typically built upon Convolutional Neural Networks (CNNs) or Transformers, which either capture limited local features using convolutional filters or incur high computational costs due to the utilization of self-attention. Recently proposed vision heat conduction backbone networks have shown a good balance between efficiency and accuracy; however, these models are not specifically designed for event stream data. They exhibit weak capability in modeling object contour information and fail to exploit the benefits of multi-scale features. To address these issues, this paper proposes a novel dynamic graph induced contour-aware heat conduction network for event stream based object detection, termed CvHeat-DET. The proposed model effectively leverages the clear contour information inherent in event streams to predict the thermal diffusivity coefficients within the heat conduction model, and integrates hierarchical structural graph features to enhance feature learning across multiple scales. Extensive experiments on three benchmark datasets for event stream-based object detection fully validated the effectiveness of the proposed model. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvDET.
Towards Low-Latency Event Stream-based Visual Object Tracking: A Slow-Fast Approach
May 19, 2025Existing tracking algorithms typically rely on low-frame-rate RGB cameras coupled with computationally intensive deep neural network architectures to achieve effective tracking. However, such frame-based methods inherently face challenges in achieving low-latency performance and often fail in resource-constrained environments. Visual object tracking using bio-inspired event cameras has emerged as a promising research direction in recent years, offering distinct advantages for low-latency applications. In this paper, we propose a novel Slow-Fast Tracking paradigm that flexibly adapts to different operational requirements, termed SFTrack. The proposed framework supports two complementary modes, i.e., a high-precision slow tracker for scenarios with sufficient computational resources, and an efficient fast tracker tailored for latency-aware, resource-constrained environments. Specifically, our framework first performs graph-based representation learning from high-temporal-resolution event streams, and then integrates the learned graph-structured information into two FlashAttention-based vision backbones, yielding the slow and fast trackers, respectively. The fast tracker achieves low latency through a lightweight network design and by producing multiple bounding box outputs in a single forward pass. Finally, we seamlessly combine both trackers via supervised fine-tuning and further enhance the fast tracker's performance through a knowledge distillation strategy. Extensive experiments on public benchmarks, including FE240, COESOT, and EventVOT, demonstrate the effectiveness and efficiency of our proposed method across different real-world scenarios. The source code has been released on https://github.com/Event-AHU/SlowFast_Event_Track.
SLOT: Sample-specific Language Model Optimization at Test-time
May 18, 2025We propose SLOT (Sample-specific Language Model Optimization at Test-time), a novel and parameter-efficient test-time inference approach that enhances a language model's ability to more accurately respond to individual prompts. Existing Large Language Models (LLMs) often struggle with complex instructions, leading to poor performances on those not well represented among general samples. To address this, SLOT conducts few optimization steps at test-time to update a light-weight sample-specific parameter vector. It is added to the final hidden layer before the output head, and enables efficient adaptation by caching the last layer features during per-sample optimization. By minimizing the cross-entropy loss on the input prompt only, SLOT helps the model better aligned with and follow each given instruction. In experiments, we demonstrate that our method outperforms the compared models across multiple benchmarks and LLMs. For example, Qwen2.5-7B with SLOT achieves an accuracy gain of 8.6% on GSM8K from 57.54% to 66.19%, while DeepSeek-R1-Distill-Llama-70B with SLOT achieves a SOTA accuracy of 68.69% on GPQA among 70B-level models. Our code is available at https://github.com/maple-research-lab/SLOT.
Lightweight Spatio-Temporal Attention Network with Graph Embedding and Rotational Position Encoding for Traffic Forecasting
May 17, 2025


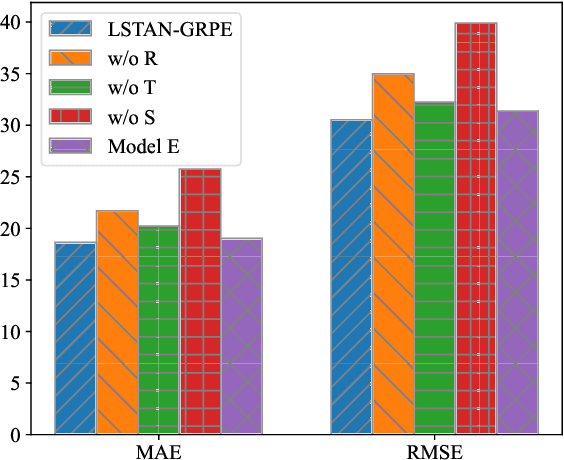
Traffic forecasting is a key task in the field of Intelligent Transportation Systems. Recent research on traffic forecasting has mainly focused on combining graph neural networks (GNNs) with other models. However, GNNs only consider short-range spatial information. In this study, we present a novel model termed LSTAN-GERPE (Lightweight Spatio-Temporal Attention Network with Graph Embedding and Rotational Position Encoding). This model leverages both Temporal and Spatial Attention mechanisms to effectively capture long-range traffic dynamics. Additionally, the optimal frequency for rotational position encoding is determined through a grid search approach in both the spatial and temporal attention mechanisms. This systematic optimization enables the model to effectively capture complex traffic patterns. The model also enhances feature representation by incorporating geographical location maps into the spatio-temporal embeddings. Without extensive feature engineering, the proposed method in this paper achieves advanced accuracy on the real-world traffic forecasting datasets PeMS04 and PeMS08.
Describe Anything in Medical Images
May 09, 2025Localized image captioning has made significant progress with models like the Describe Anything Model (DAM), which can generate detailed region-specific descriptions without explicit region-text supervision. However, such capabilities have yet to be widely applied to specialized domains like medical imaging, where diagnostic interpretation relies on subtle regional findings rather than global understanding. To mitigate this gap, we propose MedDAM, the first comprehensive framework leveraging large vision-language models for region-specific captioning in medical images. MedDAM employs medical expert-designed prompts tailored to specific imaging modalities and establishes a robust evaluation benchmark comprising a customized assessment protocol, data pre-processing pipeline, and specialized QA template library. This benchmark evaluates both MedDAM and other adaptable large vision-language models, focusing on clinical factuality through attribute-level verification tasks, thereby circumventing the absence of ground-truth region-caption pairs in medical datasets. Extensive experiments on the VinDr-CXR, LIDC-IDRI, and SkinCon datasets demonstrate MedDAM's superiority over leading peers (including GPT-4o, Claude 3.7 Sonnet, LLaMA-3.2 Vision, Qwen2.5-VL, GPT-4Rol, and OMG-LLaVA) in the task, revealing the importance of region-level semantic alignment in medical image understanding and establishing MedDAM as a promising foundation for clinical vision-language integration.
ORBIT-2: Scaling Exascale Vision Foundation Models for Weather and Climate Downscaling
May 07, 2025



Sparse observations and coarse-resolution climate models limit effective regional decision-making, underscoring the need for robust downscaling. However, existing AI methods struggle with generalization across variables and geographies and are constrained by the quadratic complexity of Vision Transformer (ViT) self-attention. We introduce ORBIT-2, a scalable foundation model for global, hyper-resolution climate downscaling. ORBIT-2 incorporates two key innovations: (1) Residual Slim ViT (Reslim), a lightweight architecture with residual learning and Bayesian regularization for efficient, robust prediction; and (2) TILES, a tile-wise sequence scaling algorithm that reduces self-attention complexity from quadratic to linear, enabling long-sequence processing and massive parallelism. ORBIT-2 scales to 10 billion parameters across 32,768 GPUs, achieving up to 1.8 ExaFLOPS sustained throughput and 92-98% strong scaling efficiency. It supports downscaling to 0.9 km global resolution and processes sequences up to 4.2 billion tokens. On 7 km resolution benchmarks, ORBIT-2 achieves high accuracy with R^2 scores in the range of 0.98 to 0.99 against observation data.
DeepAndes: A Self-Supervised Vision Foundation Model for Multi-Spectral Remote Sensing Imagery of the Andes
Apr 28, 2025By mapping sites at large scales using remotely sensed data, archaeologists can generate unique insights into long-term demographic trends, inter-regional social networks, and past adaptations to climate change. Remote sensing surveys complement field-based approaches, and their reach can be especially great when combined with deep learning and computer vision techniques. However, conventional supervised deep learning methods face challenges in annotating fine-grained archaeological features at scale. While recent vision foundation models have shown remarkable success in learning large-scale remote sensing data with minimal annotations, most off-the-shelf solutions are designed for RGB images rather than multi-spectral satellite imagery, such as the 8-band data used in our study. In this paper, we introduce DeepAndes, a transformer-based vision foundation model trained on three million multi-spectral satellite images, specifically tailored for Andean archaeology. DeepAndes incorporates a customized DINOv2 self-supervised learning algorithm optimized for 8-band multi-spectral imagery, marking the first foundation model designed explicitly for the Andes region. We evaluate its image understanding performance through imbalanced image classification, image instance retrieval, and pixel-level semantic segmentation tasks. Our experiments show that DeepAndes achieves superior F1 scores, mean average precision, and Dice scores in few-shot learning scenarios, significantly outperforming models trained from scratch or pre-trained on smaller datasets. This underscores the effectiveness of large-scale self-supervised pre-training in archaeological remote sensing. Codes will be available on https://github.com/geopacha/DeepAndes.
4D Multimodal Co-attention Fusion Network with Latent Contrastive Alignment for Alzheimer's Diagnosis
Apr 23, 2025



Multimodal neuroimaging provides complementary structural and functional insights into both human brain organization and disease-related dynamics. Recent studies demonstrate enhanced diagnostic sensitivity for Alzheimer's disease (AD) through synergistic integration of neuroimaging data (e.g., sMRI, fMRI) with behavioral cognitive scores tabular data biomarkers. However, the intrinsic heterogeneity across modalities (e.g., 4D spatiotemporal fMRI dynamics vs. 3D anatomical sMRI structure) presents critical challenges for discriminative feature fusion. To bridge this gap, we propose M2M-AlignNet: a geometry-aware multimodal co-attention network with latent alignment for early AD diagnosis using sMRI and fMRI. At the core of our approach is a multi-patch-to-multi-patch (M2M) contrastive loss function that quantifies and reduces representational discrepancies via geometry-weighted patch correspondence, explicitly aligning fMRI components across brain regions with their sMRI structural substrates without one-to-one constraints. Additionally, we propose a latent-as-query co-attention module to autonomously discover fusion patterns, circumventing modality prioritization biases while minimizing feature redundancy. We conduct extensive experiments to confirm the effectiveness of our method and highlight the correspondance between fMRI and sMRI as AD biomarkers.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.