 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomical Prior-Driven Framework for Autonomous Robotic Cardiac Ultrasound Standard View Acquisition
Mar 22, 2026Cardiac ultrasound diagnosis is critical for cardiovascular disease assessment, but acquiring standard views remains highly operator-dependent. Existing medical segmentation models often yield anatomically inconsistent results in images with poor textural differentiation between distinct feature classes, while autonomous probe adjustment methods either rely on simplistic heuristic rules or black-box learning. To address these issues, our study proposed an anatomical prior (AP)-driven framework integrating cardiac structure segmentation and autonomous probe adjustment for standard view acquisition. A YOLO-based multi-class segmentation model augmented by a spatial-relation graph (SRG) module is designed to embed AP into the feature pyramid. Quantifiable anatomical features of standard views are extracted. Their priors are fitted to Gaussian distributions to construct probabilistic APs. The probe adjustment process of robotic ultrasound scanning is formalized as a reinforcement learning (RL) problem, with the RL state built from real-time anatomical features and the reward reflecting the AP matching. Experiments validate the efficacy of the framework. The SRG-YOLOv11s improves mAP50 by 11.3% and mIoU by 6.8% on the Special Case dataset, while the RL agent achieves a 92.5% success rate in simulation and 86.7% in phantom experiments.
AirCache: Activating Inter-modal Relevancy KV Cache Compression for Efficient Large Vision-Language Model Inference
Mar 31, 2025Recent advancements in Large Visual Language Models (LVLMs) have gained significant attention due to their remarkable reasoning capabilities and proficiency in generalization. However, processing a large number of visual tokens and generating long-context outputs impose substantial computational overhead, leading to excessive demands for key-value (KV) cache. To address this critical bottleneck, we propose AirCache, a novel KV cache compression method aimed at accelerating LVLMs inference. This work systematically investigates the correlations between visual and textual tokens within the attention mechanisms of LVLMs. Our empirical analysis reveals considerable redundancy in cached visual tokens, wherein strategically eliminating these tokens preserves model performance while significantly accelerating context generation. Inspired by these findings, we introduce an elite observation window for assessing the importance of visual components in the KV cache, focusing on stable inter-modal relevancy modeling with enhanced multi-perspective consistency. Additionally, we develop an adaptive layer-wise budget allocation strategy that capitalizes on the strength and skewness of token importance distribution, showcasing superior efficiency compared to uniform allocation. Comprehensive evaluations across multiple LVLMs and benchmarks demonstrate that our method achieves comparable performance to the full cache while retaining only 10% of visual KV cache, thereby reducing decoding latency by 29% to 66% across various batch size and prompt length of inputs. Notably, as cache retention rates decrease, our method exhibits increasing performance advantages over existing approaches.
GFormer: Accelerating Large Language Models with Optimized Transformers on Gaudi Processors
Dec 19, 2024



Heterogeneous hardware like Gaudi processor has been developed to enhance computations, especially matrix operations for Transformer-based large language models (LLMs) for generative AI tasks. However, our analysis indicates that Transformers are not fully optimized on such emerging hardware, primarily due to inadequate optimizations in non-matrix computational kernels like Softmax and in heterogeneous resource utilization, particularly when processing long sequences. To address these issues, we propose an integrated approach (called GFormer) that merges sparse and linear attention mechanisms. GFormer aims to maximize the computational capabilities of the Gaudi processor's Matrix Multiplication Engine (MME) and Tensor Processing Cores (TPC) without compromising model quality. GFormer includes a windowed self-attention kernel and an efficient outer product kernel for causal linear attention, aiming to optimize LLM inference on Gaudi processors. Evaluation shows that GFormer significantly improves efficiency and model performance across various tasks on the Gaudi processor and outperforms state-of-the-art GPUs.
CityLLaVA: Efficient Fine-Tuning for VLMs in City Scenario
May 06, 2024



In the vast and dynamic landscape of urban settings, Traffic Safety Description and Analysis plays a pivotal role in applications ranging from insurance inspection to accident prevention. This paper introduces CityLLaVA, a novel fine-tuning framework for Visual Language Models (VLMs) designed for urban scenarios. CityLLaVA enhances model comprehension and prediction accuracy through (1) employing bounding boxes for optimal visual data preprocessing, including video best-view selection and visual prompt engineering during both training and testing phases; (2) constructing concise Question-Answer sequences and designing textual prompts to refine instruction comprehension; (3) implementing block expansion to fine-tune large VLMs efficiently; and (4) advancing prediction accuracy via a unique sequential questioning-based prediction augmentation. Demonstrating top-tier performance, our method achieved a benchmark score of 33.4308, securing the leading position on the leaderboard. The code can be found: https://github.com/alibaba/AICITY2024_Track2_AliOpenTrek_CityLLaVA
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
A Comprehensive Performance Study of Large Language Models on Novel AI Accelerators
Oct 06, 2023



Artificial intelligence (AI) methods have become critical in scientific applications to help accelerate scientific discovery. Large language models (LLMs) are being considered as a promising approach to address some of the challenging problems because of their superior generalization capabilities across domains. The effectiveness of the models and the accuracy of the applications is contingent upon their efficient execution on the underlying hardware infrastructure. Specialized AI accelerator hardware systems have recently become available for accelerating AI applications. However, the comparative performance of these AI accelerators on large language models has not been previously studied. In this paper, we systematically study LLMs on multiple AI accelerators and GPUs and evaluate their performance characteristics for these models. We evaluate these systems with (i) a micro-benchmark using a core transformer block, (ii) a GPT- 2 model, and (iii) an LLM-driven science use case, GenSLM. We present our findings and analyses of the models' performance to better understand the intrinsic capabilities of AI accelerators. Furthermore, our analysis takes into account key factors such as sequence lengths, scaling behavior, sparsity, and sensitivity to gradient accumulation steps.
Benchmarking and In-depth Performance Study of Large Language Models on Habana Gaudi Processors
Sep 29, 2023



Transformer models have achieved remarkable success in various machine learning tasks but suffer from high computational complexity and resource requirements. The quadratic complexity of the self-attention mechanism further exacerbates these challenges when dealing with long sequences and large datasets. Specialized AI hardware accelerators, such as the Habana GAUDI architecture, offer a promising solution to tackle these issues. GAUDI features a Matrix Multiplication Engine (MME) and a cluster of fully programmable Tensor Processing Cores (TPC). This paper explores the untapped potential of using GAUDI processors to accelerate Transformer-based models, addressing key challenges in the process. Firstly, we provide a comprehensive performance comparison between the MME and TPC components, illuminating their relative strengths and weaknesses. Secondly, we explore strategies to optimize MME and TPC utilization, offering practical insights to enhance computational efficiency. Thirdly, we evaluate the performance of Transformers on GAUDI, particularly in handling long sequences and uncovering performance bottlenecks. Lastly, we evaluate the end-to-end performance of two Transformer-based large language models (LLM) on GAUDI. The contributions of this work encompass practical insights for practitioners and researchers alike. We delve into GAUDI's capabilities for Transformers through systematic profiling, analysis, and optimization exploration. Our study bridges a research gap and offers a roadmap for optimizing Transformer-based model training on the GAUDI architecture.
Transfer Learning Across Heterogeneous Features For Efficient Tensor Program Generation
Apr 11, 2023Tuning tensor program generation involves searching for various possible program transformation combinations for a given program on target hardware to optimize the tensor program execution. It is already a complex process because of the massive search space and exponential combinations of transformations make auto-tuning tensor program generation more challenging, especially when we have a heterogeneous target. In this research, we attempt to address these problems by learning the joint neural network and hardware features and transferring them to the new target hardware. We extensively study the existing state-of-the-art dataset, TenSet, perform comparative analysis on the test split strategies and propose methodologies to prune the dataset. We adopt an attention-inspired approach for tuning the tensor programs enabling them to embed neural network and hardware-specific features. Our approach could prune the dataset up to 45\% of the baseline without compromising the Pairwise Comparison Accuracy (PCA). Further, the proposed methodology can achieve on-par or improved mean inference time with 25%-40% of the baseline tuning time across different networks and target hardware.
Adaptive Neural Network-Based Approximation to Accelerate Eulerian Fluid Simulation
Aug 26, 2020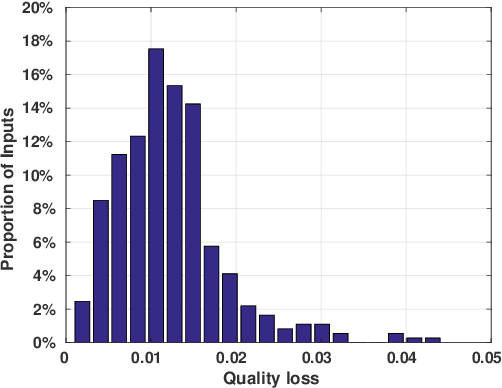
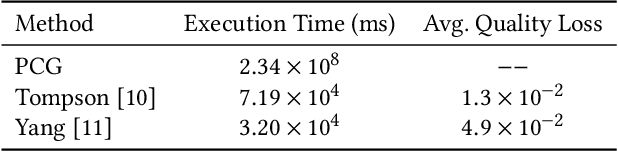
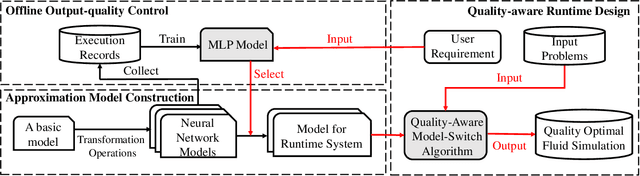
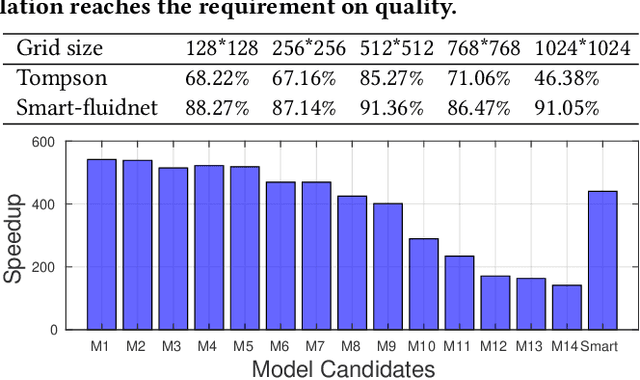
The Eulerian fluid simulation is an important HPC application. The neural network has been applied to accelerate it. The current methods that accelerate the fluid simulation with neural networks lack flexibility and generalization. In this paper, we tackle the above limitation and aim to enhance the applicability of neural networks in the Eulerian fluid simulation. We introduce Smartfluidnet, a framework that automates model generation and application. Given an existing neural network as input, Smartfluidnet generates multiple neural networks before the simulation to meet the execution time and simulation quality requirement. During the simulation, Smartfluidnet dynamically switches the neural networks to make the best efforts to reach the user requirement on simulation quality. Evaluating with 20,480 input problems, we show that Smartfluidnet achieves 1.46x and 590x speedup comparing with a state-of-the-art neural network model and the original fluid simulation respectively on an NVIDIA Titan X Pascal GPU, while providing better simulation quality than the state-of-the-art model.
Smart-PGSim: Using Neural Network to Accelerate AC-OPF Power Grid Simulation
Aug 26, 2020


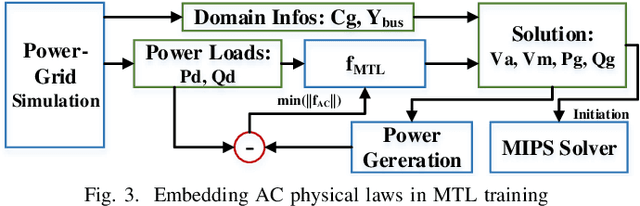
The optimal power flow (OPF) problem is one of the most important optimization problems for the operation of the power grid. It calculates the optimum scheduling of the committed generation units. In this paper, we develop a neural network approach to the problem of accelerating the current optimal power flow (AC-OPF) by generating an intelligent initial solution. The high quality of the initial solution and guidance of other outputs generated by the neural network enables faster convergence to the solution without losing optimality of final solution as computed by traditional methods. Smart-PGSim generates a novel multitask-learning neural network model to accelerate the AC-OPF simulation. Smart-PGSim also imposes the physical constraints of the simulation on the neural network automatically. Smart-PGSim brings an average of 49.2% performance improvement (up to 91%), computed over 10,000 problem simulations, with respect to the original AC-OPF implementation, without losing the optimality of the final solution.