 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuppeteer: Rig and Animate Your 3D Models
Aug 14, 2025



Modern interactive applications increasingly demand dynamic 3D content, yet the transformation of static 3D models into animated assets constitutes a significant bottleneck in content creation pipelines. While recent advances in generative AI have revolutionized static 3D model creation, rigging and animation continue to depend heavily on expert intervention. We present Puppeteer, a comprehensive framework that addresses both automatic rigging and animation for diverse 3D objects. Our system first predicts plausible skeletal structures via an auto-regressive transformer that introduces a joint-based tokenization strategy for compact representation and a hierarchical ordering methodology with stochastic perturbation that enhances bidirectional learning capabilities. It then infers skinning weights via an attention-based architecture incorporating topology-aware joint attention that explicitly encodes inter-joint relationships based on skeletal graph distances. Finally, we complement these rigging advances with a differentiable optimization-based animation pipeline that generates stable, high-fidelity animations while being computationally more efficient than existing approaches. Extensive evaluations across multiple benchmarks demonstrate that our method significantly outperforms state-of-the-art techniques in both skeletal prediction accuracy and skinning quality. The system robustly processes diverse 3D content, ranging from professionally designed game assets to AI-generated shapes, producing temporally coherent animations that eliminate the jittering issues common in existing methods.
AnalogSeeker: An Open-source Foundation Language Model for Analog Circuit Design
Aug 14, 2025In this paper, we propose AnalogSeeker, an effort toward an open-source foundation language model for analog circuit design, with the aim of integrating domain knowledge and giving design assistance. To overcome the scarcity of data in this field, we employ a corpus collection strategy based on the domain knowledge framework of analog circuits. High-quality, accessible textbooks across relevant subfields are systematically curated and cleaned into a textual domain corpus. To address the complexity of knowledge of analog circuits, we introduce a granular domain knowledge distillation method. Raw, unlabeled domain corpus is decomposed into typical, granular learning nodes, where a multi-agent framework distills implicit knowledge embedded in unstructured text into question-answer data pairs with detailed reasoning processes, yielding a fine-grained, learnable dataset for fine-tuning. To address the unexplored challenges in training analog circuit foundation models, we explore and share our training methods through both theoretical analysis and experimental validation. We finally establish a fine-tuning-centric training paradigm, customizing and implementing a neighborhood self-constrained supervised fine-tuning algorithm. This approach enhances training outcomes by constraining the perturbation magnitude between the model's output distributions before and after training. In practice, we train the Qwen2.5-32B-Instruct model to obtain AnalogSeeker, which achieves 85.04% accuracy on AMSBench-TQA, the analog circuit knowledge evaluation benchmark, with a 15.67% point improvement over the original model and is competitive with mainstream commercial models. Furthermore, AnalogSeeker also shows effectiveness in the downstream operational amplifier design task. AnalogSeeker is open-sourced at https://huggingface.co/analogllm/analogseeker for research use.
RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Integrating LLM-Derived Multi-Semantic Intent into Graph Model for Session-based Recommendation
Jul 27, 2025Session-based recommendation (SBR) is mainly based on anonymous user interaction sequences to recommend the items that the next user is most likely to click. Currently, the most popular and high-performing SBR methods primarily leverage graph neural networks (GNNs), which model session sequences as graph-structured data to effectively capture user intent. However, most GNNs-based SBR methods primarily focus on modeling the ID sequence information of session sequences, while neglecting the rich semantic information embedded within them. This limitation significantly hampers model's ability to accurately infer users' true intention. To address above challenge, this paper proposes a novel SBR approach called Integrating LLM-Derived Multi-Semantic Intent into Graph Model for Session-based Recommendation (LLM-DMsRec). The method utilizes a pre-trained GNN model to select the top-k items as candidate item sets and designs prompts along with a large language model (LLM) to infer multi-semantic intents from these candidate items. Specifically, we propose an alignment mechanism that effectively integrates the semantic intent inferred by the LLM with the structural intent captured by GNNs. Extensive experiments conducted on the Beauty and ML-1M datasets demonstrate that the proposed method can be seamlessly integrated into GNNs framework, significantly enhancing its recommendation performance.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
Long-Tailed Distribution-Aware Router For Mixture-of-Experts in Large Vision-Language Model
Jul 02, 2025The mixture-of-experts (MoE), which replaces dense models with sparse architectures, has gained attention in large vision-language models (LVLMs) for achieving comparable performance with fewer activated parameters. Existing MoE frameworks for LVLMs focus on token-to-expert routing (TER), encouraging different experts to specialize in processing distinct tokens. However, these frameworks often rely on the load balancing mechanism, overlooking the inherent distributional differences between vision and language. To this end, we propose a Long-Tailed Distribution-aware Router (LTDR) for vision-language TER, tackling two challenges: (1) Distribution-aware router for modality-specific routing. We observe that language TER follows a uniform distribution, whereas vision TER exhibits a long-tailed distribution. This discrepancy necessitates distinct routing strategies tailored to each modality. (2) Enhancing expert activation for vision tail tokens. Recognizing the importance of vision tail tokens, we introduce an oversampling-like strategy by increasing the number of activated experts for these tokens. Experiments on extensive benchmarks validate the effectiveness of our approach.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
OneRec Technical Report
Jun 16, 2025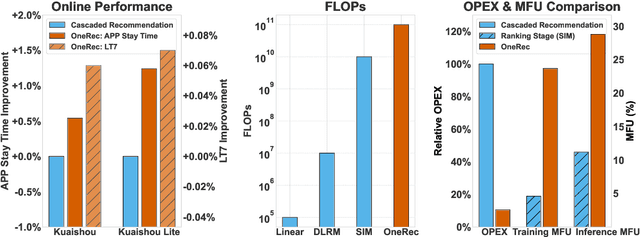

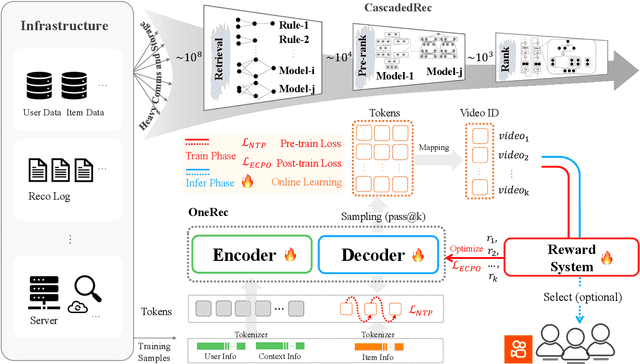
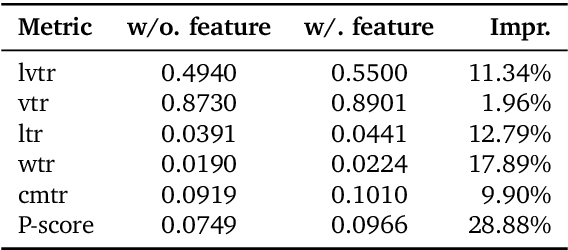
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Reviving DSP for Advanced Theorem Proving in the Era of Reasoning Models
Jun 13, 2025Recent advancements, such as DeepSeek-Prover-V2-671B and Kimina-Prover-Preview-72B, demonstrate a prevailing trend in leveraging reinforcement learning (RL)-based large-scale training for automated theorem proving. Surprisingly, we discover that even without any training, careful neuro-symbolic coordination of existing off-the-shelf reasoning models and tactic step provers can achieve comparable performance. This paper introduces \textbf{DSP+}, an improved version of the Draft, Sketch, and Prove framework, featuring a \emph{fine-grained and integrated} neuro-symbolic enhancement for each phase: (1) In the draft phase, we prompt reasoning models to generate concise natural-language subgoals to benefit the sketch phase, removing thinking tokens and references to human-written proofs; (2) In the sketch phase, subgoals are autoformalized with hypotheses to benefit the proving phase, and sketch lines containing syntactic errors are masked according to predefined rules; (3) In the proving phase, we tightly integrate symbolic search methods like Aesop with step provers to establish proofs for the sketch subgoals. Experimental results show that, without any additional model training or fine-tuning, DSP+ solves 80.7\%, 32.8\%, and 24 out of 644 problems from miniF2F, ProofNet, and PutnamBench, respectively, while requiring fewer budgets compared to state-of-the-arts. DSP+ proves \texttt{imo\_2019\_p1}, an IMO problem in miniF2F that is not solved by any prior work. Additionally, DSP+ generates proof patterns comprehensible by human experts, facilitating the identification of formalization errors; For example, eight wrongly formalized statements in miniF2F are discovered. Our results highlight the potential of classical reasoning patterns besides the RL-based training. All components will be open-sourced.