 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneWorld: Scaling Phone-Use Agent Environments
May 28, 2026A central bottleneck for phone-use agents is that controllable, reproducible environments covering real mobile behavior are hard to build at scale. Existing mobile-agent benchmarks have made important progress on evaluation, but they do not by themselves provide a scalable way to construct many new phone-use environments. We present PhoneWorld, a reusable pipeline that converts real GUI trajectories and screenshots into controllable phone-use environments, executable tasks, automatic verifiers, and training rollouts. Rather than hand-building one mobile benchmark at a time, PhoneWorld uses real trajectories to recover which screens matter, how screens connect, which interactions must change environment state, and which user goals admit automatic verification. From these signals, it builds runnable mock Android apps backed by read-only app content and mutable state, then derives executable tasks, rule-based verifiers, and training rollouts from the same environments. In its current instantiation, PhoneWorld covers 34 apps across 16 domains, spanning common consumer mobile behaviors such as search, browsing, shopping, booking, media, and social interaction. Under a fixed training budget, replacing 10K steps from an auxiliary AndroidWorld corpus in an AndroidWorld-based baseline with broad PhoneWorld supervision improves all four evaluation benchmarks at once, raising HYMobileBench by 17.7 points, AndroidControl by 6.0 points, AndroidWorld by 14.7 points, and PhoneWorld by 52.5 points. We then study two additional scaling questions: increasing the amount of PhoneWorld supervision strongly improves PhoneWorld performance, and under a fixed PhoneWorld budget, expanding app coverage yields even larger gains. Overall, PhoneWorld shifts the focus from building one mobile benchmark at a time to scaling the supply of phone-use environments themselves.
VideoZoomer: Reinforcement-Learned Temporal Focusing for Long Video Reasoning
Dec 26, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable progress in vision-language tasks yet remain limited in long video understanding due to the limited context window. Consequently, prevailing approaches tend to rely on uniform frame sampling or static pre-selection, which might overlook critical evidence and unable to correct its initial selection error during its reasoning process. To overcome these limitations, we propose VideoZoomer, a novel agentic framework that enables MLLMs to dynamically control their visual focus during reasoning. Starting from a coarse low-frame-rate overview, VideoZoomer invokes a temporal zoom tool to obtain high-frame-rate clips at autonomously chosen moments, thereby progressively gathering fine-grained evidence in a multi-turn interactive manner. Accordingly, we adopt a two-stage training strategy: a cold-start supervised fine-tuning phase on a curated dataset of distilled exemplar and reflection trajectories, followed by reinforcement learning to further refine the agentic policy. Extensive experiments demonstrate that our 7B model delivers diverse and complex reasoning patterns, yielding strong performance across a broad set of long video understanding and reasoning benchmarks. These emergent capabilities allow it to consistently surpass existing open-source models and even rival proprietary systems on challenging tasks, while achieving superior efficiency under reduced frame budgets.
PeRL: Permutation-Enhanced Reinforcement Learning for Interleaved Vision-Language Reasoning
Jun 17, 2025Inspired by the impressive reasoning capabilities demonstrated by reinforcement learning approaches like DeepSeek-R1, recent emerging research has begun exploring the use of reinforcement learning (RL) to enhance vision-language models (VLMs) for multimodal reasoning tasks. However, most existing multimodal reinforcement learning approaches remain limited to spatial reasoning within single-image contexts, yet still struggle to generalize to more complex and real-world scenarios involving multi-image positional reasoning, where understanding the relationships across images is crucial. To address this challenge, we propose a general reinforcement learning approach PeRL tailored for interleaved multimodal tasks, and a multi-stage strategy designed to enhance the exploration-exploitation trade-off, thereby improving learning efficiency and task performance. Specifically, we introduce permutation of image sequences to simulate varied positional relationships to explore more spatial and positional diversity. Furthermore, we design a rollout filtering mechanism for resampling to focus on trajectories that contribute most to learning optimal behaviors to exploit learned policies effectively. We evaluate our model on 5 widely-used multi-image benchmarks and 3 single-image benchmarks. Our experiments confirm that PeRL trained model consistently surpasses R1-related and interleaved VLM baselines by a large margin, achieving state-of-the-art performance on multi-image benchmarks, while preserving comparable performance on single-image tasks.
MISE: Meta-knowledge Inheritance for Social Media-Based Stressor Estimation
May 03, 2025Stress haunts people in modern society, which may cause severe health issues if left unattended. With social media becoming an integral part of daily life, leveraging social media to detect stress has gained increasing attention. While the majority of the work focuses on classifying stress states and stress categories, this study introduce a new task aimed at estimating more specific stressors (like exam, writing paper, etc.) through users' posts on social media. Unfortunately, the diversity of stressors with many different classes but a few examples per class, combined with the consistent arising of new stressors over time, hinders the machine understanding of stressors. To this end, we cast the stressor estimation problem within a practical scenario few-shot learning setting, and propose a novel meta-learning based stressor estimation framework that is enhanced by a meta-knowledge inheritance mechanism. This model can not only learn generic stressor context through meta-learning, but also has a good generalization ability to estimate new stressors with little labeled data. A fundamental breakthrough in our approach lies in the inclusion of the meta-knowledge inheritance mechanism, which equips our model with the ability to prevent catastrophic forgetting when adapting to new stressors. The experimental results show that our model achieves state-of-the-art performance compared with the baselines. Additionally, we construct a social media-based stressor estimation dataset that can help train artificial intelligence models to facilitate human well-being. The dataset is now public at \href{https://www.kaggle.com/datasets/xinwangcs/stressor-cause-of-mental-health-problem-dataset}{\underline{Kaggle}} and \href{https://huggingface.co/datasets/XinWangcs/Stressor}{\underline{Hugging Face}}.
NF-SLAM: Effective, Normalizing Flow-supported Neural Field representations for object-level visual SLAM in automotive applications
Mar 14, 2025We propose a novel, vision-only object-level SLAM framework for automotive applications representing 3D shapes by implicit signed distance functions. Our key innovation consists of augmenting the standard neural representation by a normalizing flow network. As a result, achieving strong representation power on the specific class of road vehicles is made possible by compact networks with only 16-dimensional latent codes. Furthermore, the newly proposed architecture exhibits a significant performance improvement in the presence of only sparse and noisy data, which is demonstrated through comparative experiments on synthetic data. The module is embedded into the back-end of a stereo-vision based framework for joint, incremental shape optimization. The loss function is given by a combination of a sparse 3D point-based SDF loss, a sparse rendering loss, and a semantic mask-based silhouette-consistency term. We furthermore leverage semantic information to determine keypoint extraction density in the front-end. Finally, experimental results on real-world data reveal accurate and reliable performance comparable to alternative frameworks that make use of direct depth readings. The proposed method performs well with only sparse 3D points obtained from bundle adjustment, and eventually continues to deliver stable results even under exclusive use of the mask-consistency term.
Long Range Switching Time Series Prediction via State Space Model
Jul 27, 2024



In this study, we delve into the Structured State Space Model (S4), Change Point Detection methodologies, and the Switching Non-linear Dynamics System (SNLDS). Our central proposition is an enhanced inference technique and long-range dependency method for SNLDS. The cornerstone of our approach is the fusion of S4 and SNLDS, leveraging the strengths of both models to effectively address the intricacies of long-range dependencies in switching time series. Through rigorous testing, we demonstrate that our proposed methodology adeptly segments and reproduces long-range dependencies in both the 1-D Lorenz dataset and the 2-D bouncing ball dataset. Notably, our integrated approach outperforms the standalone SNLDS in these tasks.
Model-enhanced Vector Index
Sep 23, 2023



Embedding-based retrieval methods construct vector indices to search for document representations that are most similar to the query representations. They are widely used in document retrieval due to low latency and decent recall performance. Recent research indicates that deep retrieval solutions offer better model quality, but are hindered by unacceptable serving latency and the inability to support document updates. In this paper, we aim to enhance the vector index with end-to-end deep generative models, leveraging the differentiable advantages of deep retrieval models while maintaining desirable serving efficiency. We propose Model-enhanced Vector Index (MEVI), a differentiable model-enhanced index empowered by a twin-tower representation model. MEVI leverages a Residual Quantization (RQ) codebook to bridge the sequence-to-sequence deep retrieval and embedding-based models. To substantially reduce the inference time, instead of decoding the unique document ids in long sequential steps, we first generate some semantic virtual cluster ids of candidate documents in a small number of steps, and then leverage the well-adapted embedding vectors to further perform a fine-grained search for the relevant documents in the candidate virtual clusters. We empirically show that our model achieves better performance on the commonly used academic benchmarks MSMARCO Passage and Natural Questions, with comparable serving latency to dense retrieval solutions.
SeaEval for Multilingual Foundation Models: From Cross-Lingual Alignment to Cultural Reasoning
Sep 09, 2023We present SeaEval, a benchmark for multilingual foundation models. In addition to characterizing how these models understand and reason with natural language, we also investigate how well they comprehend cultural practices, nuances, and values. Alongside standard accuracy metrics, we investigate the brittleness of foundation models in the dimensions of semantics and multilinguality. Our analyses span both open-sourced and closed models, leading to empirical results across classic NLP tasks, reasoning, and cultural comprehension. Key findings indicate (1) Most models exhibit varied behavior when given paraphrased instructions. (2) Many models still suffer from exposure bias (e.g., positional bias, majority label bias). (3) For questions rooted in factual, scientific, and commonsense knowledge, consistent responses are expected across multilingual queries that are semantically equivalent. Yet, most models surprisingly demonstrate inconsistent performance on these queries. (4) Multilingually-trained models have not attained "balanced multilingual" capabilities. Our endeavors underscore the need for more generalizable semantic representations and enhanced multilingual contextualization. SeaEval can serve as a launchpad for more thorough investigations and evaluations for multilingual and multicultural scenarios.
Towards Fast and Accurate Image-Text Retrieval with Self-Supervised Fine-Grained Alignment
Aug 27, 2023



Image-text retrieval requires the system to bridge the heterogenous gap between vision and language for accurate retrieval while keeping the network lightweight-enough for efficient retrieval. Existing trade-off solutions mainly study from the view of incorporating cross-modal interactions with the independent-embedding framework or leveraging stronger pretrained encoders, which still demand time-consuming similarity measurement or heavyweight model structure in the retrieval stage. In this work, we propose an image-text alignment module SelfAlign on top of the independent-embedding framework, which improves the retrieval accuracy while maintains the retrieval efficiency without extra supervision. SelfAlign contains two collaborative sub-modules that force image-text alignment at both concept level and context level by self-supervised contrastive learning. It does not require cross-modal embedding interactions during training while maintaining independent image and text encoders during retrieval. With comparable time cost, SelfAlign consistently boosts the accuracy of state-of-the-art non-pretraining independent-embedding models respectively by 9.1%, 4.2% and 6.6% in terms of R@sum score on Flickr30K, MSCOCO 1K and MS-COCO 5K datasets. The retrieval accuracy also outperforms most existing interactive-embedding models with orders of magnitude decrease in retrieval time. The source code is available at: https://github.com/Zjamie813/SelfAlign.
* Accepted in IEEE Transactions on Multimedia (TMM)
MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering
Mar 17, 2022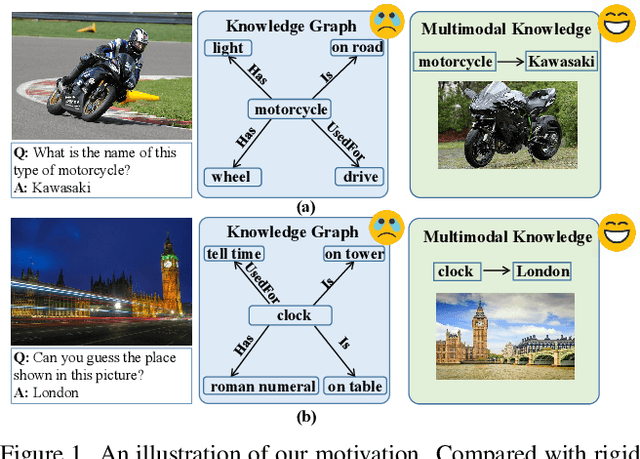

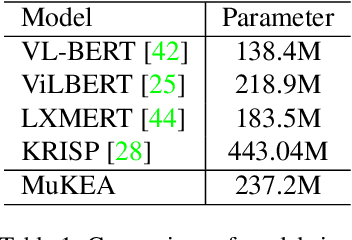
Knowledge-based visual question answering requires the ability of associating external knowledge for open-ended cross-modal scene understanding. One limitation of existing solutions is that they capture relevant knowledge from text-only knowledge bases, which merely contain facts expressed by first-order predicates or language descriptions while lacking complex but indispensable multimodal knowledge for visual understanding. How to construct vision-relevant and explainable multimodal knowledge for the VQA scenario has been less studied. In this paper, we propose MuKEA to represent multimodal knowledge by an explicit triplet to correlate visual objects and fact answers with implicit relations. To bridge the heterogeneous gap, we propose three objective losses to learn the triplet representations from complementary views: embedding structure, topological relation and semantic space. By adopting a pre-training and fine-tuning learning strategy, both basic and domain-specific multimodal knowledge are progressively accumulated for answer prediction. We outperform the state-of-the-art by 3.35% and 6.08% respectively on two challenging knowledge-required datasets: OK-VQA and KRVQA. Experimental results prove the complementary benefits of the multimodal knowledge with existing knowledge bases and the advantages of our end-to-end framework over the existing pipeline methods. The code is available at https://github.com/AndersonStra/MuKEA.