 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2SBench: A Benchmark for Quantifying Intelligence Degradation in Speech-to-Speech Large Language Models
May 20, 2025



End-to-end speech large language models ((LLMs)) extend the capabilities of text-based models to directly process and generate audio tokens. However, this often leads to a decline in reasoning and generation performance compared to text input, a phenomenon referred to as intelligence degradation. To systematically evaluate this gap, we propose S2SBench, a benchmark designed to quantify performance degradation in Speech LLMs. It includes diagnostic datasets targeting sentence continuation and commonsense reasoning under audio input. We further introduce a pairwise evaluation protocol based on perplexity differences between plausible and implausible samples to measure degradation relative to text input. We apply S2SBench to analyze the training process of Baichuan-Audio, which further demonstrates the benchmark's effectiveness. All datasets and evaluation code are available at https://github.com/undobug/S2SBench.
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mar 27, 2025



Large Language Models (LLMs) have shown remarkable capabilities in reasoning, exemplified by the success of OpenAI-o1 and DeepSeek-R1. However, integrating reasoning with external search processes remains challenging, especially for complex multi-hop questions requiring multiple retrieval steps. We propose ReSearch, a novel framework that trains LLMs to Reason with Search via reinforcement learning without using any supervised data on reasoning steps. Our approach treats search operations as integral components of the reasoning chain, where when and how to perform searches is guided by text-based thinking, and search results subsequently influence further reasoning. We train ReSearch on Qwen2.5-7B(-Instruct) and Qwen2.5-32B(-Instruct) models and conduct extensive experiments. Despite being trained on only one dataset, our models demonstrate strong generalizability across various benchmarks. Analysis reveals that ReSearch naturally elicits advanced reasoning capabilities such as reflection and self-correction during the reinforcement learning process.
DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
Mar 19, 2025The differing representation spaces required for visual understanding and generation pose a challenge in unifying them within the autoregressive paradigm of large language models. A vision tokenizer trained for reconstruction excels at capturing low-level perceptual details, making it well-suited for visual generation but lacking high-level semantic representations for understanding tasks. Conversely, a vision encoder trained via contrastive learning aligns well with language but struggles to decode back into the pixel space for generation tasks. To bridge this gap, we propose DualToken, a method that unifies representations for both understanding and generation within a single tokenizer. However, directly integrating reconstruction and semantic objectives in a single tokenizer creates conflicts, leading to degraded performance in both reconstruction quality and semantic performance. Instead of forcing a single codebook to handle both semantic and perceptual information, DualToken disentangles them by introducing separate codebooks for high and low-level features, effectively transforming their inherent conflict into a synergistic relationship. As a result, DualToken achieves state-of-the-art performance in both reconstruction and semantic tasks while demonstrating remarkable effectiveness in downstream MLLM understanding and generation tasks. Notably, we also show that DualToken, as a unified tokenizer, surpasses the naive combination of two distinct types vision encoders, providing superior performance within a unified MLLM.
Efficient Motion-Aware Video MLLM
Mar 17, 2025



Most current video MLLMs rely on uniform frame sampling and image-level encoders, resulting in inefficient data processing and limited motion awareness. To address these challenges, we introduce EMA, an Efficient Motion-Aware video MLLM that utilizes compressed video structures as inputs. We propose a motion-aware GOP (Group of Pictures) encoder that fuses spatial and motion information within a GOP unit in the compressed video stream, generating compact, informative visual tokens. By integrating fewer but denser RGB frames with more but sparser motion vectors in this native slow-fast input architecture, our approach reduces redundancy and enhances motion representation. Additionally, we introduce MotionBench, a benchmark for evaluating motion understanding across four motion types: linear, curved, rotational, and contact-based. Experimental results show that EMA achieves state-of-the-art performance on both MotionBench and popular video question answering benchmarks, while reducing inference costs. Moreover, EMA demonstrates strong scalability, as evidenced by its competitive performance on long video understanding benchmarks.
Baichuan-Audio: A Unified Framework for End-to-End Speech Interaction
Feb 24, 2025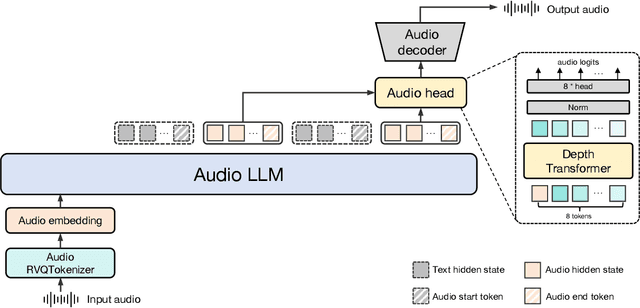


We introduce Baichuan-Audio, an end-to-end audio large language model that seamlessly integrates audio understanding and generation. It features a text-guided aligned speech generation mechanism, enabling real-time speech interaction with both comprehension and generation capabilities. Baichuan-Audio leverages a pre-trained ASR model, followed by multi-codebook discretization of speech at a frame rate of 12.5 Hz. This multi-codebook setup ensures that speech tokens retain both semantic and acoustic information. To further enhance modeling, an independent audio head is employed to process audio tokens, effectively capturing their unique characteristics. To mitigate the loss of intelligence during pre-training and preserve the original capabilities of the LLM, we propose a two-stage pre-training strategy that maintains language understanding while enhancing audio modeling. Following alignment, the model excels in real-time speech-based conversation and exhibits outstanding question-answering capabilities, demonstrating its versatility and efficiency. The proposed model demonstrates superior performance in real-time spoken dialogue and exhibits strong question-answering abilities. Our code, model and training data are available at https://github.com/baichuan-inc/Baichuan-Audio
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
LongReD: Mitigating Short-Text Degradation of Long-Context Large Language Models via Restoration Distillation
Feb 11, 2025



Large language models (LLMs) have gained extended context windows through scaling positional encodings and lightweight continual pre-training. However, this often leads to degraded performance on short-text tasks, while the reasons for this degradation remain insufficiently explored. In this work, we identify two primary factors contributing to this issue: distribution drift in hidden states and attention scores, and catastrophic forgetting during continual pre-training. To address these challenges, we propose Long Context Pre-training with Restoration Distillation (LongReD), a novel approach designed to mitigate short-text performance degradation through minimizing the distribution discrepancy between the extended and original models. Besides training on long texts, LongReD distills the hidden state of selected layers from the original model on short texts. Additionally, LongReD also introduces a short-to-long distillation, aligning the output distribution on short texts with that on long texts by leveraging skipped positional indices. Experiments on common text benchmarks demonstrate that LongReD effectively preserves the model's short-text performance while maintaining comparable or even better capacity to handle long texts than baselines.
Ocean-OCR: Towards General OCR Application via a Vision-Language Model
Jan 26, 2025



Multimodal large language models (MLLMs) have shown impressive capabilities across various domains, excelling in processing and understanding information from multiple modalities. Despite the rapid progress made previously, insufficient OCR ability hinders MLLMs from excelling in text-related tasks. In this paper, we present \textbf{Ocean-OCR}, a 3B MLLM with state-of-the-art performance on various OCR scenarios and comparable understanding ability on general tasks. We employ Native Resolution ViT to enable variable resolution input and utilize a substantial collection of high-quality OCR datasets to enhance the model performance. We demonstrate the superiority of Ocean-OCR through comprehensive experiments on open-source OCR benchmarks and across various OCR scenarios. These scenarios encompass document understanding, scene text recognition, and handwritten recognition, highlighting the robust OCR capabilities of Ocean-OCR. Note that Ocean-OCR is the first MLLM to outperform professional OCR models such as TextIn and PaddleOCR.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Med-R$^2$: Crafting Trustworthy LLM Physicians through Retrieval and Reasoning of Evidence-Based Medicine
Jan 21, 2025



In recent years, Large Language Models (LLMs) have exhibited remarkable capabilities in clinical scenarios. However, despite their potential, existing works face challenges when applying LLMs to medical settings. Strategies relying on training with medical datasets are highly cost-intensive and may suffer from outdated training data. Leveraging external knowledge bases is a suitable alternative, yet it faces obstacles such as limited retrieval precision and poor effectiveness in answer extraction. These issues collectively prevent LLMs from demonstrating the expected level of proficiency in mastering medical expertise. To address these challenges, we introduce Med-R^2, a novel LLM physician framework that adheres to the Evidence-Based Medicine (EBM) process, efficiently integrating retrieval mechanisms as well as the selection and reasoning processes of evidence, thereby enhancing the problem-solving capabilities of LLMs in healthcare scenarios and fostering a trustworthy LLM physician. Our comprehensive experiments indicate that Med-R^2 achieves a 14.87\% improvement over vanilla RAG methods and even a 3.59\% enhancement compared to fine-tuning strategies, without incurring additional training costs.