 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecover, Discover, Plan: Learning Skills and Concepts from Robot Failures
Jun 16, 2026Intelligent robots should not only recover from failures, but also acquire the abstract knowledge needed to avoid them in the future. While reinforcement learning (RL) can learn reactive recovery behaviors, training a separate policy for every distinct failure mode is highly inefficient. We introduce Recovery-Driven Synthesis of Relational Concepts (ReSYNC), the first approach that progressively discovers and refines state abstractions (relational predicates) from failure-recovery experience to support abstract planning. Unlike purely reactive methods, ReSYNC jointly learns skills and concepts through an incremental dual-learning process. In the skill-learning phase, the robot uses RL to learn to recover from failures seen in training tasks. In the concept-learning phase, the robot discovers new relational predicates and refines its abstract planning model to explain and generalize the learned recovery behaviors. This interaction enables ReSYNC to convert local recoveries seen during training into global failure avoidance at test time. Across four simulated domains, we show that ReSYNC's ability to continually expand and refine its abstraction library allows it to solve long-horizon, previously unseen problems, outperforming strong baselines by over 50%. Additionally, we demonstrate sim-to-real transfer of ReSYNC, where it performs real-world non-prehensile manipulation skills and generalizes to unseen scenarios through abstract planning. Overall, ReSYNC represents a significant step toward robots that autonomously acquire abstractions for scalable, failure-aware planning in the physical world.
Neuro-Symbolic Learning for Long-Horizon Task Planning Under Complex Logical Constraints
Jun 05, 2026Task planning often suffers from severe efficiency bottlenecks when robots must reason over long-horizon action sequences under complex logical constraints, including object affordances, spatial relationships, and sequential action dependencies. Recent neuro-symbolic methods improve planning efficiency by learning object-importance scores to prune task-irrelevant objects, but they typically rely on fixed offline supervision generated from full search spaces. This creates a train-test mismatch: at deployment, the planner operates in pruned search spaces induced by the model's own imperfect predictions, leading to exposure bias and degraded planning performance. To address this challenge, we formulate object-importance learning for task planning as an imperative learning-based bilevel optimization problem. The upper level optimizes a neural scorer, while the lower level solves a symbolic planning problem in the score-pruned search space. To stabilize this learning process, we introduce a 3R strategy into the lower-level planning, using parallel Repair, Restart, and Rollback recovery to provide reliable and adaptive feedback for upper-level learning. Experiments on three challenging benchmarks demonstrate state-of-the-art performance, including an 80.04% reduction in failure rate and a 57.14% reduction in planning time. We further validate the framework on a quadruped-based mobile manipulator in simulation and the real world, demonstrating its potential for efficient and deployable neuro-symbolic task planning.
Don't Fool Me Twice: Adapting to Adversity in the Wild with Experience-Driven Reasoning
May 29, 2026In robotics, dangers and adversity modes are often embodiment-specific and relative to each agent. A frontier of autonomous mobile robotics is to enable agents to operate effectively in the wild in unseen unstructured environments. A significant challenge in unseen unstructured environments is that it may not be possible to predict all the dangers to the specific robot. Although recent work has used large foundation vision-language models (VLMs) to preemptively predict an exhaustive list of common-sense dangers, it remains difficult to capture possible interaction and embodiment-dependent adversities. We propose a continual learning framework for a mobile embodied agent to learn online from disturbances and attribute anomalous behaviours to causes through semantics, enabling better prediction and planning of the world in the future. Our framework, "Don't Fool Me Twice", first observes disturbances and describes their effects on the robot; this description is augmented with visual context to query a VLM to predict possible causes; the local disturbance is characterized using kernel regression, which allows for efficient, few-shot modeling of transient anomalies. We leverage semantic voxel-centric modeling to estimate epistemic uncertainty, enabling richer downstream recovery by treating interaction-driven disturbances as learnable spatial behaviors. We present four hypotheses and validate them in simulation and on hardware across embodiments and adversity modes.
KinDER: A Physical Reasoning Benchmark for Robot Learning and Planning
Apr 28, 2026Robotic systems that interact with the physical world must reason about kinematic and dynamic constraints imposed by their own embodiment, their environment, and the task at hand. We introduce KinDER, a benchmark for Kinematic and Dynamic Embodied Reasoning that targets physical reasoning challenges arising in robot learning and planning. KinDER comprises 25 procedurally generated environments, a Gymnasium-compatible Python library with parameterized skills and demonstrations, and a standardized evaluation suite with 13 implemented baselines spanning task and motion planning, imitation learning, reinforcement learning, and foundation-model-based approaches. The environments are designed to isolate five core physical reasoning challenges: basic spatial relations, nonprehensile multi-object manipulation, tool use, combinatorial geometric constraints, and dynamic constraints, disentangled from perception, language understanding, and application-specific complexity. Empirical evaluation shows that existing methods struggle to solve many of the environments, indicating substantial gaps in current approaches to physical reasoning. We additionally include real-to-sim-to-real experiments on a mobile manipulator to assess the correspondence between simulation and real-world physical interaction. KinDER is fully open-sourced and intended to enable systematic comparison across diverse paradigms for advancing physical reasoning in robotics. Website and code: https://prpl-group.com/kinder-site/
PRoID: Predicted Rate of Information Delivery in Multi-Robot Exploration and Relaying
Apr 12, 2026We address Multi-Robot Exploration and Relaying (MRER): a team of robots must explore an unknown environment and deliver acquired information to a fixed base station within a mission time limit. The central challenge is deciding when each robot should stop exploring and relay: this depends on what the robot is likely to find ahead, what information it uniquely holds, and whether immediate or future delivery is more valuable. Prior approaches either ignore the reporting requirement entirely or rely on fixed-schedule relay strategies that cannot adapt to environment structure, team composition, or mission progress. We introduce PRoID (Predicted Rate of Information Delivery), a relay criterion that uses learned map prediction to estimate each robot's future information gain along its planned path, accounting for what teammates are already relaying. PRoID triggers relay when immediate return yields higher information delivery per unit time. We further propose PRoID-Safe, a failure-aware extension that incorporates robot survival probability into the relay criterion, naturally biasing decisions toward earlier relay as failure risk grows. We evaluate on real-world indoor floor plan datasets and show that PRoID and PRoID-Safe outperform fixed-schedule baselines, with stronger relative gains in failure scenarios.
World2Rules: A Neuro-Symbolic Framework for Learning World-Governing Safety Rules for Aviation
Mar 30, 2026Many real-world safety-critical systems are governed by explicit rules that define unsafe world configurations and constrain agent interactions. In practice, these rules are complex and context-dependent, making manual specification incomplete and error-prone. Learning such rules from real-world multimodal data is further challenged by noise, inconsistency, and sparse failure cases. Neural models can extract structure from text and visual data but lack formal guarantees, while symbolic methods provide verifiability yet are brittle when applied directly to imperfect observations. We present World2Rules, a neuro-symbolic framework for learning world-governing safety rules from real-world multimodal aviation data. World2Rules learns from both nominal operational data and aviation crash and incident reports, treating neural models as proposal mechanisms for candidate symbolic facts and inductive logic programming as a verification layer. The framework employs hierarchical reflective reasoning, enforcing consistency across examples, subsets, and rules to filter unreliable evidence, aggregate only mutually consistent components, and prune unsupported hypotheses. This design limits error propagation from noisy neural extractions and yields compact, interpretable first-order logic rules that characterize unsafe world configurations. We evaluate World2Rules on real-world aviation safety data and show that it learns rules that achieve 23.6% higher F1 score than purely neural and 43.2% higher F1 score than single-pass neuro-symbolic baseline, while remaining suitable for safety-critical reasoning and formal analysis.
AnyThermal: Towards Learning Universal Representations for Thermal Perception
Feb 05, 2026We present AnyThermal, a thermal backbone that captures robust task-agnostic thermal features suitable for a variety of tasks such as cross-modal place recognition, thermal segmentation, and monocular depth estimation using thermal images. Existing thermal backbones that follow task-specific training from small-scale data result in utility limited to a specific environment and task. Unlike prior methods, AnyThermal can be used for a wide range of environments (indoor, aerial, off-road, urban) and tasks, all without task-specific training. Our key insight is to distill the feature representations from visual foundation models such as DINOv2 into a thermal encoder using thermal data from these multiple environments. To bridge the diversity gap of the existing RGB-Thermal datasets, we introduce the TartanRGBT platform, the first open-source data collection platform with synced RGB-Thermal image acquisition. We use this payload to collect the TartanRGBT dataset - a diverse and balanced dataset collected in 4 environments. We demonstrate the efficacy of AnyThermal and TartanRGBT, achieving state-of-the-art results with improvements of up to 36% across diverse environments and downstream tasks on existing datasets.
SyNeT: Synthetic Negatives for Traversability Learning
Feb 03, 2026Reliable traversability estimation is crucial for autonomous robots to navigate complex outdoor environments safely. Existing self-supervised learning frameworks primarily rely on positive and unlabeled data; however, the lack of explicit negative data remains a critical limitation, hindering the model's ability to accurately identify diverse non-traversable regions. To address this issue, we introduce a method to explicitly construct synthetic negatives, representing plausible but non-traversable, and integrate them into vision-based traversability learning. Our approach is formulated as a training strategy that can be seamlessly integrated into both Positive-Unlabeled (PU) and Positive-Negative (PN) frameworks without modifying inference architectures. Complementing standard pixel-wise metrics, we introduce an object-centric FPR evaluation approach that analyzes predictions in regions where synthetic negatives are inserted. This evaluation provides an indirect measure of the model's ability to consistently identify non-traversable regions without additional manual labeling. Extensive experiments on both public and self-collected datasets demonstrate that our approach significantly enhances robustness and generalization across diverse environments. The source code and demonstration videos will be publicly available.
Unifying Deep Predicate Invention with Pre-trained Foundation Models
Dec 19, 2025Long-horizon robotic tasks are hard due to continuous state-action spaces and sparse feedback. Symbolic world models help by decomposing tasks into discrete predicates that capture object properties and relations. Existing methods learn predicates either top-down, by prompting foundation models without data grounding, or bottom-up, from demonstrations without high-level priors. We introduce UniPred, a bilevel learning framework that unifies both. UniPred uses large language models (LLMs) to propose predicate effect distributions that supervise neural predicate learning from low-level data, while learned feedback iteratively refines the LLM hypotheses. Leveraging strong visual foundation model features, UniPred learns robust predicate classifiers in cluttered scenes. We further propose a predicate evaluation method that supports symbolic models beyond STRIPS assumptions. Across five simulated and one real-robot domains, UniPred achieves 2-4 times higher success rates than top-down methods and 3-4 times faster learning than bottom-up approaches, advancing scalable and flexible symbolic world modeling for robotics.
Any4D: Unified Feed-Forward Metric 4D Reconstruction
Dec 11, 2025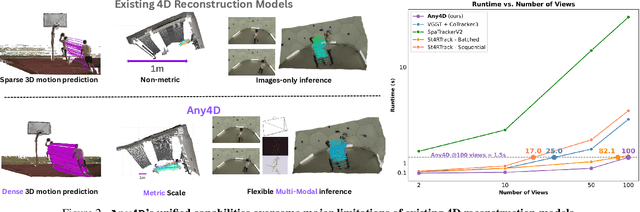
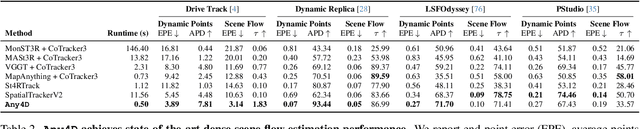
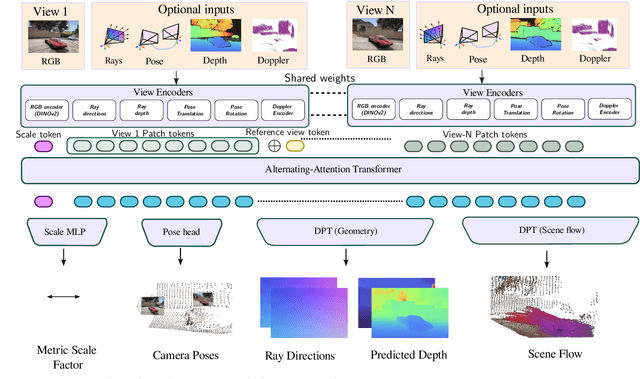
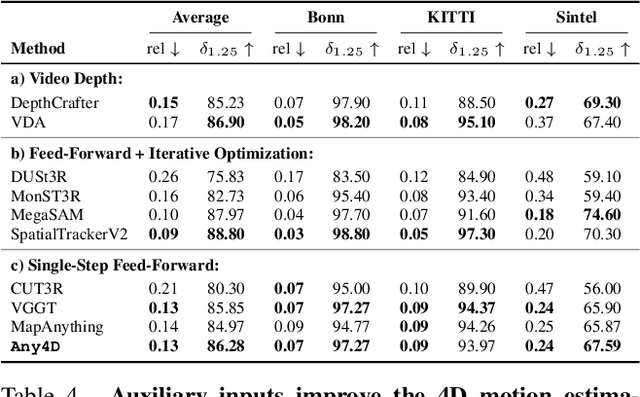
We present Any4D, a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. Any4D directly generates per-pixel motion and geometry predictions for N frames, in contrast to prior work that typically focuses on either 2-view dense scene flow or sparse 3D point tracking. Moreover, unlike other recent methods for 4D reconstruction from monocular RGB videos, Any4D can process additional modalities and sensors such as RGB-D frames, IMU-based egomotion, and Radar Doppler measurements, when available. One of the key innovations that allows for such a flexible framework is a modular representation of a 4D scene; specifically, per-view 4D predictions are encoded using a variety of egocentric factors (depthmaps and camera intrinsics) represented in local camera coordinates, and allocentric factors (camera extrinsics and scene flow) represented in global world coordinates. We achieve superior performance across diverse setups - both in terms of accuracy (2-3X lower error) and compute efficiency (15X faster), opening avenues for multiple downstream applications.