 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Embodied Perception in Dynamic Environments via Disentangled Weight Fusion
Apr 02, 2026Embodied perception systems face severe challenges of dynamic environment distribution drift when they continuously interact in open physical spaces. However, the existing domain incremental awareness methods often rely on the domain id obtained in advance during the testing phase, which limits their practicability in unknown interaction scenarios. At the same time, the model often overfits to the context-specific perceptual noise, which leads to insufficient generalization ability and catastrophic forgetting. To address these limitations, we propose a domain-id and exemplar-free incremental learning framework for embodied multimedia systems, which aims to achieve robust continuous environment adaptation. This method designs a disentangled representation mechanism to remove non-essential environmental style interference, and guide the model to focus on extracting semantic intrinsic features shared across scenes, thereby eliminating perceptual uncertainty and improving generalization. We further use the weight fusion strategy to dynamically integrate the old and new environment knowledge in the parameter space, so as to ensure that the model adapts to the new distribution without storing historical data and maximally retains the discrimination ability of the old environment. Extensive experiments on multiple standard benchmark datasets show that the proposed method significantly reduces catastrophic forgetting in a completely exemplar-free and domain-id free setting, and its accuracy is better than the existing state-of-the-art methods.
SplatBright: Generalizable Low-Light Scene Reconstruction from Sparse Views via Physically-Guided Gaussian Enhancement
Dec 21, 2025



Low-light 3D reconstruction from sparse views remains challenging due to exposure imbalance and degraded color fidelity. While existing methods struggle with view inconsistency and require per-scene training, we propose SplatBright, which is, to our knowledge, the first generalizable 3D Gaussian framework for joint low-light enhancement and reconstruction from sparse sRGB inputs. Our key idea is to integrate physically guided illumination modeling with geometry-appearance decoupling for consistent low-light reconstruction. Specifically, we adopt a dual-branch predictor that provides stable geometric initialization of 3D Gaussian parameters. On the appearance side, illumination consistency leverages frequency priors to enable controllable and cross-view coherent lighting, while an appearance refinement module further separates illumination, material, and view-dependent cues to recover fine texture. To tackle the lack of large-scale geometrically consistent paired data, we synthesize dark views via a physics-based camera model for training. Extensive experiments on public and self-collected datasets demonstrate that SplatBright achieves superior novel view synthesis, cross-view consistency, and better generalization to unseen low-light scenes compared with both 2D and 3D methods.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025
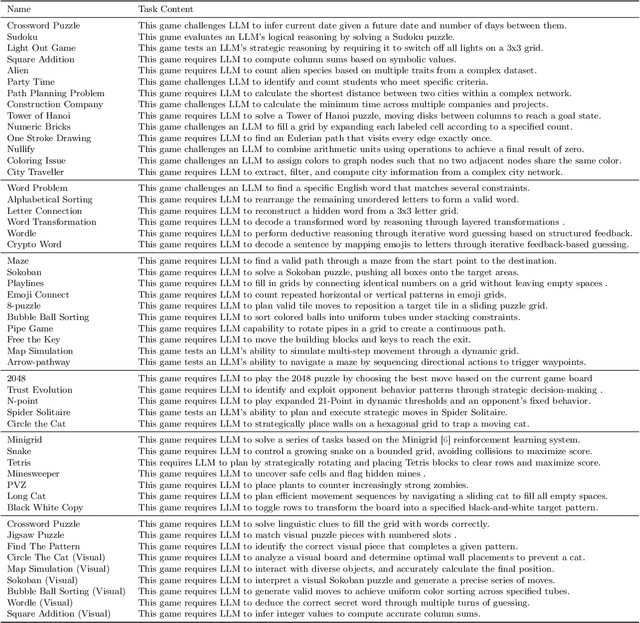
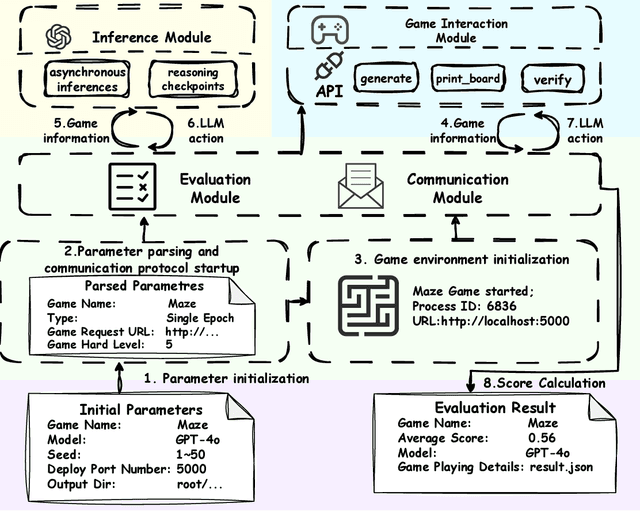

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
FreeDriveRF: Monocular RGB Dynamic NeRF without Poses for Autonomous Driving via Point-Level Dynamic-Static Decoupling
May 14, 2025Dynamic scene reconstruction for autonomous driving enables vehicles to perceive and interpret complex scene changes more precisely. Dynamic Neural Radiance Fields (NeRFs) have recently shown promising capability in scene modeling. However, many existing methods rely heavily on accurate poses inputs and multi-sensor data, leading to increased system complexity. To address this, we propose FreeDriveRF, which reconstructs dynamic driving scenes using only sequential RGB images without requiring poses inputs. We innovatively decouple dynamic and static parts at the early sampling level using semantic supervision, mitigating image blurring and artifacts. To overcome the challenges posed by object motion and occlusion in monocular camera, we introduce a warped ray-guided dynamic object rendering consistency loss, utilizing optical flow to better constrain the dynamic modeling process. Additionally, we incorporate estimated dynamic flow to constrain the pose optimization process, improving the stability and accuracy of unbounded scene reconstruction. Extensive experiments conducted on the KITTI and Waymo datasets demonstrate the superior performance of our method in dynamic scene modeling for autonomous driving.
Adaptive Weighted Parameter Fusion with CLIP for Class-Incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables the model to incrementally absorb knowledge from new classes and build a generic classifier across all previously encountered classes. When the model optimizes with new classes, the knowledge of previous classes is inevitably erased, leading to catastrophic forgetting. Addressing this challenge requires making a trade-off between retaining old knowledge and accommodating new information. However, this balancing process often requires sacrificing some information, which can lead to a partial loss in the model's ability to discriminate between classes. To tackle this issue, we design the adaptive weighted parameter fusion with Contrastive Language-Image Pre-training (CLIP), which not only takes into account the variability of the data distribution of different tasks, but also retains all the effective information of the parameter matrix to the greatest extent. In addition, we introduce a balance factor that can balance the data distribution alignment and distinguishability of adjacent tasks. Experimental results on several traditional benchmarks validate the superiority of the proposed method.
Feature Calibration enhanced Parameter Synthesis for CLIP-based Class-incremental Learning
Mar 25, 2025Class-incremental Learning (CIL) enables models to continuously learn new class knowledge while memorizing previous classes, facilitating their adaptation and evolution in dynamic environments. Traditional CIL methods are mainly based on visual features, which limits their ability to handle complex scenarios. In contrast, Vision-Language Models (VLMs) show promising potential to promote CIL by integrating pretrained knowledge with textual features. However, previous methods make it difficult to overcome catastrophic forgetting while preserving the generalization capabilities of VLMs. To tackle these challenges, we propose Feature Calibration enhanced Parameter Synthesis (FCPS) in this paper. Specifically, our FCPS employs a specific parameter adjustment mechanism to iteratively refine the proportion of original visual features participating in the final class determination, ensuring the model's foundational generalization capabilities. Meanwhile, parameter integration across different tasks achieves a balance between learning new class knowledge and retaining old knowledge. Experimental results on popular benchmarks (e.g., CIFAR100 and ImageNet100) validate the superiority of the proposed method.
CRCL: Causal Representation Consistency Learning for Anomaly Detection in Surveillance Videos
Mar 24, 2025Video Anomaly Detection (VAD) remains a fundamental yet formidable task in the video understanding community, with promising applications in areas such as information forensics and public safety protection. Due to the rarity and diversity of anomalies, existing methods only use easily collected regular events to model the inherent normality of normal spatial-temporal patterns in an unsupervised manner. Previous studies have shown that existing unsupervised VAD models are incapable of label-independent data offsets (e.g., scene changes) in real-world scenarios and may fail to respond to light anomalies due to the overgeneralization of deep neural networks. Inspired by causality learning, we argue that there exist causal factors that can adequately generalize the prototypical patterns of regular events and present significant deviations when anomalous instances occur. In this regard, we propose Causal Representation Consistency Learning (CRCL) to implicitly mine potential scene-robust causal variable in unsupervised video normality learning. Specifically, building on the structural causal models, we propose scene-debiasing learning and causality-inspired normality learning to strip away entangled scene bias in deep representations and learn causal video normality, respectively. Extensive experiments on benchmarks validate the superiority of our method over conventional deep representation learning. Moreover, ablation studies and extension validation show that the CRCL can cope with label-independent biases in multi-scene settings and maintain stable performance with only limited training data available.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
A Survey on Diffusion Models for Anomaly Detection
Jan 20, 2025Diffusion models (DMs) have emerged as a powerful class of generative AI models, showing remarkable potential in anomaly detection (AD) tasks across various domains, such as cybersecurity, fraud detection, healthcare, and manufacturing. The intersection of these two fields, termed diffusion models for anomaly detection (DMAD), offers promising solutions for identifying deviations in increasingly complex and high-dimensional data. In this survey, we systematically review recent advances in DMAD research and investigate their capabilities. We begin by presenting the fundamental concepts of AD and DMs, followed by a comprehensive analysis of classic DM architectures including DDPMs, DDIMs, and Score SDEs. We further categorize existing DMAD methods into reconstruction-based, density-based, and hybrid approaches, providing detailed examinations of their methodological innovations. We also explore the diverse tasks across different data modalities, encompassing image, time series, video, and multimodal data analysis. Furthermore, we discuss critical challenges and emerging research directions, including computational efficiency, model interpretability, robustness enhancement, edge-cloud collaboration, and integration with large language models. The collection of DMAD research papers and resources is available at https://github.com/fdjingliu/DMAD.
DSRC: Learning Density-insensitive and Semantic-aware Collaborative Representation against Corruptions
Dec 14, 2024



As a potential application of Vehicle-to-Everything (V2X) communication, multi-agent collaborative perception has achieved significant success in 3D object detection. While these methods have demonstrated impressive results on standard benchmarks, the robustness of such approaches in the face of complex real-world environments requires additional verification. To bridge this gap, we introduce the first comprehensive benchmark designed to evaluate the robustness of collaborative perception methods in the presence of natural corruptions typical of real-world environments. Furthermore, we propose DSRC, a robustness-enhanced collaborative perception method aiming to learn Density-insensitive and Semantic-aware collaborative Representation against Corruptions. DSRC consists of two key designs: i) a semantic-guided sparse-to-dense distillation framework, which constructs multi-view dense objects painted by ground truth bounding boxes to effectively learn density-insensitive and semantic-aware collaborative representation; ii) a feature-to-point cloud reconstruction approach to better fuse critical collaborative representation across agents. To thoroughly evaluate DSRC, we conduct extensive experiments on real-world and simulated datasets. The results demonstrate that our method outperforms SOTA collaborative perception methods in both clean and corrupted conditions. Code is available at https://github.com/Terry9a/DSRC.