 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning
Jul 16, 2024Existing agents based on large language models (LLMs) demonstrate robust problem-solving capabilities by integrating LLMs' inherent knowledge, strong in-context learning and zero-shot capabilities, and the use of tools combined with intricately designed LLM invocation workflows by humans. However, these agents still exhibit shortcomings in long-term reasoning and under-use the potential of existing tools, leading to noticeable deficiencies in complex real-world reasoning scenarios. To address these limitations, we introduce Sibyl, a simple yet powerful LLM-based agent framework designed to tackle complex reasoning tasks by efficiently leveraging a minimal set of tools. Drawing inspiration from Global Workspace Theory, Sibyl incorporates a global workspace to enhance the management and sharing of knowledge and conversation history throughout the system. Furthermore, guided by Society of Mind Theory, Sibyl implements a multi-agent debate-based jury to self-refine the final answers, ensuring a comprehensive and balanced approach. This approach aims to reduce system complexity while expanding the scope of problems solvable-from matters typically resolved by humans in minutes to those requiring hours or even days, thus facilitating a shift from System-1 to System-2 thinking. Sibyl has been designed with a focus on scalability and ease of debugging by incorporating the concept of reentrancy from functional programming from its inception, with the aim of seamless and low effort integration in other LLM applications to improve capabilities. Our experimental results on the GAIA benchmark test set reveal that the Sibyl agent instantiated with GPT-4 achieves state-of-the-art performance with an average score of 34.55%, compared to other agents based on GPT-4. We hope that Sibyl can inspire more reliable and reusable LLM-based agent solutions to address complex real-world reasoning tasks.
Flooding Spread of Manipulated Knowledge in LLM-Based Multi-Agent Communities
Jul 10, 2024



The rapid adoption of large language models (LLMs) in multi-agent systems has highlighted their impressive capabilities in various applications, such as collaborative problem-solving and autonomous negotiation. However, the security implications of these LLM-based multi-agent systems have not been thoroughly investigated, particularly concerning the spread of manipulated knowledge. In this paper, we investigate this critical issue by constructing a detailed threat model and a comprehensive simulation environment that mirrors real-world multi-agent deployments in a trusted platform. Subsequently, we propose a novel two-stage attack method involving Persuasiveness Injection and Manipulated Knowledge Injection to systematically explore the potential for manipulated knowledge (i.e., counterfactual and toxic knowledge) spread without explicit prompt manipulation. Our method leverages the inherent vulnerabilities of LLMs in handling world knowledge, which can be exploited by attackers to unconsciously spread fabricated information. Through extensive experiments, we demonstrate that our attack method can successfully induce LLM-based agents to spread both counterfactual and toxic knowledge without degrading their foundational capabilities during agent communication. Furthermore, we show that these manipulations can persist through popular retrieval-augmented generation frameworks, where several benign agents store and retrieve manipulated chat histories for future interactions. This persistence indicates that even after the interaction has ended, the benign agents may continue to be influenced by manipulated knowledge. Our findings reveal significant security risks in LLM-based multi-agent systems, emphasizing the imperative need for robust defenses against manipulated knowledge spread, such as introducing ``guardian'' agents and advanced fact-checking tools.
SPO: Multi-Dimensional Preference Sequential Alignment With Implicit Reward Modeling
May 21, 2024



Human preference alignment is critical in building powerful and reliable large language models (LLMs). However, current methods either ignore the multi-dimensionality of human preferences (e.g. helpfulness and harmlessness) or struggle with the complexity of managing multiple reward models. To address these issues, we propose Sequential Preference Optimization (SPO), a method that sequentially fine-tunes LLMs to align with multiple dimensions of human preferences. SPO avoids explicit reward modeling, directly optimizing the models to align with nuanced human preferences. We theoretically derive closed-form optimal SPO policy and loss function. Gradient analysis is conducted to show how SPO manages to fine-tune the LLMs while maintaining alignment on previously optimized dimensions. Empirical results on LLMs of different size and multiple evaluation datasets demonstrate that SPO successfully aligns LLMs across multiple dimensions of human preferences and significantly outperforms the baselines.
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
Apr 09, 2024

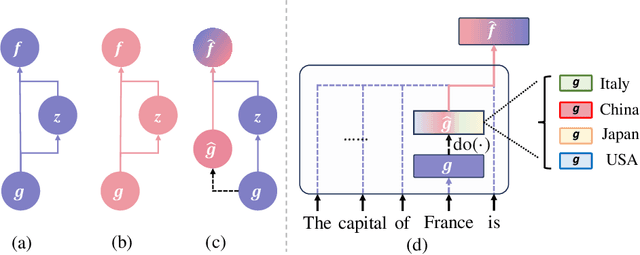

In this paper, we deeply explore the mechanisms employed by Transformer-based language models in factual recall tasks. In zero-shot scenarios, given a prompt like "The capital of France is," task-specific attention heads extract the topic entity, such as "France," from the context and pass it to subsequent MLPs to recall the required answer such as "Paris." We introduce a novel analysis method aimed at decomposing the outputs of the MLP into components understandable by humans. Through this method, we quantify the function of the MLP layer following these task-specific heads. In the residual stream, it either erases or amplifies the information originating from individual heads. Moreover, it generates a component that redirects the residual stream towards the direction of its expected answer. These zero-shot mechanisms are also employed in few-shot scenarios. Additionally, we observed a widely existent anti-overconfidence mechanism in the final layer of models, which suppresses correct predictions. We mitigate this suppression by leveraging our interpretation to improve factual recall performance. Our interpretations have been evaluated across various language models, from the GPT-2 families to 1.3B OPT, and across tasks covering different domains of factual knowledge.
Is it Possible to Edit Large Language Models Robustly?
Feb 08, 2024Large language models (LLMs) have played a pivotal role in building communicative AI to imitate human behaviors but face the challenge of efficient customization. To tackle this challenge, recent studies have delved into the realm of model editing, which manipulates specific memories of language models and changes the related language generation. However, the robustness of model editing remains an open question. This work seeks to understand the strengths and limitations of editing methods, thus facilitating robust, realistic applications of communicative AI. Concretely, we conduct extensive analysis to address the three key research questions. Q1: Can edited LLMs behave consistently resembling communicative AI in realistic situations? Q2: To what extent does the rephrasing of prompts lead LLMs to deviate from the edited knowledge memory? Q3: Which knowledge features are correlated with the performance and robustness of editing? Our experimental results uncover a substantial disparity between existing editing methods and the practical application of LLMs. On rephrased prompts that are complex and flexible but common in realistic applications, the performance of editing experiences a significant decline. Further analysis shows that more popular knowledge is memorized better, easier to recall, and more challenging to edit effectively.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
Knowledge-Guided Exploration in Deep Reinforcement Learning
Oct 26, 2022



This paper proposes a new method to drastically speed up deep reinforcement learning (deep RL) training for problems that have the property of state-action permissibility (SAP). Two types of permissibility are defined under SAP. The first type says that after an action $a_t$ is performed in a state $s_t$ and the agent has reached the new state $s_{t+1}$, the agent can decide whether $a_t$ is permissible or not permissible in $s_t$. The second type says that even without performing $a_t$ in $s_t$, the agent can already decide whether $a_t$ is permissible or not in $s_t$. An action is not permissible in a state if the action can never lead to an optimal solution and thus should not be tried (over and over again). We incorporate the proposed SAP property and encode action permissibility knowledge into two state-of-the-art deep RL algorithms to guide their state-action exploration together with a virtual stopping strategy. Results show that the SAP-based guidance can markedly speed up RL training.
Evaluation Framework For Large-scale Federated Learning
Mar 12, 2020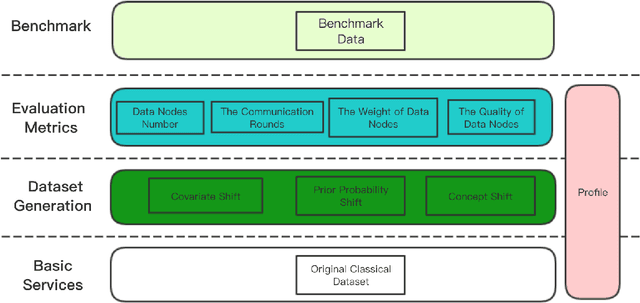
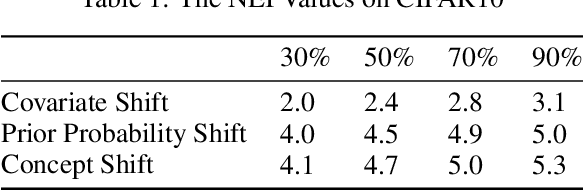
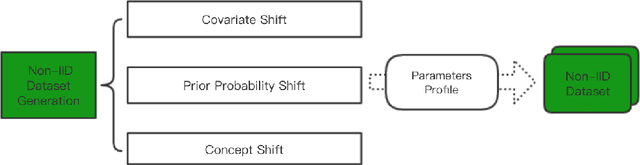
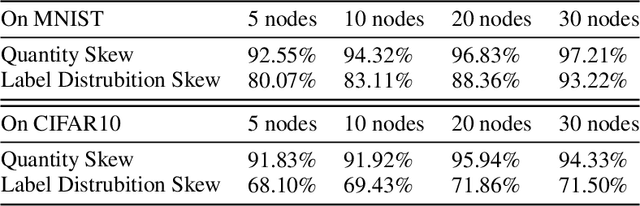
Federated learning is proposed as a machine learning setting to enable distributed edge devices, such as mobile phones, to collaboratively learn a shared prediction model while keeping all the training data on device, which can not only take full advantage of data distributed across millions of nodes to train a good model but also protect data privacy. However, learning in scenario above poses new challenges. In fact, data across a massive number of unreliable devices is likely to be non-IID (identically and independently distributed), which may make the performance of models trained by federated learning unstable. In this paper, we introduce a framework designed for large-scale federated learning which consists of approaches to generating dataset and modular evaluation framework. Firstly, we construct a suite of open-source non-IID datasets by providing three respects including covariate shift, prior probability shift, and concept shift, which are grounded in real-world assumptions. In addition, we design several rigorous evaluation metrics including the number of network nodes, the size of datasets, the number of communication rounds and communication resources etc. Finally, we present an open-source benchmark for large-scale federated learning research.