 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoherent Loss: A Generic Framework for Stable Video Segmentation
Oct 25, 2020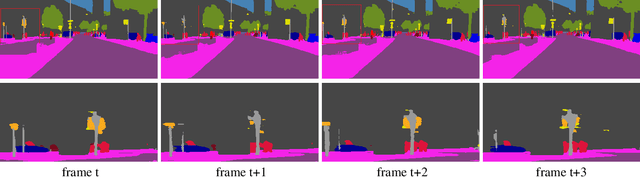

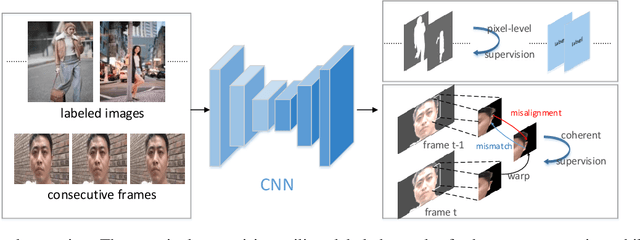
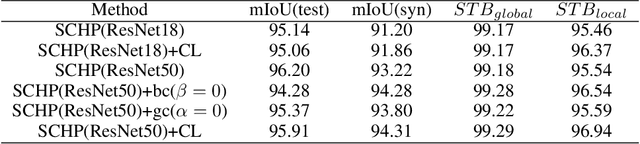
Video segmentation approaches are of great importance for numerous vision tasks especially in video manipulation for entertainment. Due to the challenges associated with acquiring high-quality per-frame segmentation annotations and large video datasets with different environments at scale, learning approaches shows overall higher accuracy on test dataset but lack strict temporal constraints to self-correct jittering artifacts in most practical applications. We investigate how this jittering artifact degrades the visual quality of video segmentation results and proposed a metric of temporal stability to numerically evaluate it. In particular, we propose a Coherent Loss with a generic framework to enhance the performance of a neural network against jittering artifacts, which combines with high accuracy and high consistency. Equipped with our method, existing video object/semantic segmentation approaches achieve a significant improvement in term of more satisfactory visual quality on video human dataset, which we provide for further research in this field, and also on DAVIS and Cityscape.
Discriminative Sounding Objects Localization via Self-supervised Audiovisual Matching
Oct 12, 2020
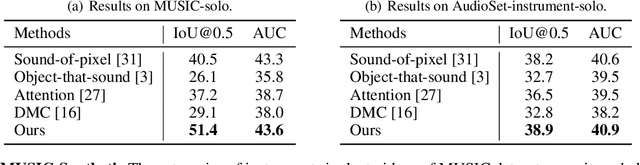
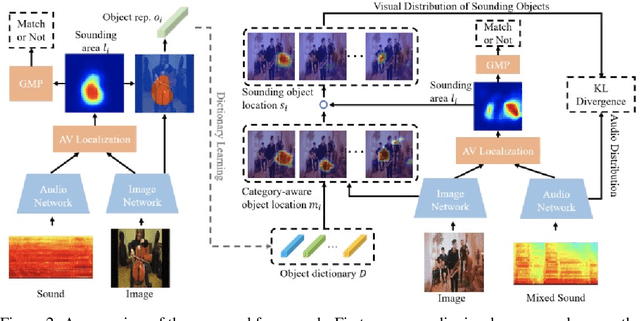
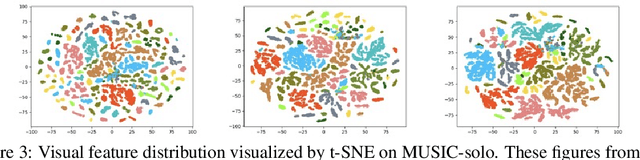
Discriminatively localizing sounding objects in cocktail-party, i.e., mixed sound scenes, is commonplace for humans, but still challenging for machines. In this paper, we propose a two-stage learning framework to perform self-supervised class-aware sounding object localization. First, we propose to learn robust object representations by aggregating the candidate sound localization results in the single source scenes. Then, class-aware object localization maps are generated in the cocktail-party scenarios by referring the pre-learned object knowledge, and the sounding objects are accordingly selected by matching audio and visual object category distributions, where the audiovisual consistency is viewed as the self-supervised signal. Experimental results in both realistic and synthesized cocktail-party videos demonstrate that our model is superior in filtering out silent objects and pointing out the location of sounding objects of different classes. Code is available at https://github.com/DTaoo/Discriminative-Sounding-Objects-Localization.
PP-YOLO: An Effective and Efficient Implementation of Object Detector
Aug 03, 2020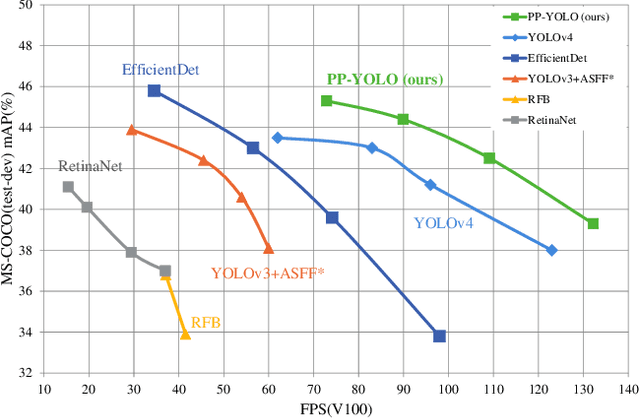
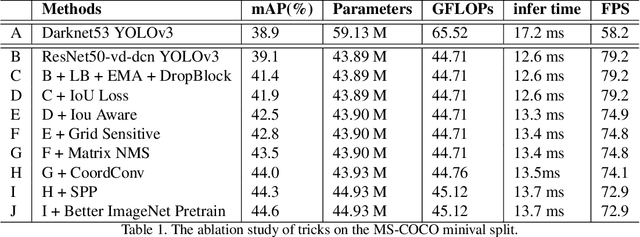
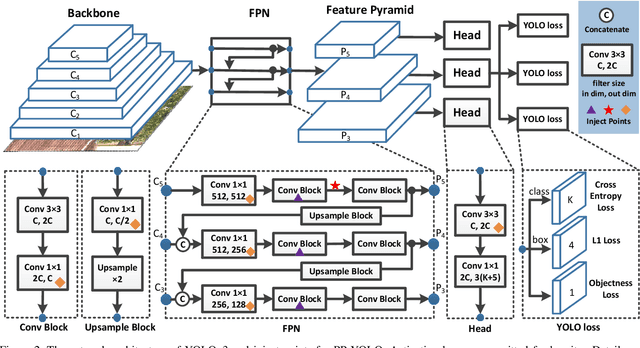
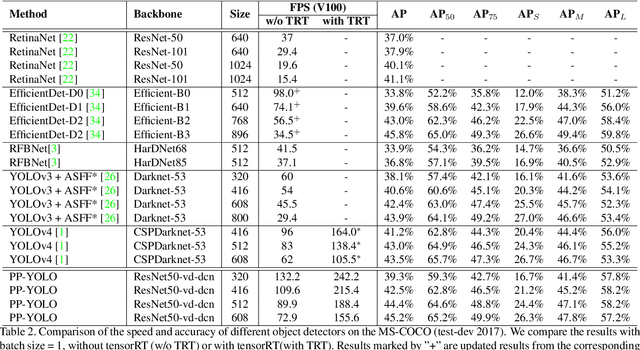
Object detection is one of the most important areas in computer vision, which plays a key role in various practical scenarios. Due to limitation of hardware, it is often necessary to sacrifice accuracy to ensure the infer speed of the detector in practice. Therefore, the balance between effectiveness and efficiency of object detector must be considered. The goal of this paper is to implement an object detector with relatively balanced effectiveness and efficiency that can be directly applied in actual application scenarios, rather than propose a novel detection model. Considering that YOLOv3 has been widely used in practice, we develop a new object detector based on YOLOv3. We mainly try to combine various existing tricks that almost not increase the number of model parameters and FLOPs, to achieve the goal of improving the accuracy of detector as much as possible while ensuring that the speed is almost unchanged. Since all experiments in this paper are conducted based on PaddlePaddle, we call it PP-YOLO. By combining multiple tricks, PP-YOLO can achieve a better balance between effectiveness (45.2% mAP) and efficiency (72.9 FPS), surpassing the existing state-of-the-art detectors such as EfficientDet and YOLOv4.Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Graph-PCNN: Two Stage Human Pose Estimation with Graph Pose Refinement
Jul 21, 2020
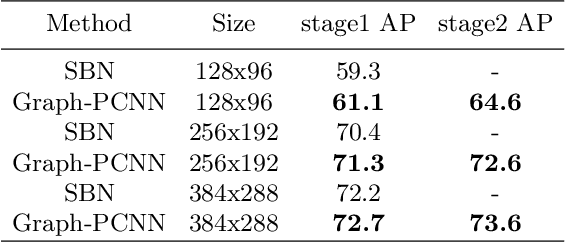
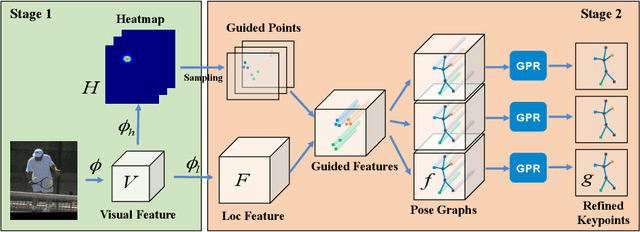
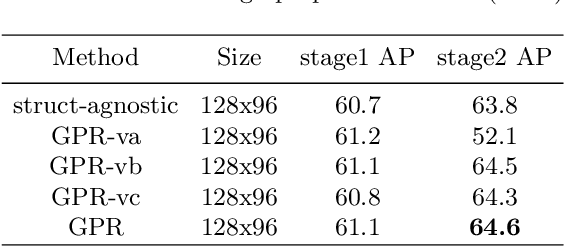
Recently, most of the state-of-the-art human pose estimation methods are based on heatmap regression. The final coordinates of keypoints are obtained by decoding heatmap directly. In this paper, we aim to find a better approach to get more accurate localization results. We mainly put forward two suggestions for improvement: 1) different features and methods should be applied for rough and accurate localization, 2) relationship between keypoints should be considered. Specifically, we propose a two-stage graph-based and model-agnostic framework, called Graph-PCNN, with a localization subnet and a graph pose refinement module added onto the original heatmap regression network. In the first stage, heatmap regression network is applied to obtain a rough localization result, and a set of proposal keypoints, called guided points, are sampled. In the second stage, for each guided point, different visual feature is extracted by the localization subnet. The relationship between guided points is explored by the graph pose refinement module to get more accurate localization results. Experiments show that Graph-PCNN can be used in various backbones to boost the performance by a large margin. Without bells and whistles, our best model can achieve a new state-of-the-art 76.8% AP on COCO test-dev split.
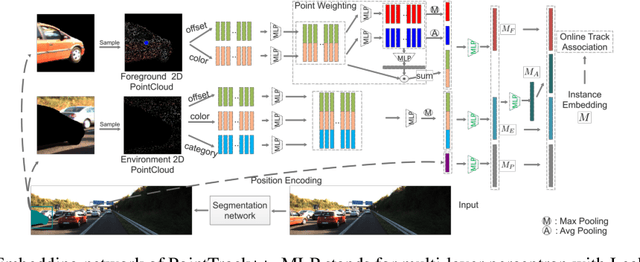
Segment as Points for Efficient Online Multi-Object Tracking and Segmentation
Jul 03, 2020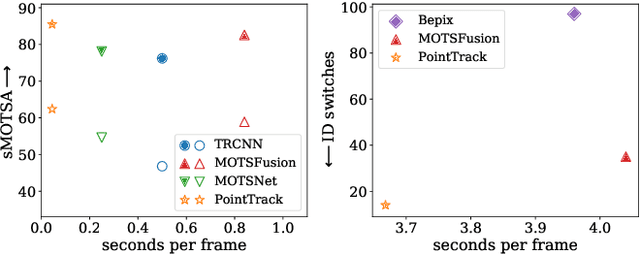

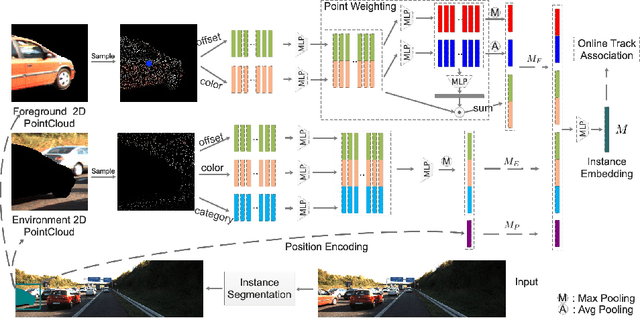
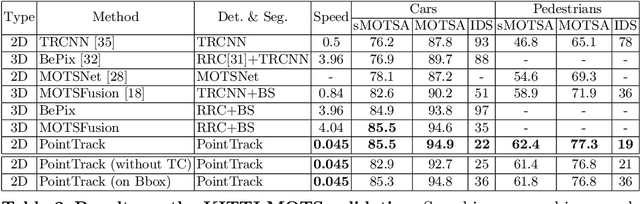
Current multi-object tracking and segmentation (MOTS) methods follow the tracking-by-detection paradigm and adopt convolutions for feature extraction. However, as affected by the inherent receptive field, convolution based feature extraction inevitably mixes up the foreground features and the background features, resulting in ambiguities in the subsequent instance association. In this paper, we propose a highly effective method for learning instance embeddings based on segments by converting the compact image representation to un-ordered 2D point cloud representation. Our method generates a new tracking-by-points paradigm where discriminative instance embeddings are learned from randomly selected points rather than images. Furthermore, multiple informative data modalities are converted into point-wise representations to enrich point-wise features. The resulting online MOTS framework, named PointTrack, surpasses all the state-of-the-art methods including 3D tracking methods by large margins (5.4% higher MOTSA and 18 times faster over MOTSFusion) with the near real-time speed (22 FPS). Evaluations across three datasets demonstrate both the effectiveness and efficiency of our method. Moreover, based on the observation that current MOTS datasets lack crowded scenes, we build a more challenging MOTS dataset named APOLLO MOTS with higher instance density. Both APOLLO MOTS and our codes are publicly available at https://github.com/detectRecog/PointTrack.
PointTrack++ for Effective Online Multi-Object Tracking and Segmentation
Jul 03, 2020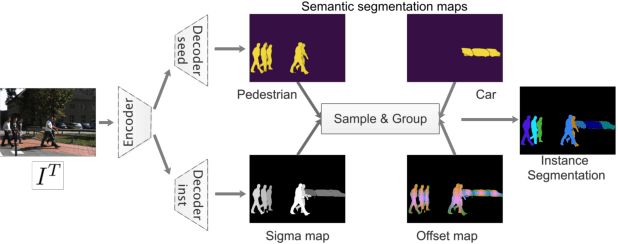
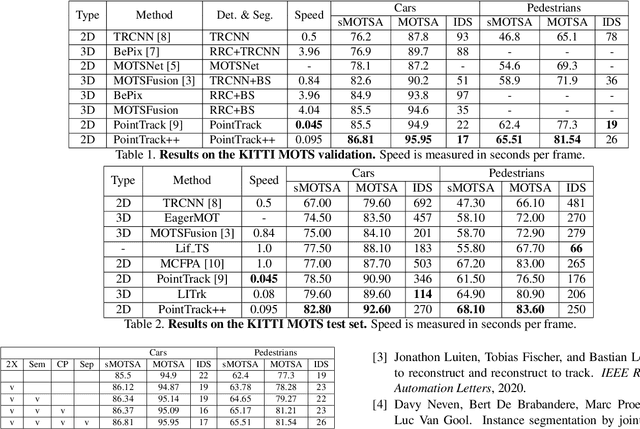
Multiple-object tracking and segmentation (MOTS) is a novel computer vision task that aims to jointly perform multiple object tracking (MOT) and instance segmentation. In this work, we present PointTrack++, an effective on-line framework for MOTS, which remarkably extends our recently proposed PointTrack framework. To begin with, PointTrack adopts an efficient one-stage framework for instance segmentation, and learns instance embeddings by converting compact image representations to un-ordered 2D point cloud. Compared with PointTrack, our proposed PointTrack++ offers three major improvements. Firstly, in the instance segmentation stage, we adopt a semantic segmentation decoder trained with focal loss to improve the instance selection quality. Secondly, to further boost the segmentation performance, we propose a data augmentation strategy by copy-and-paste instances into training images. Finally, we introduce a better training strategy in the instance association stage to improve the distinguishability of learned instance embeddings. The resulting framework achieves the state-of-the-art performance on the 5th BMTT MOTChallenge.
Associate-3Ddet: Perceptual-to-Conceptual Association for 3D Point Cloud Object Detection
Jun 08, 2020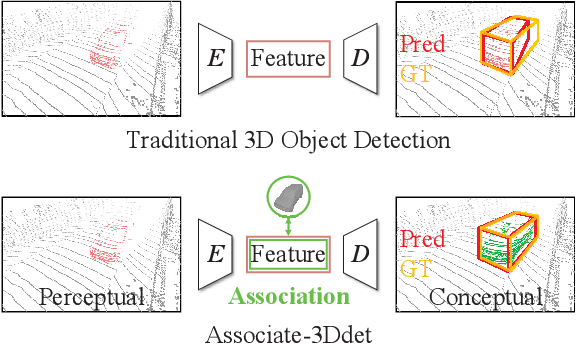
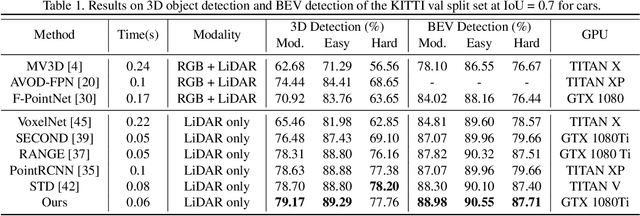
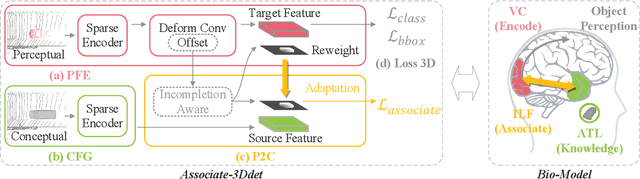
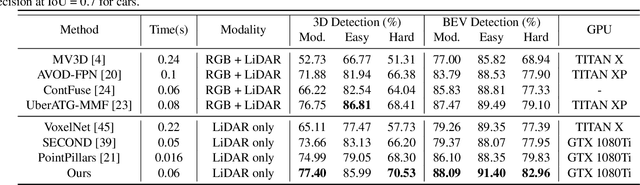
Object detection from 3D point clouds remains a challenging task, though recent studies pushed the envelope with the deep learning techniques. Owing to the severe spatial occlusion and inherent variance of point density with the distance to sensors, appearance of a same object varies a lot in point cloud data. Designing robust feature representation against such appearance changes is hence the key issue in a 3D object detection method. In this paper, we innovatively propose a domain adaptation like approach to enhance the robustness of the feature representation. More specifically, we bridge the gap between the perceptual domain where the feature comes from a real scene and the conceptual domain where the feature is extracted from an augmented scene consisting of non-occlusion point cloud rich of detailed information. This domain adaptation approach mimics the functionality of the human brain when proceeding object perception. Extensive experiments demonstrate that our simple yet effective approach fundamentally boosts the performance of 3D point cloud object detection and achieves the state-of-the-art results.
NTIRE 2020 Challenge on Video Quality Mapping: Methods and Results
May 06, 2020

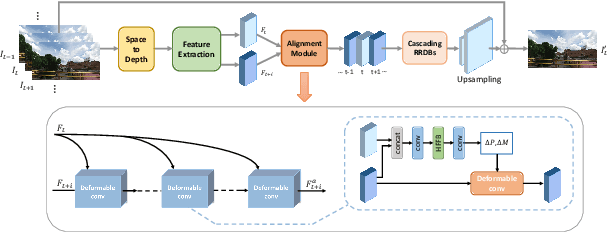
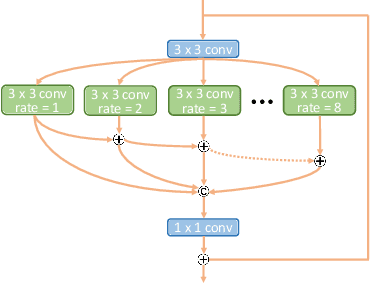
This paper reviews the NTIRE 2020 challenge on video quality mapping (VQM), which addresses the issues of quality mapping from source video domain to target video domain. The challenge includes both a supervised track (track 1) and a weakly-supervised track (track 2) for two benchmark datasets. In particular, track 1 offers a new Internet video benchmark, requiring algorithms to learn the map from more compressed videos to less compressed videos in a supervised training manner. In track 2, algorithms are required to learn the quality mapping from one device to another when their quality varies substantially and weakly-aligned video pairs are available. For track 1, in total 7 teams competed in the final test phase, demonstrating novel and effective solutions to the problem. For track 2, some existing methods are evaluated, showing promising solutions to the weakly-supervised video quality mapping problem.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
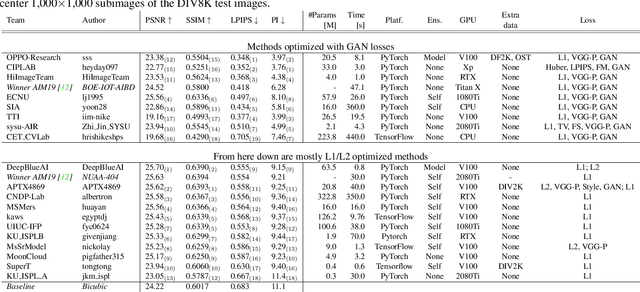

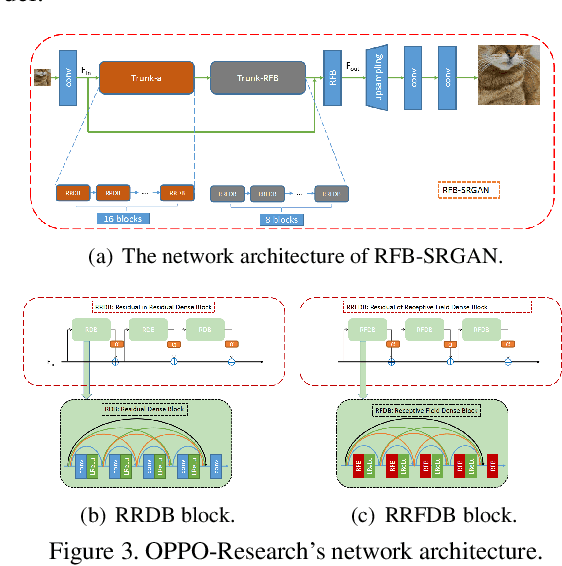
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
ZoomNet: Part-Aware Adaptive Zooming Neural Network for 3D Object Detection
Mar 01, 2020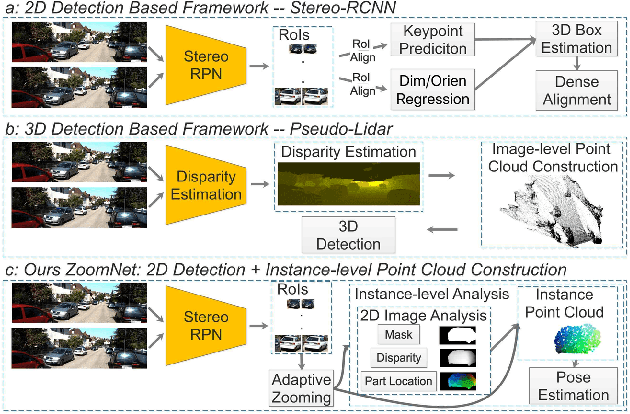
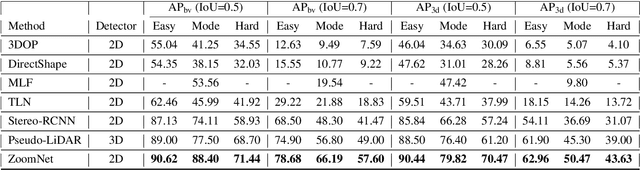
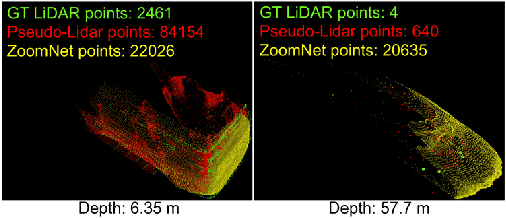
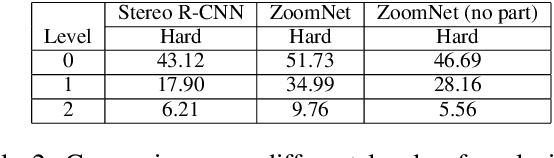
3D object detection is an essential task in autonomous driving and robotics. Though great progress has been made, challenges remain in estimating 3D pose for distant and occluded objects. In this paper, we present a novel framework named ZoomNet for stereo imagery-based 3D detection. The pipeline of ZoomNet begins with an ordinary 2D object detection model which is used to obtain pairs of left-right bounding boxes. To further exploit the abundant texture cues in RGB images for more accurate disparity estimation, we introduce a conceptually straight-forward module -- adaptive zooming, which simultaneously resizes 2D instance bounding boxes to a unified resolution and adjusts the camera intrinsic parameters accordingly. In this way, we are able to estimate higher-quality disparity maps from the resized box images then construct dense point clouds for both nearby and distant objects. Moreover, we introduce to learn part locations as complementary features to improve the resistance against occlusion and put forward the 3D fitting score to better estimate the 3D detection quality. Extensive experiments on the popular KITTI 3D detection dataset indicate ZoomNet surpasses all previous state-of-the-art methods by large margins (improved by 9.4% on APbv (IoU=0.7) over pseudo-LiDAR). Ablation study also demonstrates that our adaptive zooming strategy brings an improvement of over 10% on AP3d (IoU=0.7). In addition, since the official KITTI benchmark lacks fine-grained annotations like pixel-wise part locations, we also present our KFG dataset by augmenting KITTI with detailed instance-wise annotations including pixel-wise part location, pixel-wise disparity, etc.. Both the KFG dataset and our codes will be publicly available at https://github.com/detectRecog/ZoomNet.